Work through examples of using the break statement.
Write code to read and write to text files.
4.0 Audio:
4.0 While loops: an example
The numbers 1, 4, 9, 16, 25, and so on are squares, with
the next one being 36 (which is \(6^2\)).
Suppose we want to identify the largest square that's less than 1000.
We'll first show how this can be solved with a new kind of loop:
the while-loop, and then try the same problem with a for-loop.
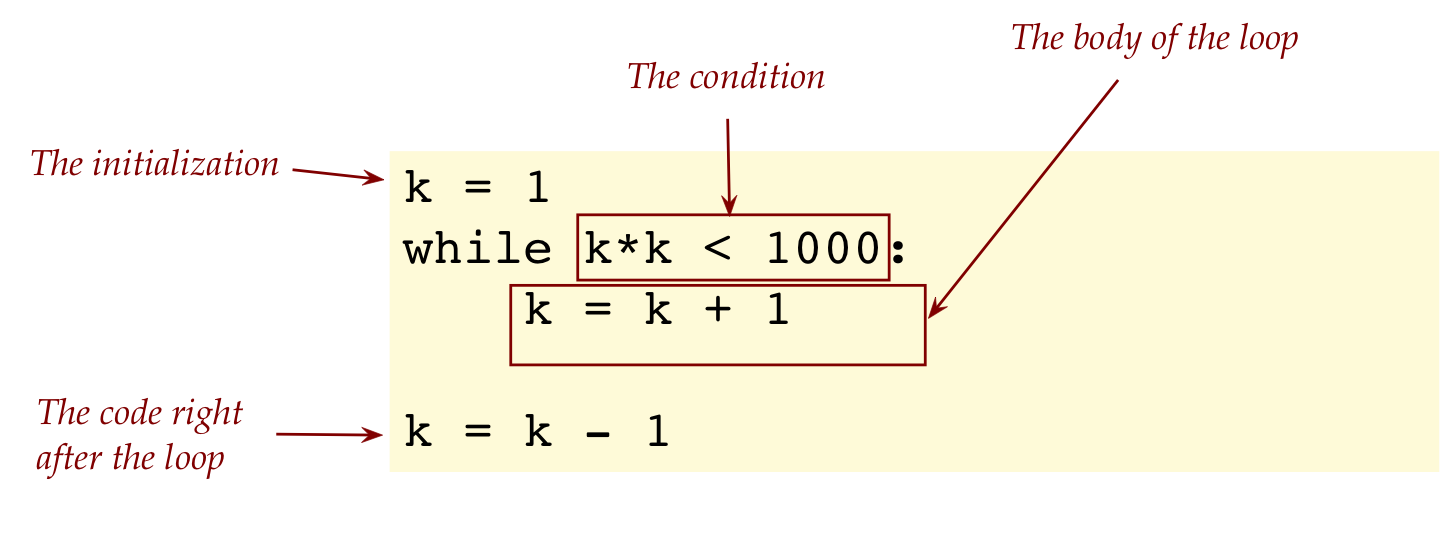
The program:
k = 1
while k*k < 1000:
k = k + 1
# Reduce by 1 because now k*k > 1000
k = k - 1
print('largest square < 1000:', k*k, '= square of', k)
4.1 Exercise:
Type up the above in
my_while_example.py.
How does a while-loop work?
The essential idea is: a while-loop keeps iterating until
its condition evaluates to False.
Let's examine the structure:
In our example, the condition was:
while k*k < 1000:
Thus, as long as the value of
k
is such that
k*k
is less than 1000, execution enters and stays inside the loop.
Notice that
k
is incremented (or changed) inside the loop:
while k*k < 1000:
k = k + 1
Thus, eventually
k
will get large enough so that
k*k
will be larger than 1000.
When k is 32, in fact, 32*32 = 1024, which will
cause the condition
k*k < 1000
to evaluate to False.
At this moment, execution exits the loop to the
whatever code follows:
Let's examine a simpler while-loop:
k = 1
while k < 6:
print(k)
k = k + 1
4.2 Exercise:
Trace the execution of each iteration in your module pdf.
Then confirm by typing up the above in
my_while_example2.py.
4.3 Exercise:
Consider this variation:
k = 7
while k < 6:
print(k)
k = k + 1
Trace the execution of the above program in your module pdf.
Then confirm by typing up the above in
my_while_example3.py.
4.4 Exercise:
Consider this variation:
k = 1
while k < 6:
print(k)
Trace the execution of a few iterations
of the above program in your module pdf.
Then confirm by typing up the above in
my_while_example4.py.
After a minute, you may need to terminate the execution of the
program by hand (by getting rid of the window itself).
4.5 Audio:
Keep in mind:
A while-loop typically must feature some kind of
initialization before the loop as in:
k = 1
while k < 6:
print(k)
k = k + 1
The variable that's involved in the condition should
be changed inside the loop so that the condition eventually
evaluates to False:
k = 1
while k < 6:
print(k)
k = k + 1
Another important thing to remember: if you forget to
change a variable like k inside the loop, the condition will
never becomes False, which means the loop will iterate forever:
k = 1
while k < 6:
print(k)
i = k + 1 # Error!
