Practice working with Boolean expressions and variables.
Practice examples with strings
Start to use built-in functions
Delve into the notion of type
3.0 Audio:
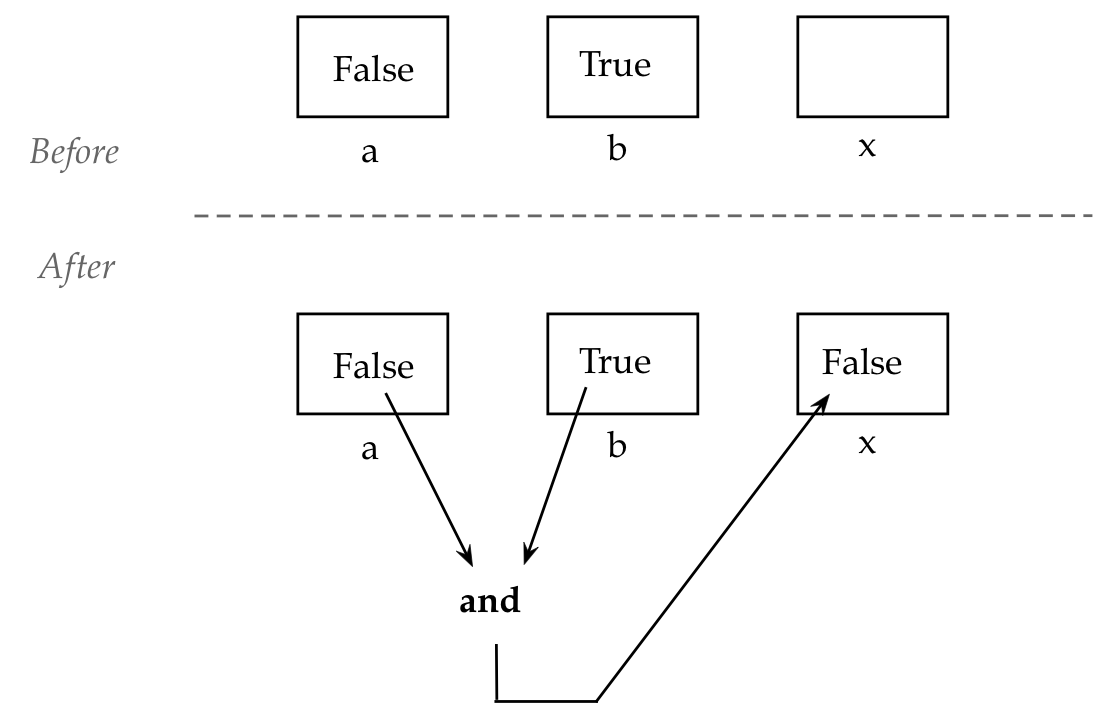
3.0 Boolean variables: two examples
Recall:
An integer variable takes on values like 5 and -33:
x = 5
y = -33
A floating-point variable stores real numbers like:
x = 5.0014
y = -33.3333334
A string variable stores strings or chars, as in:
s = 'hello'
c = 'z'
A boolean variable stores one of two values:
True
or
False
For example:
a = True
print(a)
b = False
print(b)
c = not a
print(c)
d = a or b
print(d)
e = a and b
print(e)
3.1 Exercise:
Type up the above in
my_boolean_example.py.
Report the output in your module pdf.
Note:
The reserved words
True
and
False
are used in their usual sense.
A boolean variable can store only one of these values:
a = True
b = False
Notice:
True
and
False
start with capitals.
These aren't the same as the quote-delimited strings'True'
and
'False'
Just as we could perform arithmetic on integer variables, so
can we perform boolean operations on boolean variables.
The simplest one is not:
a = True
c = not a
Explanation:
Since
a
has the value
True
then
not a
will have the value
False
Thus,
c
will have the value
False.
Likewise
a = False
c = not a
print(c)
will print
True.
