Read: json
Files
Reading from and writing to text files allows us to easily process large amounts of data with Python.
Download metamorphosis.txt. It is an excerpt from Franz Kafka’s Metamorphosis.
You can open the file using this syntax. It will read in the file as a single string.
with open('metamorphosis.txt', 'r') as in_file:
lines = in_file.read()
print(type(lines))
print(lines)
Using the filename by itself as the first argument to open only works if the file is in the same directory as the .py file you are running.
Otherwise, you need to include the full file path.
Try making a new directory called text_files inside of where the .py file is and opening the file:
with open('text_files/metamorphosis.txt', 'r') as in_file:
lines = in_file.read()
Because the file is read in as a single string, it includes the special “newline” character '\n', which creates a new line (similar to hitting the Enter or Return key on your keyboard).
You can turn this long string into a list of shorter strings, split by the newline characters, using <str>.split.
line_list = lines.split("\n")
Some examples of how this works:
Writing to a file is very similar
s = "some content to write to a file"
with open('output_file.txt', 'w') as out_file:
print(s, file=out_file)
- The second argument of open is
'w' for “writing”
- To read, we used
'r' for “reading”
- We use the
print function with a keyword argument file=
- Python “prints” the output to a file instead of the console
You should be able to open output_file.txt and read it with a text editor.
Be careful! When you write to a file with Python, you will overwrite any pre-existing file.
JSON
JavaScript Object Notation (“JSON”) is an industry-standard format for passing data between computer programs. It is similar to a Python dictionary, in that it consists of objects, which consist of pairs of names (keys) and values.
- A JSON object is very similar to a Python dict
{"Hello": 1, "World": 2, "Names (Keys) Must Be Strings": 3}
Whitespace is ignored in JSON (just like Python!) and JSON is commonly indented for readability:
{
"Hello": 1,
"World": 2,
"Names (Keys) Must Be Strings": 3
}
Names must be strings, and unlike Python, strings are always delimited with double quotes ("). The values of an object can themselves be objects.
{
"First Outer Name": 1,
"Second Outer Name":
{
"First Inner Name": 101,
"Second Inner Name": 102
},
"Third Outer Name": 3
}
- Values can take on several types:
- Strings
- Numbers (JSON does not distinguish between ints and floats)
- Bools (
true and false – all lowercase, different from Python)
null – similar to Python’s None, indicating “nothing”- Arrays
- Objects
- A JSON array is very similar to a Python list. The example below has arrays as values:
{
"DC": [20052, 20051],
"VA": [22101, 22102]
}
- Arrays can contain any kind of value, including other arrays, and other objects:
{
"First": ["A", "B", [1, 2, 3]],
"Second": [
true,
null,
{
"Inner Name": false,
"Second Inner Name": "Yes"
},
"Thank you",
[5, 6]
],
"Third": 1.5
}
The example above is unnecessarily complicated to show what JSON can do. In practice, JSON is usually formatted logically (it’s a data interchange format, after all). For further reading about JSON formatting, read about JSON Schema.
JSON in Python
Python has a built-in library for working with JSON: json. The json.loads function takes a string representing the contest of a JSON file, and converts it to a Python dictionary.
import json
with open("example2.json", "r") as f:
contents = f.read()
print("Raw String:\n" + contents) # the raw string
json_contents = json.loads(contents)
print("Parsed JSON:\n" + str(json_contents)) # parsed into a Python dict
Raw String:
{
"DC": [20052, 20051],
"VA": [22101, 22102]
}
Parsed JSON:
{'DC': [20052, 20051], 'VA': [22101, 22102]}
We can also take a Python dict and parse it into valid JSON using json.dumps
D = {}
D["number"] = 12
D["bool"] = True
D["nothing"] = None
D["list"] = [4, "A"]
D[6] = 7
D[1.1] = 1
print("Original dict:\n", D)
json_out = json.dumps(D)
print("JSON:\n", json_out)
# "pretty print" indented JSON
pretty_json_out = json.dumps(D, indent=4)
print("Pretty JSON:\n", pretty_json_out)
Original dict:
{'number': 12, 'bool': True, 'nothing': None, 'list': [4, 'A'], 6: 7, 1.1: 1}
JSON:
{"number": 12, "bool": true, "nothing": null, "list": [4, "A"], "6": 7, "1.1": 1}
Pretty JSON:
{
"number": 12,
"bool": true,
"nothing": null,
"list": [
4,
"A"
],
"6": 7,
"1.1": 1
}
Note the differences: most importantly, only strings can be names in JSON. In Python, any immutable type can be a dict key. For non-string keys in Python dict, json converts these to strings.