Here
The incremented value k+1 does not get stored in k.
Which means k never gets large enough.
Therefore k < 6 will always be True.
Thus, we get an infinite loop (that iterates forever).
It's alright, but probably
not useful, if the condition never evaluates to True
even once:
k = 6
while k < 6:
print(k)
k = k + 1
The code still runs but the while-loop is not executed at all.
4.1 While loops: an example with floating point variables
Consider this example:
x = 0.5
s = 0
while s <= 2:
s = s + x
print('s =', s)
4.6 Exercise:
Try to guess the output before confirming in
my_while_example5.py.
Note:
The value of x (which is 0.5) keeps getting added to s,
as long as s is less or equal to 2.
Thus, the last value of s to keep going in the loop is
when s = 2.
At this time, we stay for one more iteration, after which
s becomes 2.5.
Let's look at a more illustrative version now:
x = 0.5
s = 0
k = 0
while s <= 2:
s = s + x
k = k + 1
print('s =', s, 'k =', k)
Here, we've added a counter variable to track each
loop iteration.
4.7 Exercise:
Trace the values of the three variables in your module pdf.
Then confirm in
my_while_example6.py.
So far it's been straightforward. Let's now solve a problem:
To summarize one version, Zeno said (with a wry smile, probably):
To walk a mile, you'd have to first walk half the remaining
distance (0.5 miles).
Then, to get to the rest, you'd have to walk at least half
of the remaining (0.25).
Then, half of the remainder (0.125)
... and so on.
So, the total distance would be an infinite sum:
0.5 + 0.25 + 0.125 + ...
Which is infinite [he said]
Let's count how many successive halvings add up to, say, 0.9.
Here's the code:
x = 1
s = 0
k = 0
while s < 0.9:
x = x / 2 # Halve x each time
s = s + x
k = k +1
print(k)
We accumulate the sum in s.
Note that we start with x = 1 because we perform the halving
before adding to s.
This means the first value added into s is 0.5 (as intended).
Each such addition into s get counted in k.
4.8 Exercise:
Trace the values of the three variables in your module pdf.
Then confirm in
my_while_example7.py.
4.9 Audio:
A few comments that go beyond the scope of the course (just for
curiosity):
The infinite sum, in fact, adds up to 1.
It took centuries for mathematics to develop to a point
where one can prove that infinite sums are acceptable and
can have finite results.
However, a computer can only represent
real numbers approximately, which means the sum is itself
approximate.
You can see this by changing the while-condition from
while s < 0.9:
to
while s < 1:
Theoretical math would say that the while-loop would execute
forever, but because there limits to what's representable on
a computer, the loop will indeed terminate.
4.2 for vs. while
Let's contrast for-loops and while-loops by
writing a for-loop as a while-loop, and vice-versa.
As an example, let's print the numbers 0 through 10:
# for-loop version
for k in range(11):
print(k)
# while-loop version
k = 0
while k < 11:
print(k)
k = k + 1
Note:
The for-loop is simpler to write.
The while-loop must make explicit three things:
The initialization:
k = 0
while k < 11:
print(k)
k = k + 1
The termination condition:
k = 0
while k < 11:
print(k)
k = k + 1
And the variable change (that will ultimately cause the
condition to become False):
k = 0
while k < 11:
print(k)
k = k + 1
All of this is hidden in the for-loop.
Underneath the hood, it turns out, the for-loop
also has these three elements.
It's just that we don't have to write them,
Python does so behind the scenes.
When you write while-loops, ask yourself: "Do I have
the three elements (initialization, condition, variable-change)?"
A really common mistake: forgetting the change, as in:
k = 0
while k < 11:
print(k)
This loop runs forever!
4.10 Exercise:
Consider this for-loop:
for k in range(5, 20, 2):
print(k)
In
my_for_while.py,
write the while-loop equivalent.
Next, let's go from while to for:
Consider this while-loop that prints the letters in a
string backwards:
s = 'hello'
k = len(s) - 1
while k >= 0:
print(s[k])
k = k - 1
Note:
The initialization starts k at the last index of the string:
k = len(s) - 1
The loop condition expects k to decrement until it hits 0.
After this, k (when it's -1) will have gone past the left
end of the string.
k decrements in the loop.
The equivalent for-loop is efficient to write, but less pretty:
for k in range(len(s)-1, -1, -1):
print(s[k])
Here:
The range begins with
for k in range(len(s)-1, -1, -1):
Ends with 0, but has the index just past (-1) as the limit:
for k in range(len(s)-1, -1, -1):
And the increment is -1 (which makes it a decrement).
Later, when we learn more advanced ways of using slicing,
we will be able to do the same thing with shorter code.
