CSCI 1111
Introduction to Software Development, Spring 2024
GWU Computer Science
Introduction to Software Development, Spring 2024
GWU Computer Science
In this project, you will write a Java program that will analyze a dataset of tweets. There are two basic tasks that we'll accomplish:
Unlike previous assignments in this class, this project is a lot more open-ended with fewer instructions: implementation details are left to the students. You may NOT use any outside resources (webpages, ChatGPT, LLMs, tutors, friends, YouTube, TikTok, etc) for this project -- doing so is an honor code violation! You may only use syntax we learned in this course this semester, except in cases below (like Part 1) where we explicitly encourage you to look up resources online (and you need to cite these). You may only work with your partner. You may NOT work with groups of other people in lab/office hours. TAs will only help one group at a time -- start your projects early and make use of Ed. You should never be looking at code that isn't yours or your partners. If you have any questions, please post to Ed. This project is a small, but realistic research project on a real-world dataset, and is meant to be fun and give you an idea of some of the interesting applications of the ability to program and process data.
Because so much of the implementation is left up to you to figure out, we are devoting class time this semester to work on the project together, as we're also looking forward to your questions on Ed!
While you're working on this project, remember to have FUN! If you're stuck on the same thing for 15 minutes without making any progress, please raise your hand in class or message us on Ed!
The dataset we'll be using is a Twitter dataset automatically collected by researchers and made available through Kaggle.com. The original dataset is very large, so we suggest you use the shorter version we created (with only 10K entries), available as a pinned thread on Ed.
WARNING: the Twitter dataset was automatically collected by researchers using the TwitterAPI; as such, it has not been screened nor sanitized to remove potentionally offensive and/or objectionable material. We are not condoning nor endorsing any of the material in the dataset by using it in this project. If you have concerns about viewing this material, please speak to the professor immedaitely so we can arrange for an alternative assignment
The dataset can be downloaded from the pinned post on Ed.
Use a text editor or MSExcel to open the test dataset and take a look at the file format -- we will be extracting the
tweet itself, the username, and the timestamp of the tweet for our analysis. Notice that the file is in a csv
(comma separated variable) format.
Next, copy the code below into a file called DriverPart1.java, and add in code to open the csv you downloaded, read it in line
by line, and add its contents to a StringBuffer object (which you can think of as a really long String!). We have
given you some starter code for how to add something to this StringBuffer. Practice using Google to find a way
to read in a file, line-by-line, using a while loop, and add each line to your StringBuffer. Make sure to cite the URL of the resource. As a warning, most likely
the code to do this requires you using a try-catch block to handle exceptions; we haven't learned about this yet
in class, so please feel free to post questions to Ed if you need help. If you get a compilation error around the code you use
to open a file, make sure that you have a try-catch block around those lines. Finally, you'll want to add in a newline character each
time you read in a line in order to pass the tests. You can compile and run this file to see if your code opened and ingested the input csv.
// you may need some imports here!
public class DriverPart1{
public static StringBuffer readTwitterData(StringBuffer contents, String path){
// you'll want to use the line below (after modifying it) inside
// your while loop for each row of the dataset
contents.append(...);
return contents;
}
public static void main(String[] args){
String path = "covid_10K.csv"; // fill in this line with the correct path
// do not modify the lines below
StringBuffer contents = new StringBuffer();
readTwitterData(contents, path);
System.out.println(contents);
}
}
SentencePart1 classNext, let's write a class called SentencePart1 that has at least the following methods:
public SentencePart1(String text, String author, String timestamp): a constructor that sets three fieldspublic getters and setters getText, setText, getAuthor,
setAuthor, getTimestamp, and setTimestamp, with argument and/or return types
matching those passed in to the constructor.public String toString(): returns a human-legible string representation of the current object in the format
{author:kinga, sentence:"Hello CSCI 1111!", timestamp:"May 11 2009"}Save your class in a file called SentencePart1.java.
You can test your two files by
running the Part1Tester.java file in the same directory. This will also tar up your
solution for submission.