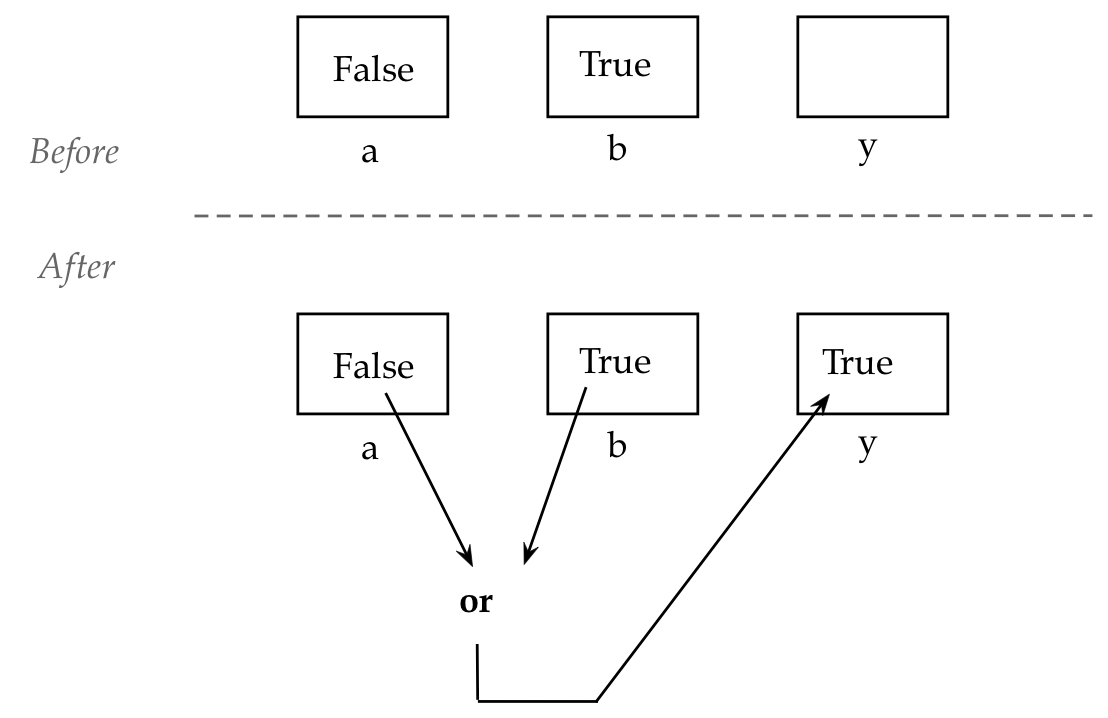
Next, consider or:
d = a or b
How or works:
a or b
will be True when any one of them (a or b)
is True.
Another way to state it:
a or b
will be False only when a and b are both False.
This table shows all the combinations:
a
b
d = a or b
False
False
False
False
True
True
True
True
True
True
False
True
Next, consider and:
e = a and b
How and works:
a and b
will be True only when both are True.
This table shows all the combinations:
a
b
c = a and b
False
False
False
False
True
False
True
True
True
True
False
False
Let's look at another example:
a = True
b = True
a = not a
x = a and b
y = a or b
print(x, y)
3.2 Exercise:
Type up the above in
my_boolean_example2.py.
Report the output in your module pdf.
Let's explain:
First, look at:
a = True
b = True
Here, there are two boolean variables, each of which
is assigned a (boolean) value.
Think of the variables as "boxes" in the usual way but
as boxes that can hold only boolean values
(True or
False).
Next, look at
a = not a
Here, the value in
a
before this executes is
True
So,
not a
is
False.
This gets stored in
a
So, after the statement executes
a
will have the value
False.
Next, look at
x = a and b
We know that
a
has the value
False
in it, while
b
has the value
True.
Thus, the
and
operator is applied to the values
False
and
True.