4.11 Exercise:
Trace through both loops in your module pdf before confirming both
in
my_for_while2.py.
4.12 Exercise:
Consider the following program with a while-loop:
def func(A):
k = 0
while A[k].startswith('h') and (len(A[k]) > 4) and (k < len(A)):
print(A[k])
k += 1
def func2(A):
# Write your for-equivalent here:
B = ['hello', 'hey there', 'howdy', 'huzzah', 'hi', 'greetings']
func(B)
func2(B)
Trace through the first loop (in
func)
in your module pdf, to see that the loop keeps printing
strings from a list as long as the strings start with 'h' and
have length at least 5.
Then, in
my_for_while3.py,
complete the code in
func2
using a for-loop to achieve the same result.
4.13 Video:
4.3 Using break in loops
Let's return to our first example of finding the last square
that's less than 1000.
Recall what we wrote:
k = 1
while k*k < 1000:
k = k + 1
k = k - 1
print('largest square < 1000:', k*k, '= square of', k)
One can use a break statement as
an alternative to writing the "loop exit" condition as
the while condition.
We'll first do this with a for-loop, and then see something
unusual with the while-loop version.
To simplify tracing, let's rephrase to "largest square less than 50".
First, the for-loop version:
for k in range(1, 50):
# print('Before-if: k =', k)
if k*k > 50:
break
# print('After-if: k =', k)
k = k - 1
print(k)
4.14 Exercise:
Type up the above in
my_break.py,
removing the # to un-comment the print's, so that you
can see exactly what happens when the if-condition triggers.
Let's point out:
A break-statement is the reserved word
break
all by itself on a line, as seen above.
When a break statement executes, Python looks for
the loop that encloses the break and abruptly, right there and then,
exits the loop.
Break-statements are useful to check for conditions that
should result in leaving the loop immediately.
One could write code like this, but it would make no sense:
for k in range(10):
print(k)
break
This would cause the first value (0) to print, and a break right out
of the loop.
As a mathematical aside, we know that we don't really need
the for-loop range to be as high as 50:
for k in range(1, 50):
if k*k > 50:
break
After all, as k gets close to 50, there is no way k*k would be less
than 50. However, we'll leave it as is, for the sake of simplicity.
There are options in writing the loop. Consider this one:
for k in range(1, 50):
if (k+1)*(k+1) > 50:
print(k)
break
Is this more elegant, if a bit harder to understand at first?
4.15 Exercise:
Trace the execution of the above loop in you module pdf,
The type it up in
my_break2.py,
to confirm.
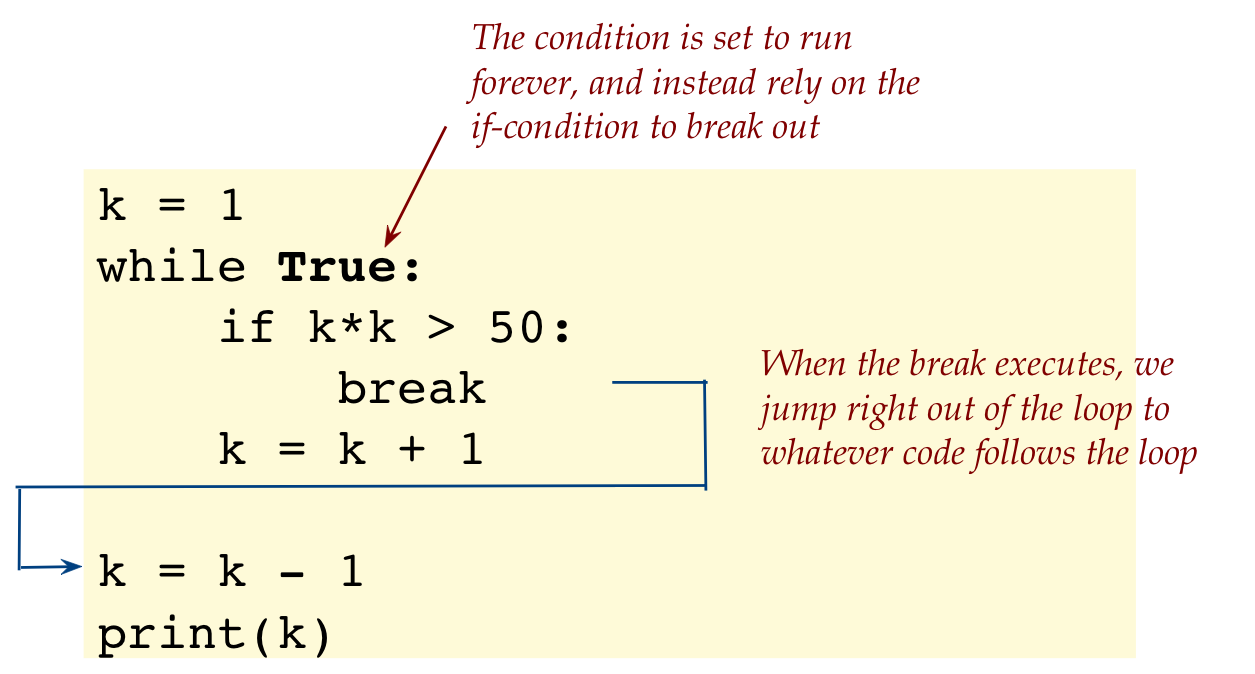
Next, let's look at a while-loop version of the original
Here's the code:
k = 1
while True:
if k*k > 50:
break
k = k + 1
k = k - 1
print(k)
Observe:
Was it surprising that we deliberately set up a loop to
appear to run forever?