When you have finished, upload your Part1.tar solutions to the submitserver -- both group members should upload the solution. Please
make sure to do this by the deadline (4/11 at 11:59pm). If you finish this project early in this lecture, move on to
Part 2 below.
Make a copy of your SentencePart1.java file and save it as SentencePart2.java (and update the constructor). We'll need to write code that is able to extract the three
pieces of data we want from each tweet: the tweet, the author, the timestamp of the tweet.
In order to processes the sentences from the file, add a method in SentencePart2.java called public static SentencePart2 convertLine(String line) that converts a line
from the input file into a SentencePart2 object that it returns. This method should perform all the
preprocessing necessary for the toString method to easily print out the three fields without
any additional processing -- we describe the details below.
In your while loop that reads in a line of the csv, you'll need to write code to split the line by commas to extract the
three desired pieces, store them in a SentencePart2, and add that sentence to your ArrayList.
This code to process a line of the csv will be used by the convertLine method you'll write in a bit; you can scroll below to see how it is declared; here, we will explain what most of its content will look like.
For example, the second line of our
input file is
0,61,4/19/2020 0:00,,makinwaoluwole,OGSG_Official,Nigeria,ogun state support cbn nirsal covid19 target credit facil tcf
and you should extract three pieces as:
April 19 2020
makinwaoluwole
ogun state support cbn nirsal covid19 target credit facil tcf
There will always be eight pieces, separated by commas, in each input line. Some of these pieces can be empty (a string of length zero).
There is an issue, however, when the line in the input file contains an entry with a comma inside of it, for example:
0,31,4/19/2020 0:00,,RJIshak,"GlblCtzn, priyankachopra",Jakarta Capital Region,call leader help protect refuge covid19 provid qualiti health care
Here, you cannot just use commas to split over the line because the term "GlblCtzn, priyankachopra" is not supposed to be broken up -- this is what
the double quotes indicate. Instead, you will need to come up with an algorithm to handle these pieces that are surrounded by double quotes.
You'll also need to process
the timestamp to retain just the month, day, and year. In other words, you'll need to convert 4/19/2020 0:00 to be April 19 2020. Think about what you could split over to
get the right pieces here.
Finally, make a copy of your DriverPart1.java and save the new file as DriverPart2.java. You'll need to connect the method above to your readTwitterData method, so that the input can be processed, line-by-line,
into an ArrayList of SentencePart2 objects (you've already set that loop up). Modify the readTwitterData method to return an ArrayList of SentencePart2 objects, instead of a StringBuffer, in the new file. Store each sentence as an object in the ArrayList, using generics to
indicate the correct type of object stored. We no longer need the StringBuffer, so remove it as an argument to that method. Replace your main method with the code below to get it to work with the changes:
public static void main(String[] args){
String path = "covid_10K.csv"; // fill in this line with the correct path
ArrayList result = readTwitterData(path);
for(int i = 0; i < result.size(); i++)
System.out.println(result.get(i));
}
You can test your SentencePart2 and DriverPart2.java by
running the Part2Tester.java file. However, in order to debug your code and find out what went wrong, you need
to use print statements to print out the relevant variables involved in how the code checks for the correct answer to gain insights on what to fix; we will ask
to see the output of these debugging print statements when we help you in office hours/Ed. You cannot just look at your code (or ask us to look at your code) and "think hard" about what to change. Feel free to ask the instructional staff to walk you through how to use print statements to debug.
When you have finished, upload your Part2.tar solutions to the submitserver -- both group members should upload the solution. Please
make sure to do this by the deadline (4/18 at 11:59pm). If you finish this project early in this lecture, move on to
Part 3 below.
As we just saw, dataset identification, collection, and pre-processing can be one of the most difficult parts of
a research project! Now that we have our sentences and their metadata neatly placed into an ArrayList
of sentence objects, the fun (and easier) part can start!
Make a copy of your SentencePart2.java file and save it as SentencePart3.java (and update the file accordingly). Also make a copy of your DriverPart2.java and save the new file as DriverPart3.java. Make sure your update your driver to use the new sentence.