json.dumps returns a string, which is ready to be written to a file in the usual manner:
with open("output.json", "w") as f:
print(pretty_json_out, file=f)
CSV
Another common file format for table data (such as spread sheets) is the Comma-Separated Value (CSV) format.
CSV files are, quite literally, values separated by commas. You can open them with any text editor:
Common Name,Genus,Species,Status
Grackle,Quiscalus,quiscula,NT
Black Rat,Rattus,rattus,LC
Mallard Duck,Anas,platyrhynchos,LC
Canada Goose,Branta,canadensis,LC
While Python has a “built in” library for working with CSV files (it’s called csv), in practice, you will use the pandas library. This library is named after an adorable beast.
You will need to install the pandas library into your project. Using uv at the command line, run:
We can then read in the CSV using pandas – the result is an object called a dataframe:
import pandas as pd
species = pd.read_csv("species.csv")
print(species)
Common Name Genus Species Status
0 Grackle Quiscalus quiscula NT
1 Black Rat Rattus rattus LC
2 Mallard Duck Anas platyrhynchos LC
3 Canada Goose Branta canadensis LC
It is a convention to import pandas as pd. This is not necessary, we could just as readily have written:
import pandas
species = pandas.read_csv("species.csv")
Nonetheless, the Python data analysis community almost always uses pd, and almost all documentation you find for pandas will do this.
Pandas has a tremendous amount of functionality. Here is an example of adding a new column based on the contents of existing columns:
import pandas as pd
species = pd.read_csv("species.csv")
species['Least Concern'] = species['Status'] == "LC"
print(species)
Common Name Genus Species Status Least Concern
0 Grackle Quiscalus quiscula NT False
1 Black Rat Rattus rattus LC True
2 Mallard Duck Anas platyrhynchos LC True
3 Canada Goose Branta canadensis LC True
We won’t get into detailed Pandas functionality in this course. The Pandas documentation is very thorough, and a great place to go if you need to work with CSV data.
Command Line Arguments
