Code
# imports
import numpy as np
import seaborn as sns
import pandas as pdThis note is not really about searching and sorting, although we will certainly learn to search, and to sort.
This note is about computational complexity.
# imports
import numpy as np
import seaborn as sns
import pandas as pdLet’s write a function to find the position (the index) of an integer within a list of integers:
Using the interpreter, we can run it on a few examples and validate that it performs the functionality that we wish:
find_int([1, 3, 4, 5], 4)2find_int([1, 3, 4, 5], 7)False
Let’s change the function now, to count the number of comparisons necessary to find the position of the integer:
Now, we’ll run it on many inputs:
num_comparisons = []
n_vals = []
for n in range(10,200):
L = [1]
for _ in range(n):
L.append(L[-1] + np.random.randint(1,10))
comparisons = []
for _ in range(200):
search_val = np.random.choice(L)
comparisons.append(find_int(L, search_val))
num_comparisons.append(np.mean(comparisons))
n_vals.append(n)Let’s plot the results, looking at how many comparisons were necessary, as compared to the length of the list:
sns.lineplot(x = n_vals, y = num_comparisons)
Plotting in this note is accomplished using the seaborn library. You don’t need to know too many details about how seaborn works, but the documentation is very helpful, and it allows for much more expressive plotting than spreadsheet tools such as Microsoft Excel or Google Sheets.
The number of comparisons grows linearly with the number of elements in the list. If the number of elements in the list doubles, we expect the number of comparisons needed to double!
Can we do a better job searching through this list? Yes. How?
Let’s look at how our search progresses through a series of sorted integers. In the image below, our search function is looking for the integer 17.

A more efficient search takes advantage of the fact that our list is sorted:

This search is called a binary search.
This is an extremely important result. We can code and graph the results.
First, we’ll write a binary search:
Then, we’ll run the computational experiment using the binary search
num_comparisons_binary = []
n_vals = []
for n in range(10,200):
L = [1]
for _ in range(n):
L.append(L[-1] + np.random.randint(1,10))
comparisons = []
for _ in range(200):
search_val = np.random.choice(L)
comparisons.append(find_binary(L, search_val))
num_comparisons_binary.append(np.mean(comparisons))
n_vals.append(n)Finally, we’ll plot the results:
df_plot = pd.DataFrame()
df_plot["Sequential"] = pd.Series(num_comparisons)
df_plot["Binary"] = pd.Series(num_comparisons_binary)
df_plot["N"] = pd.Series(n_vals)
df_plot["Comparisons"] = pd.Series(np.ones(len(n_vals)))
df_plot = pd.melt(df_plot, id_vars="N", value_vars=["Sequential", "Binary"],
var_name='Comparison Type', value_name="# Comparisons")
sns.lineplot(data=df_plot, x="N", y="# Comparisons", hue="Comparison Type")
We see as \(n\) (the size of the list) increases, the number of comparisons required for binary search grows much more slowly than the number of comparisons required for linear search.
Remember: binary search is faster on sorted lists. Not all lists are sorted, and sorting the list will take additional comparisons!
We performed a computational experiment to examine the run times of the different searches, but we can examine the run times of these searches analytically.
The linear search is straightforward: assuming that the element we are searching for is equally likely to be at any position in the list, the average number of comparisons is the length of the list divided by two. We confirmed this result with our experiment.
The binary search is more complicated: doubling the length of the list increases the number of comparisons by one. Exponential growth in the length of the list results in linear growth in the number of comparisons: therefore, linear growth in the length of the list results in logarithmic growth in the number of comparisons:
Take care to remember that we are talking about the order of growth: the binary search actually has two comparisons per halving.
In these analysis, we use “big O” notation to describe the complexity of algorithm runtime:
This refers to the order of growth of the number of operations as the size of the problem grows. Big O notation is approximate, and in this case, refers to an average runtime for these algorithms. There are certain cases where linear search is faster than binary search: if the element we are looking for is the first element, linear search will find it with one comparison!
When searching for an item in a list, we compare items in the list to some fixed value (the search target).
When sorting a list, we compare items in the list to each other. This should give us an intuition that sorting a list will take longer than searching through a list (indeed, searching is a sub-task of sorting algorithms).
We’ll start looking at sorting with the bubble sort algorithm that you implemented earlier. The example below sorts a list in place.
def bubble_sort(L):
sort_finished = False
while not sort_finished:
sort_finished = True
for k in range(len(L)-1):
if L[k] > L[k+1]:
sort_finished = False
temp = L[k]
L[k] = L[k+1]
L[k+1] = tempHow it works (sorting smallest to largest):
Illustrated:

The inefficiency of the algorithm is illuminated: swapping only moves any element in the list one position at a time. If the smallest element in the list starts as the last element, it must be swapped \(n-1\) times before it is in the correct position!
