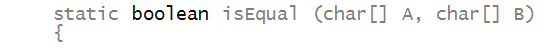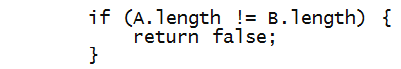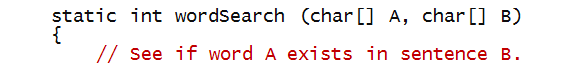Problem solving, using computer programming of course,
is the quintessential skill in computer science.
It is also a vague, slow to acquire skill that takes time and patience.
And with lots of examples, and practice.
What exactly does this mean how is it different from programming?
A programming or coding task generally assumes the task is
carefully and narrowly specified.
For example: write a method that examines an array of
numbers to see if it has any zeroes.
In problem-solving, on the other hand, you are given a
broader problem to solve, with very little specification about
code.
For example: how many English words are palindromes?
The goal of problem solving is turn a high-level task into
a series of smaller programming tasks.
It's easier said than done. At the same time, there are
ways to structure your thinking to help with problem-solving.
And working through example problems is really the best way
to build problem-solving ability.
Three underlying themes pervade problem solving:
How is the data stored and accessed? (Or, what variables
are needed, which need to be global, and so on.)
What methods will be useful to define and use?
What does one need to understand about the application
domain?
The last point is worth elaborating:
Most software is written for real world applications
in domains outside of computer science such as:
business, medicine, law, social media, games, education.
To write such software, one often needs to spend a little
time understanding the domain of interest.
For example, to write software that handles, say,
spreadsheets, one would need to understand standard
spreadsheet calculations.
Thus, applied computer science is unusual in that it
requires effort spent in delving into the details of application
domains.
But this what makes developing applications interesting.
For example, we will below learn a little about
cryptography and biology. Just enough to write our applications.
By the end of this module, for simple programs, you will be able to:
Appreciate the power of problem solving.
See how larger tasks translate into smaller programming tasks,
most often, into well-defined methods.
"Looks like I'll need to define an array variable ..."
Instead, let's use a higher-level approach:
See if a simpler version of the problem can be posed.
Then see if that can be used or modified easily.
In this case, a simpler version might be: identifying whether
or not a char array (without spaces) is a palindrome.
Furthermore, suppose this sub-problem is already solved. That is,
we have a method, say, that does this:
static boolean isPalindrome (char[] letters)
{
// Assumption: letters has no spaces
// ... some code ...
}
Can we now solve the larger problem? We will use these steps:
1. Make a new array with the spaces removed.
Thus "never odd or even" will become "neveroddoreven"
2. Then call our already written isPalindrome() method.
Is the first step straightforward? Here are some issues:
How do we know the size of the second array (without spaces)?
⇒
It's the length of the former minues the number of spaces.
How do we know how many spaces there are in the original?
⇒
We can do a count (for-loop) looking for spaces.
So, a slightly more detailed higher-level approach is:
1. Make a new array with the spaces removed.
1.1 Count the number of spaces in the array.
1.2. Use this to determine the size of the new array.
1.3. Make the new array.
1.4 Copy over the non-space characters from the old to the new.
2. Then call our already written isPalindrome() method.
We can now begin to outline some code.
First, in main:
public static void main (String[] argv)
{
// Data:
char[] sentence = {'n','e','v','e','r',' ','o','d','d',' ','o','r',' ','e','v','e','n'};
// Step 1: create a new array with spaces removed:
char[] withoutBlanks = removeBlanks (sentence);
// Step 2: apply the usual palindrome checking:
if ( isPalindrome (withoutBlanks) ) {
System.out.println ("Yup, it's a palindrome alright");
}
}
Now let's flesh out the space removal a little:
static char[] removeBlanks (char[] A)
{
// 1.1 Count the number of spaces.
// 1.2 Calculate the size of the smaller array.
// 1.3 Make the new array.
// 1.4 Copy over the non-space chars from the old to the new.
}
Notice how we've merely copied over the high-level approach
as comments.
It is now much easier to do each one of these one by one.
Here's the method
removeBlanks:
static char[] removeBlanks (char[] A)
{
// 1.1 Count the number of spaces.
int numBlanks = 0;
for (int i=0; i<A.length; i++) {
if (A[i] == ' ') {
numBlanks ++;
}
}
// 1.2 Calculate the size of the smaller array.
int size = A.length - numBlanks;
// 1.3 Make the new array.
char[] B = new char [size];
// 1.4 Copy over the non-space chars from the old to the new.
// ... fill in the code needed ...
}
5.1 Exercise:
In
CheckPalindrome.java
write out the rest of the method and test it out by printing
the resulting smaller array.
Next, let's write
isPalindrome():
static boolean isPalindrome (char[] letters)
{
int n = letters.length;
for (int i=0; i<(n-1)/2; i++) {
if (letters[i] != letters[n-i-1]) {
return false;
}
}
return true;
}
5.2 Exercise:
In
module5.pdf
trace through the above program when the
word is "river". And again when the word is "kayak".
Why does the for-loop
stop at (n-1)/2?
Will the loop work for both odd and even sizes?