You can picture this as:
False andTrue.
What is the result?
Similar to applying the "rules of multiplication" to two numbers,
we apply the rules of and
to
False
and
True.
The result is:
False.
Thus, the value
False
is assigned to the variable
x.
The next statement is:
y = a or b
Because
a
is now
False
and
b
is
True,
the result in y will be:
3.3 Video:
3.1 Combining Boolean operators
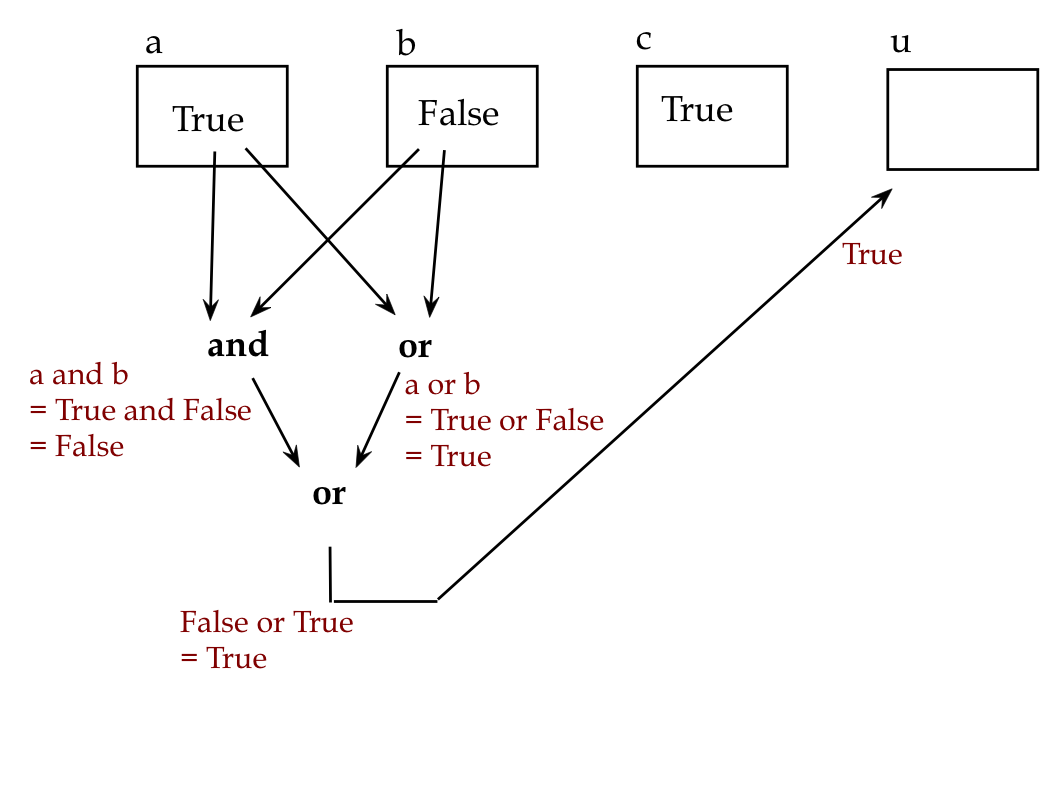
Consider
a = True
b = False
c = True
u = (a and b) or (a or b)
v = (not u) or (not (b and c))
print(u, v)
Let's draw an expression diagram to help us understand
what happens with the first expression:
3.4 Exercise:
Draw an expression diagram to work out the result for
the second expression (the value of v) above. Then
type up the above in
my_boolean_example3.py
to confirm.
3.5 Video:
Boolean expressions can be constructed with numeric
variables and their comparison operators:
k = 5
m = 3
n = 8
a = True
b = False
first = (m < k) and (n > k)
second = ( (k+m == n) or (k-m < 10) )
third = first and (not second)
fourth = first or a
print(first, second, third, fourth)
Note:
Since m is 3, k is 5, the expression
(m < k)
in
first = (m < k) and (n > k)
evaluates to True.
