- Given an adjacency-list representation of a directed graph, explain how
you would (give high-level pseudocode):
- Compute the out-degrees of all vertices.
- Compute the in-degrees of all vertices.
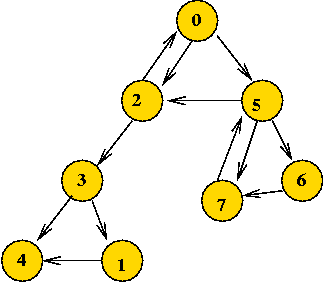
- For the following directed graph, write down:
- The adjacency-matrix.
- The adjacency-list.
- Show the results, step by step, of depth-first search starting at vertex 0 (draw the tree edges, visit-order and completion-order). Use the depth-first version that visits all components.
- Classify the non-tree edges (back, down, cross) by clearly drawing them on a separate graph.
- Identify the strong components on the graph.
- Draw a new graph that replaces each edge below with an undirected edge, and removes redundant edges so that no pair of vertices has more than one edge connecting them. Now, show the results of applying breadth-first search to this new graph.
- Module exercise 7.9.
- Module exercise 7.13.
- Give an example to show that a vertex v in a directed graph can end up in a depth-first tree containing only v even if v has both incoming and outgoing edges in the graph.
- Name your file UndirectedDepthFirstAdjList.java.
- You will need to implement the UndirectedGraphSearchAlgorithm
interface:
- Simply implement the initialize(), insertUndirectedEdge(), depthFirstVisitOrder(), depthFirstCompletionOrder(), componentLabels() and numConnectedComponents() methods.
- Provide empty implementations for the other methods.
- Note: when you insert a new edge into an adjacency list, always add it to the end of the list. Unlike an adjacency-matrix representation, this matters, because the visit-order depends on the list order for each vertex (the order in which neighbors are explored).
- The javadoc for this exercise:
UndirectedGraphSearchAlgorithm interface
GraphEdge class - A class called GraphEdge has been provided (in the environment) for your use in the vertex lists. However, you may choose to use some other class of your own making, if you find that convenient.
- Note: the componentLabels are explained as follows. Since DFS identifies components, we will label these component 0, component 1, ... and so on. Now vertex 5 may happen to lie in component 1 in which case its componentLabel is 1. Similarly, vertex 12 may lie in component 3, in which case its componentLabel is 3. Thus, the array componentLabel specifies for each vertex which component that vertex lies in, i.e., componentLabel[i] is the component number for vertex i.
- Use this properties file for testing in the algorithm environment. Note: currently, the environment only tests correctness of algorithms that meet this interface; a performance tester is in development.
- We use a biased coin where the probability of getting "heads" is p, where p may or may not be 0.5.
- Initially, there are only n vertices and no edges.
- For each pair of vertices, flip the coin to decide whether or not an edge should exist between those vertices.
Note:
- There is no interface to implement.
Write your code for this part in RandomGraph.java so that this program, when compiled and executed does the following:
- It will loop through different values of p.
- For every value of p, you will generate a 1000 random graphs and estimate how many are one-component graphs, and calculate the fraction.
- RandomGraph.java should print to the terminal, this fraction, one for each p.
- You are required to use your implementation of DFS (the adjacency-list version) above.
- How do you flip a biased coin whose probability of heads is p?
You can use the following code:
public static boolean randomCoinFlip (double p) { if (UniformRandom.uniform() < p) return true; else return false; }You can get UniformRandom from here. Suppose you want to randomly generate edges with an unbiased coin (i.e., p = 0.5. Each time you call randomCoinFlip with p=0.5 you'll get true (if the flip is heads) or false (if not). - Submit a graph (PDF) plotting the "probability the graph is connected" against different values of p. Do this once for a graph with 10 vertices and once for a graph with 20 vertices.