We can examine the runtime of the algorithm in terms of comparisons and swaps:
How many comparisons do we need in total?
How many swaps do we need in total?
We can plot how much faster \(O(n^2)\) grows than \(O(n)\) and \(O(\log n)\):
n = 21
df_plot = pd.DataFrame()
df_plot["N"] = pd.Series(list(range(1,n)))
df_plot["Log"] = pd.Series([np.log(i) for i in range(1,n)])
df_plot["Linear"] = pd.Series(list(range(1,n)))
df_plot["Quadratic"] = pd.Series([i**2 for i in range(1,n)])
df_plot["Comparisons"] = pd.Series(np.ones(n-1))
df_plot = pd.melt(df_plot, id_vars="N", value_vars=["Log", "Linear", "Quadratic"],
var_name='Comparison Type', value_name="# Comparisons")
sns.lineplot(data=df_plot, x="N", y="# Comparisons", hue="Comparison Type")
Let’s consider a real use case for a sorted list: our list-based priority queue:
A naïve implementation of this queue would append the new element, and then bubble sort the queue. You should not actually do this. Why not?
Contrast this with a simple insertion:
Priority queues are, in practice, implemented with a data structure known as a heap. The data structure is somewhat more complicated, but yields even better performance:
We are deliberately working through different implementations of the priority queue to demonstrate how changes in algorithmic implementation of a solution can change runtime efficiency.