Similarly, the expression
(n > k)
also evaluates to True since n = 8 in
first = (m < k) and (n > k)
Thus, the resulting expression on the right side becomes
first = True and True
Which evaluates to True from the rules (the table) for and.
3.6 Exercise:
Draw an expression diagram to work out the result for
the remaining three expressions above.
Then type up the above program in
my_boolean_example4.py
to confirm.
3.7 Audio:
3.2 Using a Boolean variable
To see how a Boolean variable is used in practice, we will
work through a somewhat elaborate example that will
teach us other useful things.
Let's start with this program:
def print_search_result(A, search_term):
if search_term in A:
print('Found ', search_term)
B = [15, 3, 23, 9, 14, 4, 6, 2]
print_search_result(B, 4)
Here, the goal is to create a function that takes a list,
and a search value (or search term) and looks inside the list
to see if it exists.
Does the program work?
3.8 Exercise:
Type up the above program in
my_search_example.py
to confirm.
Note:
We have exploited the in operator in Python to
examine whether or an element exists in a list:
if search_term in A:
This will return either True or False.
And Python does the work of traversing the list and peeking
inside to see if value (4 in this case) is in the list.
Now consider the problem of also printing the position
where it's found:
def print_search_result(A, search_term):
for k in range(len(A)):
if A[k] == search_term:
print('Found', search_term, 'at position', k)
B = [15, 3, 23, 9, 14, 4, 6, 2]
print_search_result(B, 4)
Does this work?
3.9 Exercise:
Type up the above program in
my_search_example2.py
to confirm.
Note:
We are now traversing the list ourselves:
for k in range(len(A)):
Here, k will start at 0 and go up to the last index (one less than
the length of the list).
At each iteration, we check to see if the search term
is equal to the list element at the current position (determined by k):
What we'd like to do is print something when a search term
is not found in the list.
Consider this program:
def print_search_result(A, search_term):
for k in range(len(A)):
if A[k] == search_term:
print('Found', search_term, 'at position', k)
print('Not found:', search_term)
B = [15, 3, 23, 9, 14, 4, 6, 2]
print_search_result(B, 4)
print_search_result(B, 5)
3.11 Exercise:
Start by thinking through the execution to see if this worked.
Then, type it up in
my_search_example3.py
to see. Explain what went wrong in your module pdf.
Let's try another variation:
def print_search_result(A, search_term):
for k in range(len(A)):
if A[k] == search_term:
print('Found', search_term, 'at position', k)
else:
print('Not found:', search_term)
B = [15, 3, 23, 9, 14, 4, 6, 2]
print_search_result(B, 4)
print_search_result(B, 5)
3.12 Exercise:
Start by thinking through the execution to see if this worked.
Then, type it up in
my_search_example4.py
to see. Explain what went wrong in your module pdf.
We'll now see how a simple Boolean variable is commonly
used in these types of problems:
def print_search_result(A, search_term):
found = False
pos = -1
for k in range(len(A)):
if A[k] == search_term:
found = True
pos = k
if found:
print('Found', search_term, 'at position', pos)
else:
print('Not found:', search_term)
B = [15, 3, 23, 9, 14, 4, 6, 2]
print_search_result(B, 4)
print_search_result(B, 5)
3.13 Exercise:
First, trace through the above in your module pdf.
Then, type it up in
my_search_example5.py
and confirm.
3.14 Audio:
3.3 Returning a True/False value
Possible the most commonly use of Booleans is to write
a function that returns True or False.
Suppose we want to determine whether or not (Hint: whether or not
⇒ true or false) a list has a negative number:
def has_negative(A):
for k in A:
if k < 0:
return True
return False
B = [2, 4, 8, -10]
print(has_negative(B))
C = [1, 3, 5]
print(has_negative(C))
3.15 Exercise:
First, trace through the above in your module pdf.