This is entirely do-able and often desirable, provided
we are real careful to set up a condition inside the loop
to break out eventually.
We need to be sure we hit that condition eventually.
4.16 Exercise:
In your module pdf, describe what would go wrong if the statement
k = k + 1
was mistakenly typed in as
k = k - 1.
4.17 Exercise:
In
my_break3.py,
go back to the earlier exercise (4.12) where you wrote a while-loop
to print strings of length at least 5, and starting with 'h'.
Rewrite the while-loop to use a break-statement instead.
4.18 Audio:
4.4 Loops within loops
Just as we've seen nested for-loops, so can we have nested
while-loops or one kind inside another.
Consider this example:
m = 10
while m <= 10000:
for k in range(1, m):
if (k+1)*(k+1) >= m:
print('largest square <', m, ':',k*k)
break
m = m * 10
4.19 Exercise:
Type the above in
my_nested_loop.py
and try to make sense of it.
Let's explain:
First, notice that we have a for-loop inside a while-loop:
Let's start with understanding what happens in the outer loop:
Thus, m is first 10, then 100, then 1000, then 10000.
Now let's see what happens within one iteration of the
outerloop (for a particular value of m):
Important: The break in the for-loop exits the
for-loop (the enclosing loop), which means we'll still be inside
the while-loop (where m changes).
4.20 Exercise:
In
my_nested_loop2.py,
change the inner loop to a while loop so that we get
the same output.
4.21 Exercise:
In
my_nested_loop3.py,
change the code so that both the outerloop and innerloop
are for-loops. One way to solve
this problem: use a variable called j to range through
the outer for-loop and then ensure that the innerloop
executes only when j happens to equal m.
(Aren't you glad we have while-loops?)
4.22 Audio:
4.5 More stats via programming
Consider the following problem:
An experiment consists of flipping three coins.
The experiment is repeated until all three are "heads"
On average, how many experiments are needed until
all three turn up "heads"?
One way to think about this problem "statistically" is this:
Suppose we hire a thousand people to each perform
repeated three-coin flips.
For very few of these people, they'll get "heads-heads-heads"
the very first experiment.
For others, they might have to repeat 10 times before they see this.
Each person counts how many experiments had to be tried before
getting three-heads.
The result is the average number across the thousand people:
the average number of 3-coin flips needed to see three heads.
Instead of calculating by hand, we will write a program to estimate
this number:
import random
num_trials = 1000
total = 0
for k in range(num_trials):
got_three = False
num_three_flips = 0
while not got_three:
c1 = random.choice(['H','T'])
c2 = random.choice(['H','T'])
c3 = random.choice(['H','T'])
num_three_flips += 1
if (c1 == 'H') and (c2 == 'H') and (c3 == 'H'):
got_three = True
total += num_three_flips
estimate = total / num_trials
print('estimate', estimate)
4.23 Exercise:
Type up the above in
my_coin_flips.py
to get an estimate. (Submit the program with 1000
trials.) Then, increase the number of trials to get
a more accurate estimate, and report that in your module pdf.
Can you explain the result intuitively?
Let's point out:
First, let's point out the process of estimation (the outer
loop) that we'd use in any estimation problem:
num_trials = 1000
total = 0
for k in range(num_trials):
# how many of these resulted in successes?
estimate = total / num_trials
Now let's look inside to see how each trial is performed:
A variable like
got_three
is sometimes called a flag variable: we use it
to flag a condition that we're looking for.
4.24 Exercise:
In
my_coin_flips2.py,
instead of using a flag variable, use a break statement
to exit the loop. You might have to make a small adjustment
to get the correct result.
4.25 Exercise:
Consider an experiment where you roll a die twice
to see if you get 6 and 6.
In
my_dierolls.py,
estimate the average number of experiments needed to
get two sixes.
4.26 Audio:
4.6 New topic: reading from a file
Very often, data is collected and stored in files, and so
it's desirable to learn how write code that plucks data
right out of such files.
Let's start with a simple test file of plain text.
First, examine the file
testfile.txt
to see that it's a file consisting of four lines of text.
(From the poet Ogden Nash.)
We will look at a few different versions of reading
from this file.
Here's the first:
with open('testfile.txt', 'r') as in_file:
lines = in_file.read()
print(type(lines))
print(lines)
4.27 Exercise:
Type up the above in
my_file_read.py.
