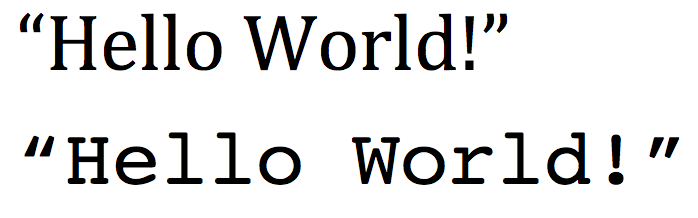The standard QWERTY keyboard is limited in the number of
symbols it can offer.
One result is that there is a single special symbol for
the double quote, "
But real text actually features separate symbols for
opening a quote (“) and for closing (”).
Note: some browsers may not distinguish so we'll
emphasize with a picture:
The first example features different double-quotes for
opening and closing.
The second has the standard keyboard double quotes (same
for opening and closing).
Suppose we are analyzing a text file with non-keyboard
characters. We need to be able to deal with them.
We learned earlier how to read a file a character at
a time.
Use this to determine the integer values of the chars
for opening/closing double quotes.
Step 2: Dialogue analysis
We will now develop an application that analyzes text (novels) to
study these questions:
How much of the text is dialogue?
What is the statistical nature of the dialogue? That is,
what does the histogram of dialogue lengths look like?
The larger questions of interest (which we won't answer here)
are: do authors or particular periods show dialogue-size patterns?
Let's start by simply counting the number of characters
within quotes (dialogue) versus not.
4.2 Exercise:
Think about this for a moment and try and write down
pseudocode to solve this problem before seeing the solution
below.
Also, write some hackneyed dialogue for an exercise below.
OK, let's take a closer look:
Think back to the days when you learned to read by moving
your finger along text. Yes, a long time ago.
We'll use this idea to ask the question: as you move
your finger, stop momentarily when you are on either an
opening or closing quote.
When you hit an opening quote, say to yourself "quote begins".
When you hit a closing one, say "quote ends".
For any other character, say either "in quote" or "out of quote".
(because one or the other must be true).
Try this with the hackneyed dialogue you wrote above.
We'll build on this idea to know, at any given moment
in the scan of text, whether we are "in quote" or "out of quote".
Here is pseudocode:
k = getNextChar ()
state = outofquote // Assume initially out of quote.
while (k >= 0) {
if state == inquote {
// Because we're in quote, seeing the close-quote changes state
if k is close-double-quote {
state = outofquote
}
}
else {
// We're out of quote.
if k is open-double-quote {
state = inquote
}
}
k = getNextChar ()
}
Try out the above pseudocode with your dialogue.
What we need to do next is modify the above to
also count the total number of in-quote chars vs. out-of-quote chars.
4.3 Exercise:
Download
DialogueAnalysis.java
and apply the above pseudocode, along with code for
counting the number of chars with quotes (dialogue) vs. not
in quotes.
Then, download and change the text file to get the numbers for
alice.txt
and
sherlockholmes.txt.
4.4 Audio/Video:
Step 3: Statistical analysis of dialogue
What we'll do next is analyze the statistics of the lengths
of dialogue: how long are bursts of dialogue? what does the pattern
look like?
Let's begin by recording the length of each bit of dialogue:
We will add a counter to increment each time we're in a
quote and scan a char.
Then, when a quote ends, we'll have the length of that
quote.
We will simply add these lengths to an arraylist.
After the whole file is scanned, we will have the raw data:
an arraylist containing the lengths of all the dialogues.
The next step will be to get a histogram of this data:
How many dialogues are of length 1?
How many dialogues are of length 2?
...
We will do this by analyzing the arraylist.
Finally, we'll plot the histogram.
4.5 Exercise:
Download
DialogueAnalysis2.java
and fill in the necessary code. You will also
need DrawTool.java.
Try it out on the
dialogue you created.
Let's explain a few details for the above exercise:
As you can see, there are three steps to the whole process:
static ArrayList<Integer> quoteData;
public static void main (String[] argv)
{
// First analyze the text to pull out the dialogue-length data.
analyzeText ("alice.txt");
// Build a histogram:
int[] histogram = makeHistogram (quoteData);
// Then plot.
plotHistogram (histogram, 100);
}
Add your code from earlier to the
analyzeText()
method. This is where you track whether you are "in quote" or not,
and to count the length of a quote.
Next, consider the histogram:
We want
hist[i]
to have the number of dialogues of length i.
To do this, scan through the arraylist and increment
the appropriate entry of the
hist
array.
The rest of the code is written for you.
4.6 Exercise:
Complete the code and plot the histogram for both
alice.txt and sherlockholmes.txt. What is the difference
in patterns between the two?