Then, type it up in
my_search_negative.py
and confirm.
3.16 Exercise:
In
my_search_negative2.py
complete the function below to identify whether or not a list
has exactly two negative numbers:
def has_two_negatives(A):
# Write your code here
B = [2, 4, 8, -10]
print(has_two_negatives(B)) # Should print False
C = [1, -3, -5]
print(has_two_negatives(C)) # Should print True
D = [1, -3, -5, -7]
print(has_two_negatives(D)) # Should print False
3.17 Audio:
3.4 New topic: strings and slicing
It is common to want to pull out parts of strings.
For example, if the user in some application
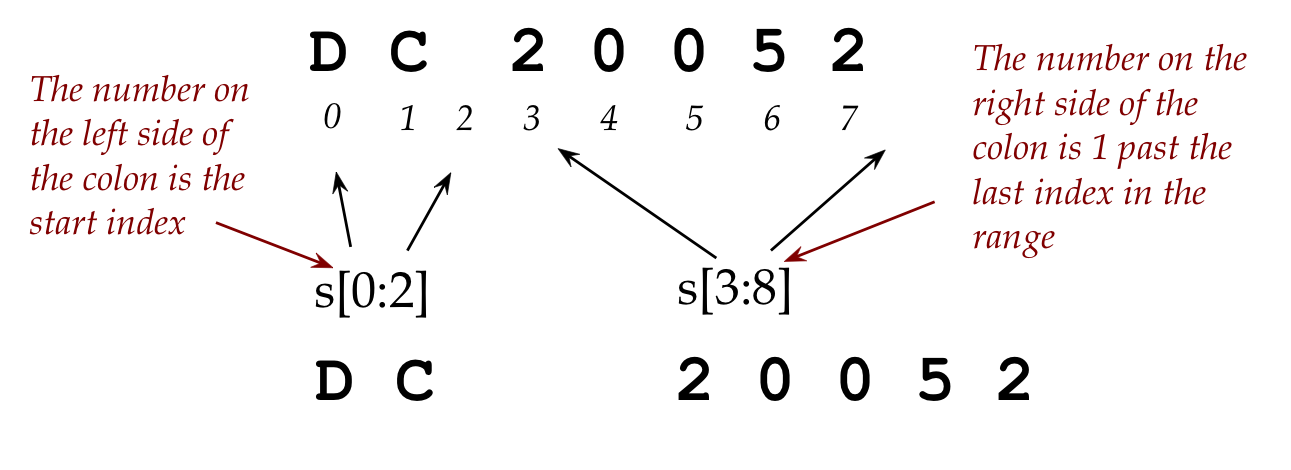
types 'DC 20052', we may want just the zip code:
s = 'DC 20052'
state = s[0:2]
zip = s[3:8]
print(state, zip)
Let's explain:
The slicing expression
0:2
refers to all the chars of the string from the first (the 0-th)
up to just before the one at position 2 (which would mean 1).
Thus,
0:2
refers to characters at positions 0 through 1.
Similarly,
3:8
refers to all the chars from position 3 upto 7 (inclusive).
Recall:
For any range of numbers like 3,4,5,6,7, exclusive would mean the
numbers 4, 5, 6 (excluding 3, excluding 7).
Inclusive would include the ends: 3,4,5,6,7.
Slicing ranges are specified so that the left end is
inclusive and the right end is exclusive:
Thus,
3:8
means "including 3" and "excluding 8".
3.18 Exercise:
In
my_slicing.py
write code to extract the actual phone number (202-994-4000)
from
s = 'phone: 202-994-4000'
# Write your code here
Slicing expressions work for lists too:
A = ['may','the','force','be','with','you']
print(A[2:5])
3.19 Exercise:
Before typing it up in
my_slicing2.py
try and guess what the above will print.