What is the type of the variable
lines?
Note:
We've used two Python reserved words:
with open('testfile.txt', 'r') as in_file:
Although file input/output (I/O) does not strictly require
the with structure, it is useful because:
Files that are being accessed by one program are said to be
in an "opened" state.
For another program to be able access the file, the first
one has to "close" it (that is, signal that it's done with the file).
The with structure automatically takes care of it.
The function call to
open
takes the name of the file and the kind of access, for example:
with open('testfile.txt', 'r') as in_file:
'r' for read-only access (we're not changing the file here)
'w' for write, if we should choose to.
The result of opening a file is to get a special
kind of variable, what we've called
in_file
in this case:
with open('testfile.txt', 'r') as in_file:
It is this variable that's going to perform the
reading and, in this case, get us all the text in one shot:
with open('testfile.txt', 'r') as in_file:
lines = in_file.read()
Note that all the lines are returned as a single string.
This means, it will be difficult to analyze
string-by-string, if that's our goal.
There is a way to take the single string and break it into
separate lines, but let's instead find a way to read separate lines.
Accordingly, let's look at a way to read the file into a
list of strings, where each line is one string in the list:
lines = []
with open('testfile.txt', 'r') as in_file:
line = in_file.readline()
while line != '':
lines.append(line.strip())
line = in_file.readline()
print(type(lines))
print(lines)
4.28 Exercise:
Type up the above in
my_file_read2.py.
What is the type of the variable
lines?
Note:
Here, we're reading one line at a time and appending
to a running list, which is the
lines
variable.
The problem is, for any general file, we won't know
in advance how many lines of text are in the file.
A while-loop to the rescue!
Thus, we keep reading from the file as long as a
read operation produces a line:
Writing to a file:
Suppose we've read a text file into a list of strings.
Let's now write these to a new file:
with open('testcopy.txt', 'w') as out_file:
for line in lines:
out_file.write(line + '\n')
This time, we're opening a file called
testcopy.txt
for the purpose of writing to it:
with open('testcopy.txt', 'w') as out_file:
for line in lines:
out_file.write(line + '\n')
We've named our file variable
out_file.
That will let us use a function called
write():
with open('testcopy.txt', 'w') as out_file:
for line in lines:
out_file.write(line + '\n')
Here, we're looping through the list, writing each string
as one line in the file.
Notice that we need to insert the '\n' at the end of each line.
Recall:
'\n' represents an instruction to both output and files
to "go to the next line right now".
Thus for example
print('hello' + 'world') # Prints helloworld on one line
print('hello' + '\n' + 'world') # Prints hello, and then world on the next line
So, to write strings to different lines, we have to tell the
function that writes to files to go to the next line with an
explicit '\n'.
It's similar with reading, if we read a whole file as
one string, that string will contain the
so-called linebreaks (the '\n' characters).
4.29 Exercise:
In
my_file_readwrite.py,
combine the reading and writing so that the program as whole
results in copying from
testfile.txt
to
testcopy.txt.
Next, let's read from a file of numbers and perform
some basic stats:
First, examine the file data.txt
and see that it's a collection of numbers, one per line.
We'll read line by line as a string, and then convert to
a floating-point number:
data = []
with open('data.txt', 'r') as in_file:
line = in_file.readline()
while line != '':
s = line.strip() # Remove leading/trailing whitespace
x = float(s) # Convert string to float
data.append(x) # Add to our list
line = in_file.readline() # Get the next line
print(data)
4.30 Exercise:
In
my_file_data.py,
add code to compute the average of the numbers and print it.
Compute the total as you iterate in the while-loop.