We often want to write Python programs that work on files. When we call these programs from the command line, we want to be able to specify which files to work with. We use command line arguments to do this:
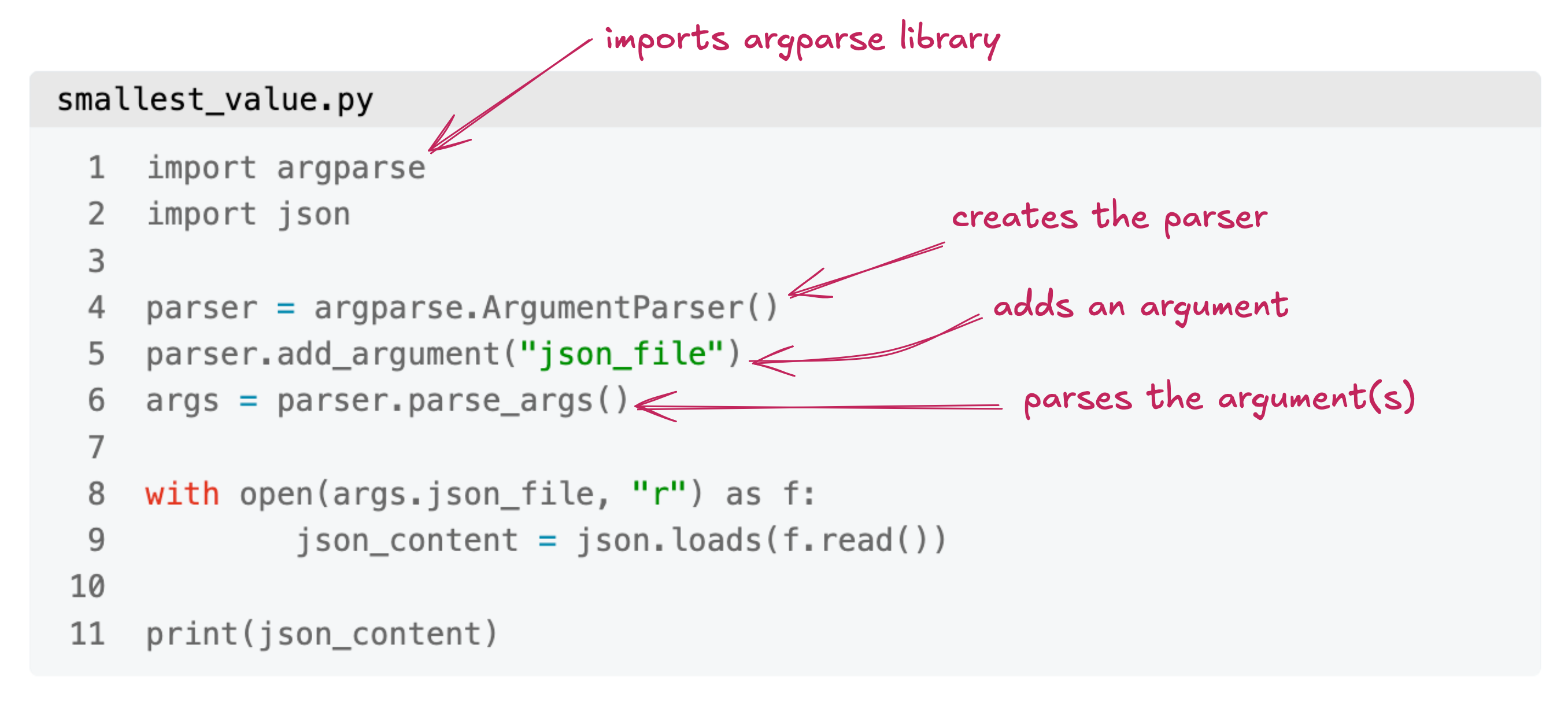
python smallest_value.py values.json
import argparse
import json
parser = argparse.ArgumentParser()
parser.add_argument("json_file")
args = parser.parse_args()
with open(args.json_file, "r") as f:
json_content = json.loads(f.read())
print(json_content)
The syntax is very prescriptive, but simple if we are only parsing one argument:
Arguments are passed as strings into Python, so that what you type at the command line after the Python file name becomes a string you can use inside the program.
The argparse library also supports some very advanced functionality. We won’t use it here, but for further reading, look at the argparse documentation.
Keyword Arguments
Python functiond definitions support two types of arguments: regular (“positional”) arguments, which distinguish between arguments by position, and keyword arguments, that distinguish between arguments by name.
Keyword arguments have a position, and can be used positionally:
def f(x:int, y:int=2) -> str:
return str(x) + str(y)
print(f(3, 4)) # keyword argument used positionally
Keyword arguments can be omitted, and the default value is used:
def f(x:int, y:int=2) -> str:
return str(x) + str(y)
print(f(3)) # keyword argument omitted (default used)
Keyword arguments can also be called by keyword: if this is done, not all keyword arguments need to be specified.
def f(x:int, y:int=2, z:int=3) -> str:
return str(x) + str(y) + str(z)
print(f(3,z=7)) # not all keyword arguments used
Keyword arguments must always follow positional arguments, both in function definitions, and in function calls.
Comprehensions
Comprehensions are Python expressions that concisely create lists and dictionaries. A comprehension nests a for expression inside of square brackets, creating the contents of a list using a loop.
As an example, suppose we have a list of strings, and we want to create a new list consisting of the strings from the original list that are entirely lower case.