Let's look at slicing when we don't know the size:
Consider the zipcode example where the 5-digit zip code
may preceded by all kinds of text, as in:
'DC 20052'
'District of Columbia, 20052'
'20052'
'My zip code is 20052'
So, all we know is that the last 5 chars in the string need
to be extracted.
Then, we need to get the length of the string at the moment
we have the string.
3.20 Exercise:
In
my_slicing3.py,
write a function to extract the phone number in the same
way, when the first part could be anything like
"phone: 202-994-4000" or "my number is 202-994-4000".
Lastly, note that slicing has more to it than two numbers. We'll have
more to say about this in Unit-2.
3.5 Using slicing to solve a problem
Suppose we want to determine the longest prefix that
two strings have in common, as in:
print(find_common_prefix('river', 'rivet'))
This should print 'rive' but
print(find_common_prefix('river', 'stream'))
should find no common prefix.
We will use the following ideas:
Let an index variable start at 0 and increase in a loop.
For each value of the index, we'll compare the corresponding char
in each string.
As long as the chars are equal, we keep going (because these
will be part of the common prefix.
The moment they are NOT equal, we will have gone past the end
of the common prefix.
Let's try this:
def find_common_prefix(w1, w2):
for k in range(len(w1)):
if w1[k] != w2[k]:
break
return w1[0:k]
print(find_common_prefix('river', 'rivet'))
Let's point out:
The Python reserved word break is used to,
well, break out of a loop:
for k in range(len(w1)):
if w1[k] != w2[k]:
break
Thus, the moment it executes, execution exits the loop
to the statement that follows the loop.
Notice how we use slicing once we've found the char
that's past the common prefix:
return w1[0:k] # All the chars from 0 to k-1 inclusive
3.21 Exercise:
Does it work?
Trace the execution of the above in your module pdf
before typing it up in
my_prefix.py
to see.
3.22 Exercise:
Next, trace the executing when the strings
are 'riveting' and 'rivet'. What goes wrong?
Fix the problem in
my_prefix2.py.
3.23 Video:
3.6 Built-in string functions in Python
Python comes with many useful functions for strings.
Here's a sample:
A = ['to','infinity','and','beyond','and', 'even','further']
s = 'infinity'
# Convert to uppercase:
print(s.upper())
# Count occurrences of the char 'i' in s:
print(s.count('i'))
# Locate which index 'f' first occurs in s:
print(s.find('f'))
# Occurrences of 'and' in list A:
print(A.count('and'))
# Occurrences of 'i' in 2nd string in list A:
print(A[1].count('i'))
if A[3].startswith('be'):
print('starts with be')
data = '42'
print(data.isnumeric())
3.24 Exercise:
Type up the above in
my_string_functions.py
and pore over the output to try and make sense of how
the functions worked.
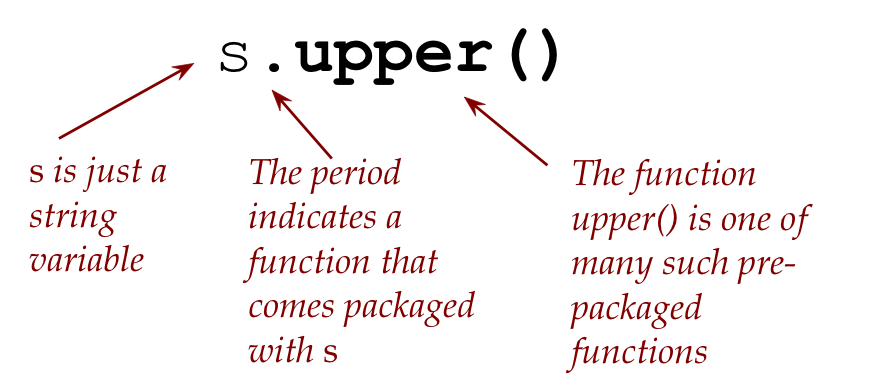
Let's explain:
There's a key difference, for example, between the functions
len()
and
upper():
s = 'hello'
k = len(s)
t = s.upper()
The function
len()
is like the ones we've been writing ourselves.