4.31 Audio:
4.7 Extracting multiple data from each line
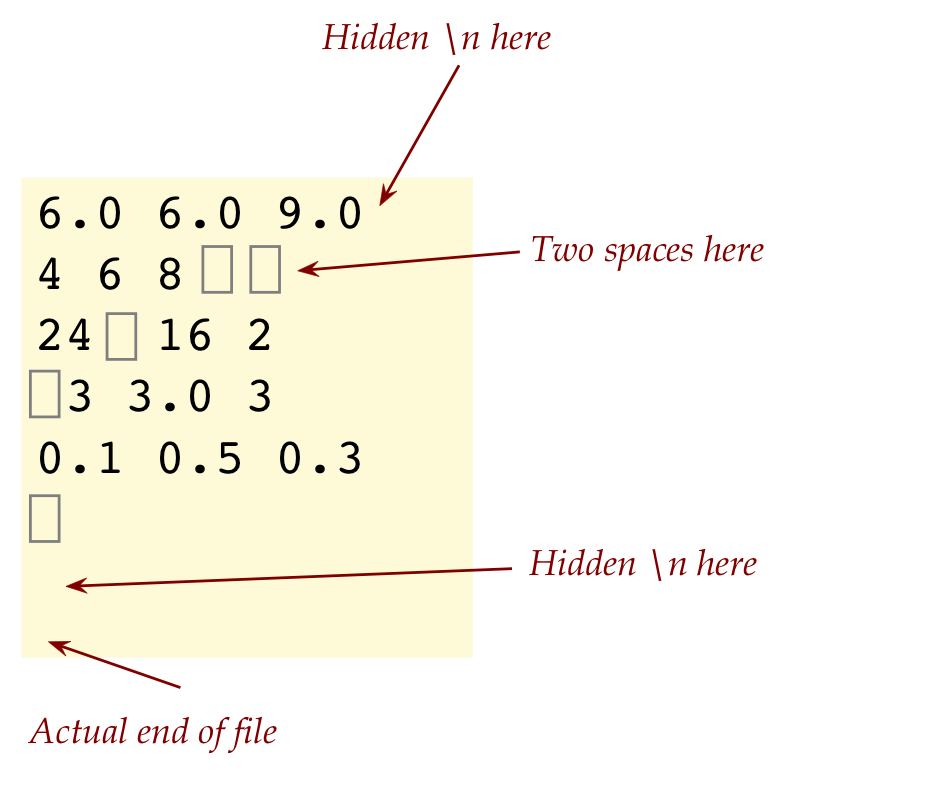
Consider a data file that looks like this, with three
numbers on each line:
6.0 6.0 9.0
4 6 8
24 16 2
3 3.0 3
0.1 0.5 0.3
What we'd like to do is compute the average of the numbers in
each line. So, the output should be something like:
Average of 6.0 6.0 9.0 is: 7.0
Average of 4.0 6.0 8.0 is: 6.0
Average of 24.0 16.0 2.0 is: 14.0
Average of 3.0 3.0 3.0 is: 3.0
Average of 0.1 0.5 0.3 is: 0.3
Therefore, what need to do is not only read a line at a time, but be able
to extract multiple items from within a line.
We can split a string as follows:
Consider this example:
s = '6.0 6.0 9.0'
data = s.split() # data is a list
print(data)
Here, the split() function in strings, looks for
whitespace within and separates out into a list those items
separated by this whitespace.
So, in the above example, we'll have the string '6.0 6.0
9.0' split into a list of three strings ['6.0', '6.0', '9.0']
Having a list of strings is not enough to compute the
average of the numbers in those strings.
We need to convert into numbers:
s = '6.0 6.0 9.0'
data = s.split() # data is a list
print(data)
x = float(data[0])
y = float(data[1])
z = float(data[2]) # x, y, z are numbers
avg = (x + y + z) / 3.0
print(avg)
We can now read one line at a time from the data file,
split each line, convert to numbers, and then calculate the average
for each line.
4.32 Exercise:
Type up the above in
my_split_example.py
to see. Next, examine the file
data2.txt in
a text editor and try and identify all the (unnecessary) whitespace within.
We'll now tackle one additional complication:
It is common for real data to be acquired or presented
with mistakes, missing entries, or weird whitespacing.
The missing entry problem is somewhat harder to tackle,
so we'll postpone that for another time.
But we can easily eliminate whitespace using strip().
For example consider:
Thus, we need to worry about when
a line is all whitespace but not empty.
Let's put these ideas into code:
with open('data2.txt','r') as in_file:
line = in_file.readline()
while line != None:
line = line.strip()
print('[', line, ']', sep='')
if len(line) == 0:
break
data = line.split()
print(data)
x = float(data[0])
y = float(data[1])
z = float(data[2])
avg = (x + y + z) / 3.0
print('Average of ', x, ' ', y, ' ', z, ' is: ', avg, sep='')
line = in_file.readline()
4.33 Exercise:
Type up the above in
my_file_data2.py.
You already have saved the file data2.txt in the same folder.
We'll point out a few things:
We have two print's in there to see what we get as
a result of strip() and split():
line = line.strip()
print('[', line, ']', sep='')
data = line.split()
print(data)
Recall: the sep='' (empty separation)
parameter tells print() not to add its
own whitespace between different arguments.
Notice also that we have deliberately added in our printing,
a pair of brackets:
print('[', line, ']', sep='')
This is a common programming technique when you want to identify
whitespace: put something around it that is actually visible.
You also noticed that split() produces a list, and that
each string in the list has already had whitespace removed on
either side.
4.8 While-loops when files are large
Let's return to a problem we've seen before: identifying
the longest sentence in a text file.
To find the longest sentence, we read the whole file
into one giant list of sentences.
Then, we went through the list, recording the longest sentence.
For a really large text file, the list could be too long
to fit into memory.