For this section, we want to know what are the most common topics across all of our sentences. Taking this pulse could have a number of real-world applications; for example, people have studied tweets about COVID to try to track new outbreaks that happened in 2020, before the widespread availability of PCR tests, by looking at what symptoms were being reported in which locations.
Here, we're going to work on splitting up sentences into words, doing a little cleaning, and then making a list of the most common individual words or phrases across our dataset.
First, let's modify your SentencePart3 class to add a method that takes the text of the sentence,
and returns an String[] that contains the words in the sentence (we'll define a word as something that is separated by a space -- you don't need to worry about punctuation; in fact, you may have already noticed that the tweets have been cleaned by using stemming). You should reuse the code you wrote for the last problem in Homework8 here; make it a method of the SentencePart3 class called splitSentence() that no longer takes arguments and instead
operates on the text stored in the class.
Next, write a method called public static HashMap<String,Integer> getTopWords in your DriverPart3 that
takes as argument an
ArrayList of SentencePart3s, extracts the words for each sentence, and updates a HashMap object that keeps track of
how many times each word appeared in the entire dataset. Note that you must store Integers in the HashMap,
not ints, so you should declare it as HashMap<String, Integer>.
Once you have written that code, call it in your readTwitterData method to obtain the HashMap of word counts; return this HashMap instead of the ArrayList. Then,
copy the code below into your main method to have it loop through the HashMap and print out all its entries:
ArrayList<String> results = new ArrayList<String>();
for(int i = 0; i < YOUR_HASH_MAP.keySet().toArray().length; i++){
int count = YOUR_HASH_MAP.get(YOUR_HASH_MAP.keySet().toArray()[i]);
String num = "" + count;
while(num.length() < 5)
num = "0" + num;
results.add(num + " of "+ YOUR_HASH_MAP.keySet().toArray()[i]);
}
Collections.sort(results);
Collections.reverse(results);
for (int i = 0; i < results.size() && i < 100; i++)
System.out.println(results.get(i));
Once again, we'll cover what this code does in CSCI 2113! In the meantime, you'll need to modify the code
above to change YOUR_HASH_MAP to whatever you called your HashMap variable.
Run your main method to see if it works!
Next, add the line of code into your SentencePart3.java file regardless of whether or not you plan to do the extra credit below (otherwise your code won't compile):
public String[] splitSentenceBigram(){ return null; }
healthcare has been split up into health and care; this makes it harder
to distinguish "health" (a status of a person) versus "healthcare" (the care of a person). For extra credit, copy your splitSentence() into a method called splitSentenceBigram() that, using the text file of English words here, finds all bigrams in the tweets and replaces them with the single word (so "health care" becomes "healthcare" because the latter is in that list).SentencePart3.java file, and make sure you save the list above in the same
folder with the filename words_alpha.txt:
import java.io.*;
private static ArrayList dictionary = null;
private static ArrayList getDict(){
if (dictionary == null){
dictionary = new ArrayList();
try{
//open the csv file for reading
File file = new File("words_alpha.txt");
BufferedReader reader = new BufferedReader(new FileReader(file));
String line = null;
//loop through each line in the csv
while ((line = reader.readLine()) != null){
dictionary.add(line);
}
}catch(Exception e){
e.printStackTrace();
}
}
return dictionary;
}
ArrayList; you can then access this object inside your splitSentenceBigram() with the expression:ArrayList dictionary = getDict(); You can test your files (including the extra credit) by running the Part3Tester.java file.
When you have finished, upload your Part3.tar solutions to the submitserver -- both group members should upload the solution. Please
make sure to do this by the deadline (4/22 at 11:59pm). If you finish this project early in this lecture, move on to
Part 4 below.
People are often interested in monitoring trends in natural language datasets, and one way to do that is to measure how positive or negative a sentence might be. For example, an automated mental health chatbot could be trained to monitor a conversation, and look for indicators of increasing depression. This sort of analysis is often extended to tweets, reddit posts, and other social media.
In this section of the project, we're going to learn how to install and use a Java library that will allow us to measure the sentiment (positive or negative emotion) in a sentence.