5.3 Exercise:
Put the pieces together so that you have a complete
program in
CheckPalindrome.java
and test with the following:
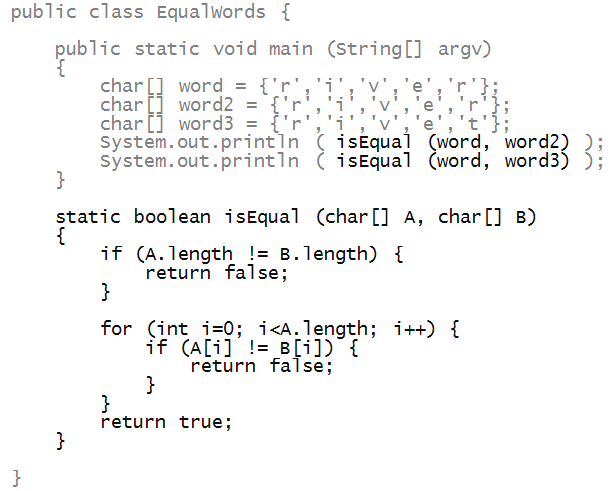
Let's start by testing whether two char arrays are equal:
Notice that the return value of isEqual is boolean:
Next, before even comparing array contents, we check
that the lengths are equal:
Clearly, if the lengths aren't equal, we can return
false
immediately.
One could use a "flag" variable:
Notice that, in
main,
we directly printing the return value of the method
isEqual().
When are two words approximately equal?
For numbers, we could say that 3.14 is approximately
equal to 3.15. What about words?
We will use wildcard matching for approximate comparison.
Suppose an asterisk * represents "match any character".
Then, "rive*" matches "river" and "rivet".
Similarly, "*i*er" matches "river" and "tiger".
Thus, the problem we wish to solve: given two
words with asterisks in them, establish whether they
are equal.
Here's the program:
5.5 Exercise:
In
module5.pdf
trace through the above program.
Why is the
condition B[i]!='*' needed?
If you
remove it, does the comparison fail for the
above examples? Can you find examples where
it would fail?
5.6 Exercise:
In
MyEqualWords.java
replace the nested-if with a single if-statement
that combines the conditions.
5.7 Video:
5.2 Searching for a word within a sentence
In this next example, we will look for a word (a search term)
within a sentence and identify
the position where it occurs (if it does):
Thus, if the sentence is "never odd or even" and the
search word is "odd", we want to return 6.
For the same sentence and search word "prime", we want to return -1
(not found).
Let's write a method called wordsearch that
has the following signature:
If that's the case, we can use it as follows:
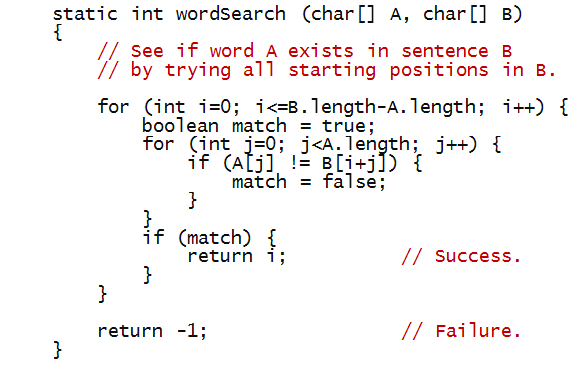
Here's one attempt:
5.8 Exercise:
In
module5.pdf
trace through the program
when the sentence is
"never odd or even" and the search word is "eve"?
What does this say about our wordsearch solution?
5.9 Exercise:
In
MyWordSearch.java
modify the wordSearch
method so that it returns a proper
index only if a full word is found to match. That is,
a search for "eve" in "never odd or even" should return
-1, whereas searches for "never", "odd", "or", or "even" should
return the correct position.
Then, in the main method, print out the return values only for
four calls to wordSearch using "Never", "even", "odd", and "ever"
as the word to search for in the string "Never odd or even".
5.10 Audio:
5.3 Common prefixes
Next, let's consider the prefix problem: given
two words, find their common prefix:
Example: rive is the common prefix shared
by river and rivet.
Our goal is to write a method with this signature:
static char[] commonPrefix (char[] A, char[] B)
so that it takes two char arrays and returns the
common prefix in a char array.
Then, we can use this method as follows:
char[] word = {'r','i','v','e','r'};
char[] word2 = {'r','i','v','e','t'};
char[] prefix = commonPrefix (word, word2);
// Should return "rive" in array prefix.
Let's start with this idea:
1. Suppose the two arrays are A and B.
2. Start with i=0 at the leftmost position of each array.
3. As long as A[i]==B[i], advance along the array.
4. The moment A[i] != B[i], stop.
Consider this attempt:
5.11 Exercise:
In
module5.pdf
trace through the program when the words are
"river" and "rivet".
Why are we computing the minimum of the lengths
of the two arrays? What would go wrong if we
used A.length instead as the for-loop
limit?
Change the words to "river" and "rover". What do you notice?
Trace through the program. Why doesn't it work?
Let's address the problem as follows:
5.12 Exercise:
In
module5.pdf
trace through the program with the above fix. Why does this work?