Let's use a different version that reads
sentence-by-sentence:
import wordtool as wt
def get_longest_sentence(filename):
# Initiate the reading of the file
sentences = wt.open_file_bysentence(filename)
maxL = 0
# Get first sentence
s = wt.next_sentence()
while s != None:
if len(s) > maxL: # Possibly update maxS
maxL = len(s)
maxS = s
s = wt.next_sentence() # next one
return maxS
book = 'federalist_papers.txt'
s = get_longest_sentence(book)
print('Longest sentence in', book, 'with', len(s), 'chars:\n', s)
4.34 Exercise:
In
my_text_analysis.py,
count the number of sentences that have length greater than 280
characters (more than a tweet) in
federalist_papers.txt.
You will need to download
wordtool.py and
wordsWithPOS.txt.
4.9 Random walks and art
But of course. We're somehow going to combine while-loops
with our recurring themes (algorithmic art, randomness).
This time, we will use a well-known idea from science
called a random walk:
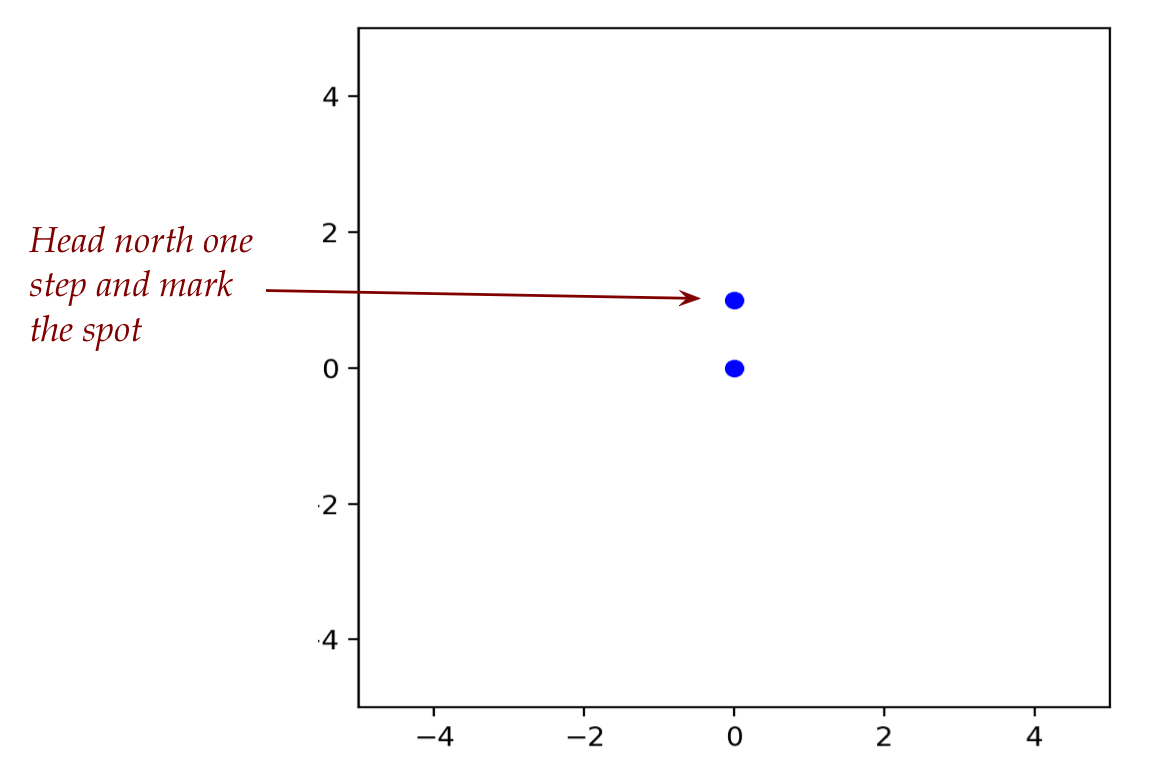
Imagine standing at the origin:
Then, we choose a random direction from among:
North, South, East, West.