Without a list comprehension, we would use a for loop:
L = ["Abacus", "calculator", "TI-89", "pen and paper", "Laptop", "computer"]
new_L = []
for l in L:
if l == l.lower():
new_L.append(l)
print(new_L)
['calculator', 'pen and paper', 'computer']
The comprehension saves us some keystrokes:
L = ["Abacus", "calculator", "TI-89", "pen and paper", "Laptop", "computer"]
new_L = [l for l in L if l == l.lower()]
print(new_L)
['calculator', 'pen and paper', 'computer']
The two programs above are equivalent. They do the same thing. You will never need to use a list comprehension, and comprehensions may make your code much harder for others (or you) to read.
Nonetheless, because they can often simplify a long program into a much shorter one, comprehensions are commonly used by Python programmers. Even if you don’t enjoy using comprehensions, chances are you will encounter quite a few of them in the wild.
Dictionary comprehensions exist as well. They work very similarly:
L = ["Abacus", "calculator", "TI-89", "pen and paper", "Laptop", "computer"]
D = {l[0]:l for l in L if l == l.lower()}
print(D)
{'c': 'computer', 'p': 'pen and paper'}
Review: what happened to calculator ?
Practice
Practice Problem 6.1
Write a Python function that takes as argument a list. The list will contain integers.
- Create dictionary with the list elements as keys, and the squared value of the list elements as values
- Write the dictionary out as a
.json file (filename isn’t important)
Practice Problem 6.2
Write a Python function that reads in the .json from the previous problem and returns the original list.
Practice Problem 6.3
Write a Python function that takes as argument a dictionary and returns valid JSON equivalent to the json.dumps function. You can assume:
- Keys will be ints, floats, or strings
- All of these will need to be converted to JSON names
- Values will be ints, floats, strings, or lists:
- Ints and floats will become JSON numbers
- Strings will become JSON strings
- Lists will become JSON arrays
- List values will contain ints, strings, or floats
- These must be converted to JSON numbers and strings
Practice Problem 6.4
Write a Python function that takes as argument a dictionary and returns valid JSON equivalent to the json.dumps function. You can assume:
- Keys will be ints, floats, or strings
- All of these will need to be converted to JSON names
- Values will be ints, floats, strings, or lists:
- Ints and floats will become JSON numbers
- Strings will become JSON strings
- Lists will become JSON arrays
- List values will contain ints, strings, or floats
- These must be converted to JSON numbers and strings
One way to test this is to use json.loads on the output.
Practice Problem 6.5
Improve your JSON formatter by supporting a second level: values can be dicts, and must be parsed into JSON objects.
Practice Problem 6.6
Consider a CSV format consisting of first names and last names:
Smith, Jean
Carlsson, Otis
Reyes, Omar
Mueller, Anna
Ali, Syed
Using pandas, read such a CSV and output a modified CSV, that contains email addresses in the following format:
Smith, Jean, jean.smith@domain.tld
Carlsson, Otis, otis.carlsson@domain.tld
Reyes, Omar, omar.reyes@domain.tld
Mueller, Anna, anna.mueller@domain.tld
Ali, Syed, syed.ali@domain.tld
Homework
Homework Problem 6.1
Without using any libraries that parse JSON, write a json parser that reads in valid JSON and returns a dict:
- The JSON will consist of a single object with names and values:
- The names might represent ints, strings, or floats
- The values might be numbers, strings, or arrays
- Arrays can contain numbers or strings
Parse the JSON and return a dict:
- Names should be checked and any name that can represent a numeric type (int or float) should be cast to an int or float, respectively.
- “2” should become int
2
- “2.0” should become int
2
- “2.5” should become float
2.5
- Similarly, numeric values should become ints if they are exactly equal to an integer, otherwise floats
- The presence of a decimal point should not be used to determine if a number is an int
Wrap the parser in a function parse_json that takes a single positional argument, a string, which represents the JSON, and a keyword argument, file:
file should default to bool False- if
file is used, the positional string argument is ignored, and your function should read JSON from a file specified by the file keyword (as a relative path)
Example calls:
parse_json('{"something": 2}')
parse_json("", file="data.json")
Submit as parse_json.py
Homework Problem 6.2
Without using any libraries that parse JSON, modify your parse_json function to add support for additional depth, such that values in the top-level object can themselves be objects.
Submit as parse_json_2.py