Make a copy of your SentencePart3.java file and save it as SentencePart4.java (and update the file accordingly). Also make a copy of your DriverPart3.java and save the new file as DriverPart4.java. Make sure your update your driver to use the new sentence.
In order to allow our Java code access to libraries that are not a standard part of Java, we need to download
these libraries and make sure that our Java program knows how to find them. We can download these files by pasting the
urls below into your browser:
https://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
https://nlp.stanford.edu/software/stanford-english-corenlp-2018-10-05-models.jar
It will take several minutes to download these files --
please read ahead and study the code below while you're waiting.
Next, copy both files into the same directory where your Java files are. Extract the contents of the .zip file using the terminal commands (if the
first command doesn't work, you can unzip the way you would normally unzip files):
unzip stanford-corenlp-full-2018-10-05.zip
cd stanford-corenlp-full-2018-10-05
cp ejml-0.23.jar ..
cp stanford-corenlp-3.9.2.jar ..
cd ..
Make sure the .jar files end up copied into the same directory as your Java files.
Now that we've downloaded the Stanford CoreNLP libraries (note that they are files that end in .jar, which
stands for "java archive"), we can import these libraries at the top of our SentencePart4.java:
import java.util.Properties;
import org.ejml.simple.SimpleMatrix;
import edu.stanford.nlp.ling.CoreAnnotations;
import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations.SentimentAnnotatedTree;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.util.CoreMap;
In a minute we'll show you how to let the Java program that tries to run this file know where these libraries live on
your machine.
Next, add the code above at the top of your SentencePart4.java. Then, also add the code below
that defines a method that is able to score a sentence for sentiment using the library we just downloaded:
public int getSentiment(String tweet){
try{
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, parse, sentiment");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
Annotation annotation = pipeline.process(tweet);
CoreMap sentence = annotation.get(CoreAnnotations.SentencesAnnotation.class).get(0);
Tree tree = sentence.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
return RNNCoreAnnotations.getPredictedClass(tree);
} catch (Exception e){
return 0;
}
}
Let's go through what the pieces above are doing. Properties are flags that users can set to determine
what processing steps to apply to the sentence. Here, you can see where those properties are set with
setProperty, where a string is passed in contains different types of processing the sentence will be subject to.
In this case, you may recognize sentence splitting steps (tokenization) like we did manually above. You'll see the
last argument set here is sentiment, which instructs the library to return a sentiment score between 0
and 4 for the sentence
as either 0=Very Negative, 1=Negative, 2=Neutral, 3=Positive or 4=Very Positive. Sentiment analysis, like our topic modeling,
also requires that raw sentences are tokenized and pre-processed in order to make its judgements.
The library is called by creating a pipeline object, which passes the tweet though the processing
steps we just outlined. At the end of that, the next three lines of code are taking the processed sentence (recall,
it no longer looks like a human visible sentence) and passing it through a machine learning algorithm that has been
trained elsewhere in the library to try to guess what the sentiment of this particular sentence was. Pretty cool, and
all just in a few lines of code!
Now, we're ready almost ready to use this code to score sentences. First, since the getSentiment method lives
in the SentencePart4 class, it doesn't need an argument: change the method to operate on the text
field of the SentencePart4 class instead.
Next, in your driver, write a method called averageSentiment that takes an ArrayList of sentences and returns the average sentiment of all the sentences in that list (as a double). Then, call that method from your main method and print out this average score (you can comment out the top-words code in main if you wish). The sentiment calculation is quite slow; it will take a few minutes/hours to run even on our small dataset, and it also can't handle malformed data in our dataset. Therefore, in main, only print out the sentiment of the first 100 rows in the csv. You can also ignore the debugging output from the sentiment analysis code (there is no way to remove this).