The insertion sort algorithm works off of this principle: it is straightforward to insert a single new element into a sorted list, resulting in a new sorted list. An unsorted list is used to build a sorted list in place by finding the correct position for the new element and swapping until the element is in position. A “sorted” and “unsorted” portion of the list are maintained, until the entire list is sorted.
def insertion_sort(L):
for i in range(len(L)):
print(L[i])
j = i
while L[j-1] > L[j] and j > 0:
L[j-1], L[j] = L[j], L[j-1]
j -= 1for loop visits each element in the original list (left to right)while loop the compares and swaps this element to right-to-left

for loop)If, however, the initial list is sorted (or “close” to being sorted), performance is much nearer \(n\) comparisons and \(n\) swaps.
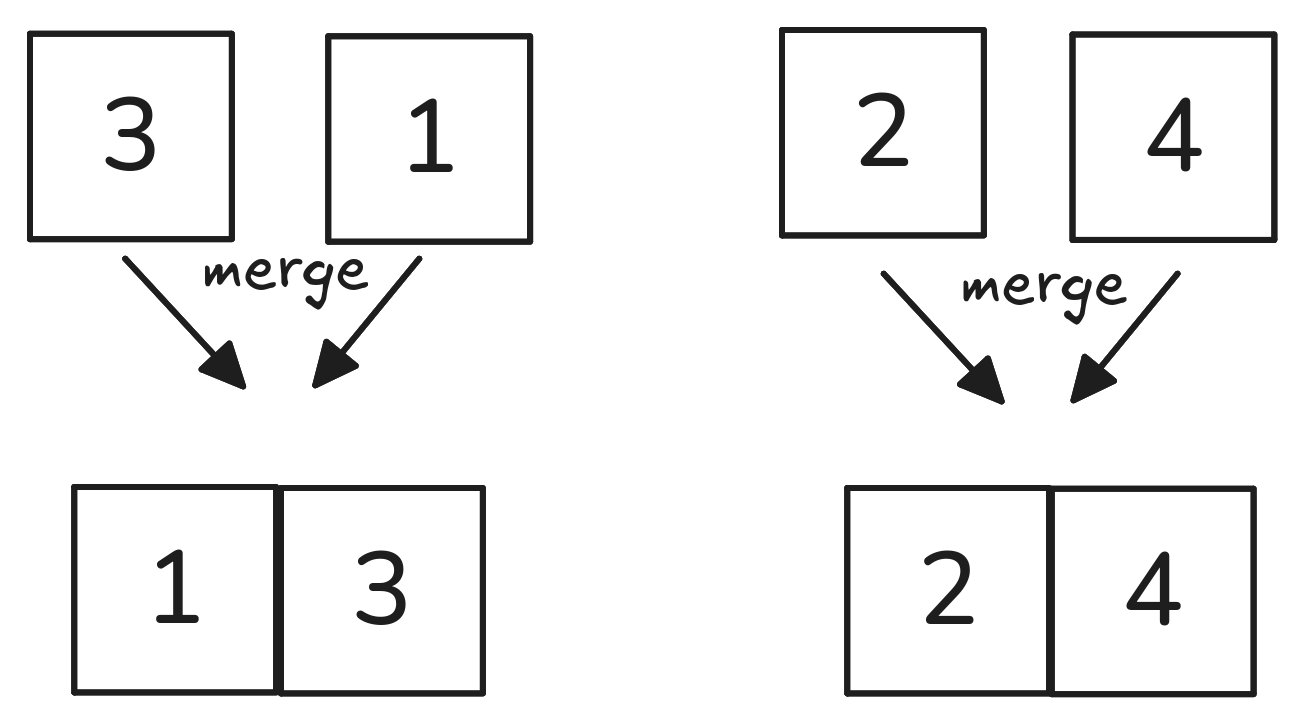
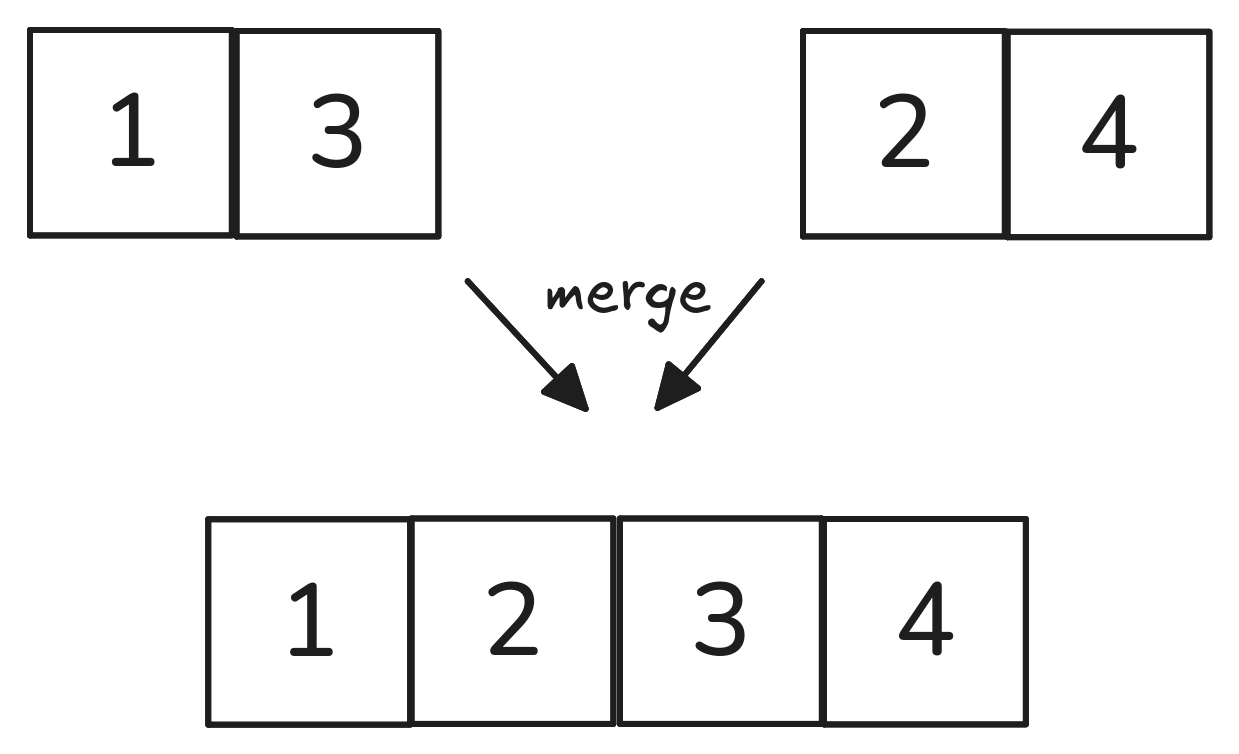
The basic “building block” of the more efficient merge sort algorithm is a function to merge two sorted lists into a new sorted list.
“Merge” runs in two parts:
Visualized:

In Python:
How many comparisons did it take to merge the two lists? The number of elements in the two lists, combined.
Now that we can efficiently merge two lists, we can run the merge sort algorithm.