In this case, the string s is given to it as a parameter:
k = len(s)
But the function
upper()
is quite different:
t = s.upper()
This is, in some sense, attached to the
the string variable s.
The use of the period right after the variable followed
by a function is a somewhat advanced topic:
We'll just use the feature.
The advanced topic is called: objects.
(Yes. An ordinary name, but quite an involved topic, it turns out.)
Let's emphasize one more feature with this snippet of code:
s = 'hello'
t = s.upper()
print(s)
print(t)
3.25 Exercise:
Type up the above in
my_string_functions2.py
and observe the output.
Notice:
The string s itself did not change but its uppercase
version was returned by the call
t = s.upper()
This returns a new string that gets placed into t.
Continuing with the earlier example:
Similar "dot" functions are available for lists too, as in:
k = A.count('and')
This asks the list A to count how many times the string 'and'
occurs in the list.
The number that is returned gets stored in k.
Notice how we can call a "dot" like function in a string
when the string itself is an element of a list:
k = A[1].count('i')
Here,
A[1]
is the second string in the list A.
This happens to be 'infinity'.
We're calling its
count()
function.
And giving that function the letter 'i' to count.
It returns a number, which gets stored above in k.
Consider the following partially completed code:
def get_zipcode(A):
# Insert your code here
B = ['my','zip', 'is', '20052']
z = get_zipcode(B)
print(z+1)
3.26 Exercise:
In
my_string_functions3.py,
complete the function above, assuming the fourth string in the list
has the zipcode. Return a number not a string, so that the
print statement outputs 20053.
3.7 The concept of type
So far, we've seen different kinds of variables:
Integer variables like:
a = 100
b = 435
Floating-point variables for real numbers like:
c = 3.14159
d = 2.718
String variables like:
e = 'hello' # String with multiple chars
f = 'h' # Single-char string
Boolean variables like
g = False
h = True
We've also seen other kinds of features or "things"
in Python such as:
Reserved words.
Expressions, whether arithmetic, comparison, or Boolean.
Lists.
Functions that we write using
def.
Built-in functions like
len().
and
print().
Control structures like
for
and
if
that direct the flow of execution.
Ways to use existing other code via
import's.
There happen to other kinds of "things" in Python:
One of these is another kind of variable called a
complex
variable, for advanced math.
Another kind of "thing" or feature is an object
which is a kind of structure that can contain related variables
and functions.
Similarly, there are "things" called generators
and iterators (an advanced topic)>
What we want to do here is focus your attention on a
concept called type:
At any given moment, a variable is said to have a type.
What this means: what kind of value does it have at the
moment? An integer? A string?
Consider this:
x = 42 # The type of x is integer
y = 4.2 # The type of y is floating point
z = 'whoa' # The type of z is string
b = False # The type of b is Boolean
One can print the type of a variable as follows:
x = 42
y = 4.2
z = 'whoa'
v = False
print(type(x), type(y), type(z), type(v))
The type information is often itself represention in
a special Python feature called a class (intuitively, as in
this "class of item").
3.27 Exercise:
In
my_type.py,
find out what gets printed.
Thus, we see that:
A variable that holds 42 is rightfully an integer variable.
A number like 4.2 is a floating-point number (what we've
also called a real number), and so a variable that holds such
a number is a floating-point variable.
A string variable that holds 'whoa' is just that, a string variable.
And a variable that holds True or False is called
a Boolean variable.
Converting from one type to another:
It is often useful to go from one type to another.
We've seen an example of going from single-char string
to integer, and converting from int to string (and vice-versa).
To review, let's look at a few more examples:
a = int(4.2)
b = float(42)
c = str(b)
d = int('256')
e = ord('z')
f = chr(97)
print(a, b, c, d, e, f)
3.28 Exercise:
Type the above in
my_type2.py,
to see how it works.