You'll need to compile and run this part of the project from your terminal. First, open a terminal window, and change directory into the folder where your java files are (see the notes from lab the first two weeks of class for a refresher of how to use the terminal if needed). All three java files must also be there; you should check this by doing ls or dir from that directory. Your terminal should have all the listed files there, including the three jar files:
Finally, in order to run your code, you need to make sure that the .jar files we downloaded earlier are in a place
where Java can find them. There are many ways to set this up elegantly, but for now we'll just point the javac and java
programs to the paths of three .jar files the code above needs to run. Try the command below that applies to your operating system;
if it doesn't work and you've verified that all the files are in the current directory, see the part below for instructions on
how to unpack the .jar files and get it working:
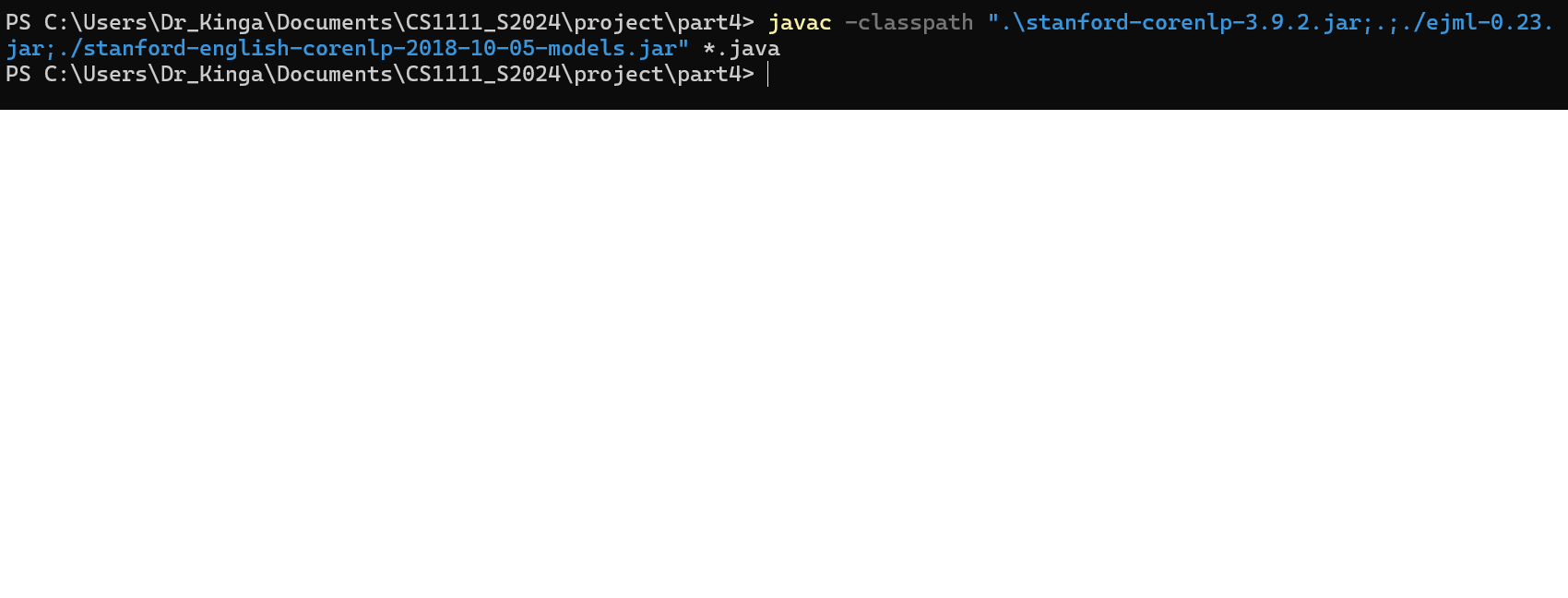
javac -classpath ".:./ejml-0.23.jar:./stanford-corenlp-3.9.2.jar:./stanford-english-corenlp-2018-10-05-models.jar" *.java for Mac/linux, or
javac -classpath ".\stanford-corenlp-3.9.2.jar;.;./ejml-0.23.jar;./stanford-english-corenlp-2018-10-05-models.jar" *.java for Windows.
and then
java -classpath ".:./ejml-0.23.jar:./stanford-corenlp-3.9.2.jar:./stanford-english-corenlp-2018-10-05-models.jar" DriverPart4 for Mac/linux, or
java -classpath ".\stanford-corenlp-3.9.2.jar;.;./ejml-0.23.jar;./stanford-english-corenlp-2018-10-05-models.jar" DriverPart4 for Windows.