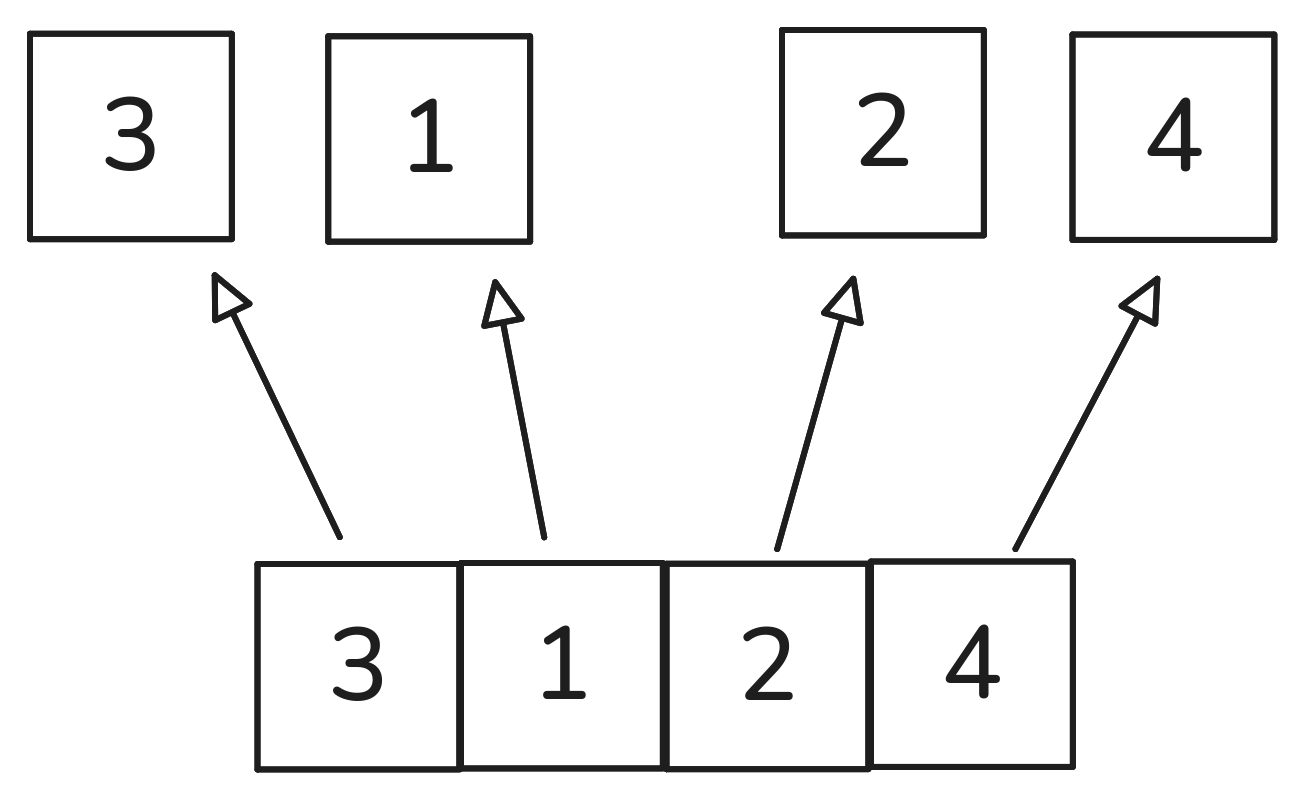
In Python:
def merge_sort(L):
sub_lists = []
for l in L:
sub_lists.append([l])
new_sub_lists = []
while len(new_sub_lists) != 1:
new_sub_lists = []
i = 0
while i < len(sub_lists)-1:
new_sub_lists.append(merge_lists(sub_lists[i], sub_lists[i+1]))
i += 2
if i == len(sub_lists)-1: #account for odd number of sub-lists
new_sub_lists.append(sub_lists[-1])
sub_lists = new_sub_lists
return new_sub_lists[0]Let’s look at the complexity of the sort for an input list of length \(n\):
n = 21
df_plot = pd.DataFrame()
df_plot["N"] = pd.Series(list(range(1,n)))
df_plot["Log"] = pd.Series([np.log(i) for i in range(1,n)])
df_plot["Linear"] = pd.Series(list(range(1,n)))
df_plot["Loglinear"] = pd.Series([i*np.log(n) for i in range(1,n)])
df_plot["Quadratic"] = pd.Series([i**2 for i in range(1,n)])
df_plot["Comparisons"] = pd.Series(np.ones(n-1))
df_plot = pd.melt(df_plot, id_vars="N", value_vars=["Log", "Linear", "Loglinear", "Quadratic"],
var_name='Comparison Type', value_name="# Comparisons")
sns.lineplot(data=df_plot, x="N", y="# Comparisons", hue="Comparison Type")
Homework problems should always be your individual work. Please review the collaboration policy and ask the course staff if you have questions. Remember: Put comments at the start of each problem to tell us how you worked on it.
Double check your file names and return values. These need to be exact matches for you to get credit.
For this homework, don’t use any built-in functions that find maximum, find minimum, or sort.
These problems are intended to be completed in sequence. Each builds on the previous.