Types and operators:
Because our keyboards are limited in the number of symbol keys,
we need to use some symbols for multiple purposes.
The way we see this is when one operator, like +, has
different meanings when used with different types:
a = 3
b = 4
c = a + b # + for arithmetic
d = 'hello'
e = 'world'
f = d + ' ' + e # + for string concatenation
Rather than list all possible uses of all operator
symbols, we will introduce additional uses beyond the common case
wherever appropriate.
Generally, you should be intentional about using
operators: you should know what the purpose is.
For example, consider:
a = 4
b = a * 3
print(b) # prints 12
d = 'hello'
e = d * 3 # * for string concatenation
print(e) # Prints hellohellohello
(The latter is not a frequently used operator with strings.)
3.8 A text application
Sometimes we need to go beyond what Python has to offer.
One way to do this is to find a popular library and
use that:
What's a library?
A library is a collection of programs all related
for a purpose.
For example, there's a library called NLTK (go look it up)
that's aimed at processing English text:
It can figure out parts of speech from sentences.
It can pick out topics (somewhat approximately) in paragraphs.
It can group so-called stem-related words like
"fry", "fries", "frying" and separate those from "friar".
However, installing and learning to use these sophisticated
packages requires some work.
What we will do instead in this course is to provide you
with simple programs that you can download and use directly
without any installation.
This is the purpose in providing programs like wordtool and
drawtool.
Let's use wordtool to find the longest sentence in a book:
Wordtool has a feature to break down text and give you
one sentence at a time.
For example:
import wordtool as wt
sentences = wt.get_sentences_from_textfile('jabberwocky.txt')
count = 0
for s in sentences:
count += 1
print('Sentence #', count, ':\n', s, '\n', sep='')
3.29 Exercise:
Type the above in
my_sentence_app.py,
to see how it works. You will need to download
wordtool.py,
wordsWithPOS.txt,
and the sample text file
jabberwocky.txt
all into your module folder.
You are likely to be familiar with the author's other famous works.
Let's point out:
When using functions in another program, one has to
import
that program:
import wordtool as wt
It is convenient to use a shorthand for an imported program:
import wordtool as wt
(We could have called it something other than wt).
3.30 Exercise:
What is the purpose of \n and what does sep='' do?
You can look this up and try removing those in
my_sentence_app2.py.
Let's now do something interesting with wordtool:
find the longest sentence (by length) in two
texts to compare who wrote really long sentences.
import wordtool as wt
def get_longest_sentence(filename):
sentences = wt.get_sentences_from_textfile(filename)
maxL = 0
for s in sentences:
if len(s) > maxL:
maxL = len(s)
maxS = s
return maxS
book = 'federalist_papers.txt'
s = get_longest_sentence(book)
print('Longest sentence in', book, 'with', len(s), 'chars:\n', s)
print()
book = 'darwin.txt'
s = get_longest_sentence(book)
print('Longest sentence in', book, 'with', len(s), 'chars:\n', s)
3.31 Exercise:
Type the above in
my_sentence_app3.py.
Then download
darwin.txt
(Darwin's On the Origin of Species)
and
federalist_papers.txt
(the Federalist Papers by Hamilton and others).
Which one has the longest? Who wrote the longest sentence
in the Federalist Papers? Go to
Project Gutenberg
and find a text with a longer sentence. Report all of this
in your module pdf.
3.32 Audio:
3.9 When things go wrong
In each of the exercises below, first try to identify the error
just by reading. Then type up the program to confirm, and
after that, fix the error.
3.33 Exercise:
def is_odd(k):
if k % 2 == 1:
return true
else:
return false
Identify and fix the error in
my_error1.py.
3.34 Exercise:
x = 4
if x >= 0 and <= 5:
print('x is between 0 and 5 inclusive')