Once such a direction is randomly chosen: we take a
fixed-size step in that direction, and mark the spot:
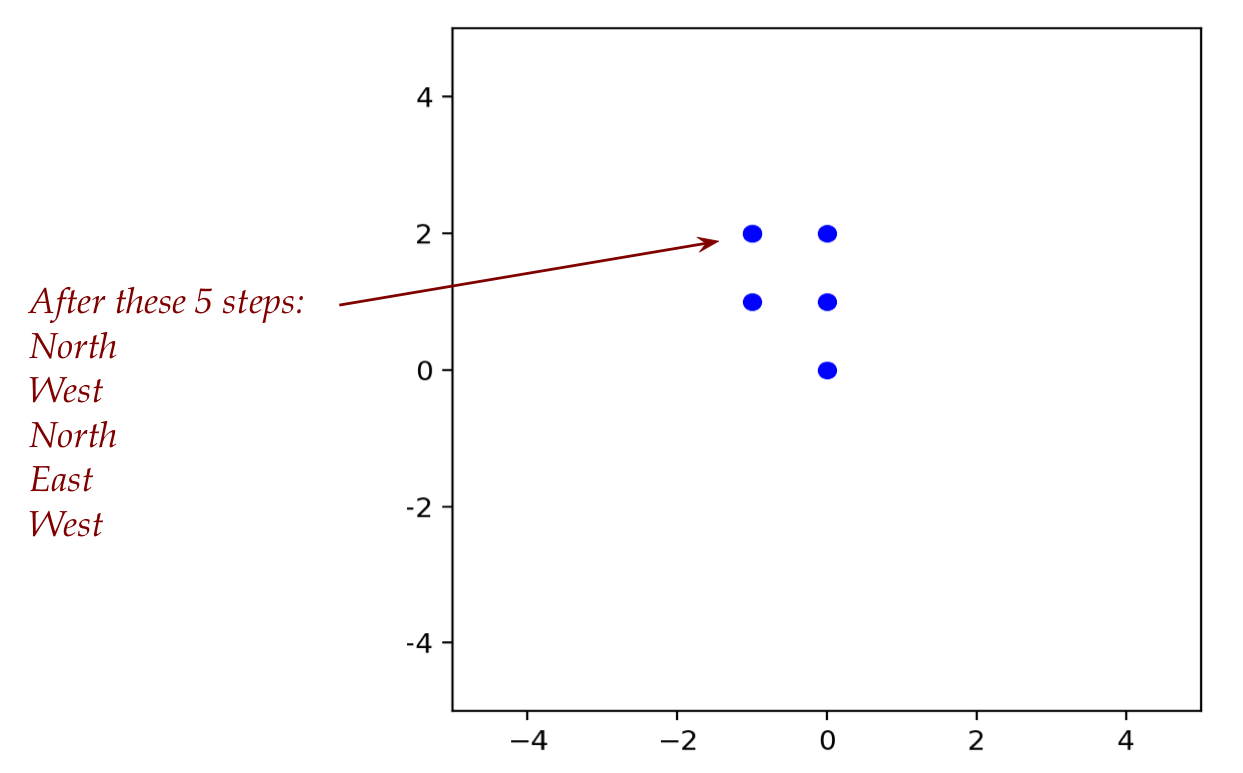
Here's what it might look like after 5 steps:
Here's the program:
import random
from drawtool import DrawTool
dt = DrawTool()
dt.set_XY_range(-5,5, -5,5)
dt.set_aspect('equal')
step = 1
def do_walk(max_steps):
x = 0
y = 0
num_steps = 0
dt.draw_point(x, y)
while num_steps < max_steps:
direction = random.choice(['N','S','W','E'])
if direction == 'N':
y += step
elif direction == 'S':
y -= step
elif direction == 'E':
x += step
else:
x -= step
dt.draw_point(x, y)
print(direction, x, y)
num_steps += 1
do_walk(5)
dt.display()
4.35 Exercise:
Type up the above in
my_randomwalk.py
and try out a larger number of steps.
You will also need
drawtool.py.
Call
do_walk()
twice and change the draw color in between using
dt.set_color('r').
Instead of running the random walk for a fixed number of
steps, we'll now run the random walk until it "hits" one
of the sides and stop.
To do this, we'll use the approach of:
while True:
# get a random direction and move
# if we hit one of the sides, then break
We'll also enlarge the box to be bigger and make
the step size smaller (so as to fill the space with dots).
4.36 Exercise:
Try out
random_walk_demo2.py
several times. Then, change the code so that the function
do_walk()
takes in the starting point as a parameter.
Call
do_walk()
several times with different starting points.
We're now finally ready for the art project:
We'll start different random walks at randomly selected
starting points, and then draw each in a random color.
4.37 Exercise:
Try out
random_walk_art.py
several times. Try to modify it to improve the (artistic) outcome.
Describe what you did in your module pdf and submit a
screenshot.
About random walks (in science):
Although a random walk might seem like a silly exercise,
the idea has had significant scientific impact.
For example, a version of random walk is the basis
for modeling diffusion and osmosis.
The same basic idea underlies Brownian motion
and Einstein's demonstration of the existence of molecules.
A random walk on networks (as opposed to 2D space) is
what launched Google.
Evolution is often modeled as a random walk on an
abstract representation of the space of DNA sequences.
Is that enough to believe in the importance of random walks?
4.10 When things go wrong
In each of the exercises below, first try to identify the error
just by reading. Then type up the program to confirm, and
after that, fix the error.
4.38 Exercise:
The following code wants to print the numbers from 10 to 1
in descending order:
k = 0
while k > 0:
print(k)
k = k - 1
Identify and fix the error in
my_error1.py.
4.39 Exercise:
The following code wants to print the numbers from 1 through 10,
along with each number's "double" (twice the number).
m = 1
n = 2
while (m <= 10) or (n <= 20):
print(m, 2*n)
m = m + 1
n = n + 1
Identify and fix the error in
my_error2.py.
4.40 Exercise:
The following code wants to print the odd numbers from 1 through 9.
x = 1
while x < 10:
if x % 2 == 1: # Test whether odd
print(x)
else:
x = x + 1