If you want to run the tester, you'll need to use the syntax above as well. You'll learn more about the classpath in upper level courses as well.
When you have finished, upload your solutions to BB -- BOTH GROUP MEMBERS should upload the solution. Please upload your Part4 java files only -- do not upload the jar files or the csv, as these are large files and take a while for us to download. Please make sure to do this by the deadline (4/22 at 11:59pm).
We now have a way to find the major themes/topics of a group of sentences, as well as the ability to
analyze the sentiment of these sentences. Next, we're going to have you write some code to be able to
filter your ArrayList of sentences to interesting subsets.
Make a copy of your SentencePart4.java file and save it as SentencePart5.java (and update the file accordingly). Also make a copy of your DriverPart4.java and save the new file as DriverPart5.java. Make sure your update your driver to use the new sentence.
First, define and implement a method in the SentencePart5 class called public boolean keep(String
temporalRange) that returns true or false depending on whether or not the
SentencePart5 object is within either a date range such as "May 31 2009-Jun 02 2009"
To get some practice with real-world programming and debugging, we recommend you use built-in Java libraries to convert
each date (that's a string) into an integer (long) where you can compare that one date is less than
and/or greater than another. These libraries often convert dates into the number of seconds since an arbitary date in the past,
so you can compare them with the less than and greater than operators, like normal integers. You can google (or use) any way
you'd like to make this conversion (just make sure to cite what you found!), but here are some examples:
Timestamps. SimpleDateFormat class to use in the solution above or ones like it;
check out its API to see how you can provide an expression for the format your dates are in.Timestamp object for each date, you can use its methods in its API to convert the timestamp into
the number of seconds.try-catch block to handle exceptions.Next, modify your code in main to use the keep method to generate a new
ArrayList that filters out tweets or sentences to just those in the temporal range specified.
Finally, using all the code you've written for this project, plan and then execute a further analysis of the dataset that answers one or more of the following potential questions, and/or investigates something similar (check with the instructor if you want to deviate from this list):
keep method that is able to filter out out sentences based on keywords,
rather than temporal ranges. Generate a bar chart of average ratings over certain keywords.keep in main to run your tests. If you are running multiple
experiments, please comment out (rather than delete or overwrite) the code you used for different tests. Using an LLM for the written part of this project is not allowed. The code you submit for Part5 must run the experiment(s) you describe in your writeup.
When you have finished, upload your solutions to BB -- BOTH GROUP MEMBERS should upload the solution. Please upload your Part5 java files, as well as a PDF of your writeup -- do not upload the jar files or the csv, as these are large files and take a while for us to download. Please make sure to do this by the deadline (4/29 at 11:59pm).
keep has been correctly implemented to handle a temporal range and/or a keyword | 1 points |
main has been correctly modified to generate filtered ArrayLists using keep. | 1 points |
| The motivation for your analysis is clearly communicated and is convincing | 1 points |
| The hypothesis for your analysis is clearly communicated and is testable | 1 points |
| The metrics chosen for your analysis are appropriate for your hypothesis | 1 points |
| The experimental design for your analysis is clearly communicated and would answer the hypothesis question | 1 points |
| The explanation of how you modified your code for your analysis is clearly communicated | 1 points |
| The discussion of experimental results for your analysis is clearly communicated, and convincingly explains why your results would or would not generalize past this dataset. | 5 points |
| Any additional (instructor approved) analysis has been completed, and a paragraph summarizing the results with metrics was provided. | 5 points per analysis (extra credit) |
Great work on this project! If you're interested in learning more about Natural Language Processing, including
doing research with Dr. Kinga during the regular semester, feel free to drop her an email!
Otherwise, take a break before studying for finals! [There is no final in this class -- you're all done! :-)]