5.4 Cryptography Part I: The Caesar cipher
From times ancient rulers and rebels found the need
to communicate in code.
This meaning of code is different: something
encrypted to prevent understanding.
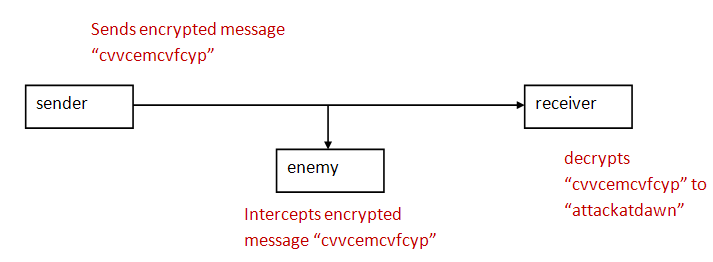
The essence of cryptography:
Although there is lots of two-way communication, in
essence, it boils down to a Sender that
needs to send a message to a Receiver in
the presence of an enemy interceptor.
Goals:
It should be hard for the enemy to decrypt.
It should be easy for sender to encrypt,
and for the receiver to decrypt.
A cipher is an encryption technique.
The original text or message to be encrypted is
called the plaintext.
The encrypted message or text is called: ciphertext.
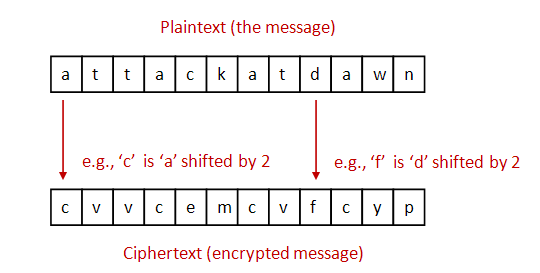
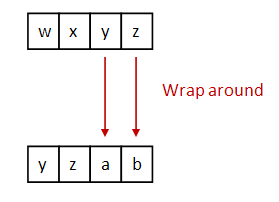
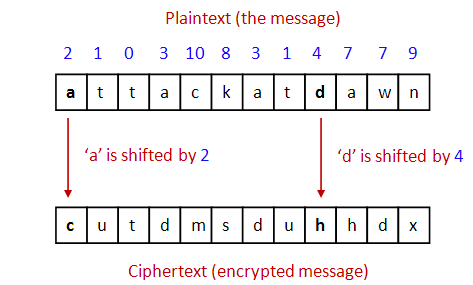
One of the oldest ciphers is the Caesar cipher:
To simplify, let's assume: lowercase letters only (no whitespace or
punctuation).
For encryption: each letter is shifted by a fixed amount (e.g., 2).
For decryption: shift back by the same amount.
Important: use wraparound.
5.13 Audio:
5.14 Exercise:
In
module5.pdf
explain how you would use the integer representation
of chars and the
%
(remainder) operator
to compute the Caesar shift of a char.
To simplify, first
consider only lowercase letters 'a' through 'z' and
suppose 'a' is represented by 0, 'b' is represented
by 1 ... etc.
Next, suppose we do a Caesar shift by the amount s.
Write an expression for computing the shifted character.
Show how it works for 'z'.
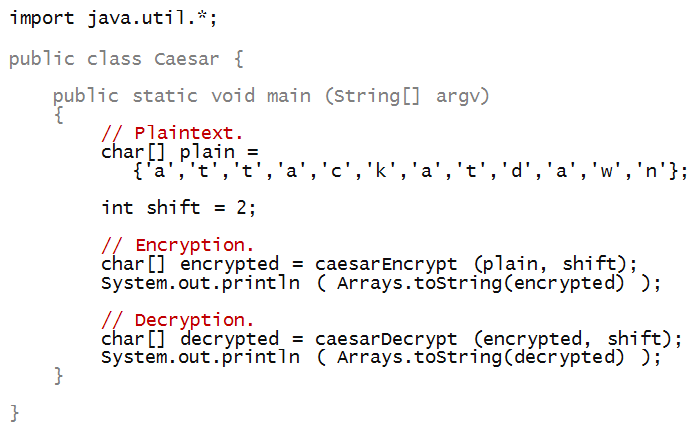
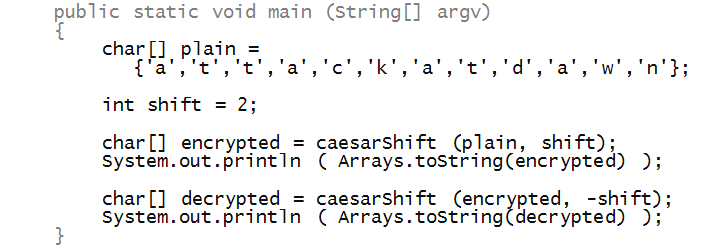
Next, let's write some code to implement the Caesar cipher:
To begin, let's write the test code in main:
Notice that the method caesarEncrypt takes
a char[] array (the plaintext), and shift as
parameters:
And returns a char[] array:
To print the array after encryption, we have used
a method called Arrays.toString from the
Java library:
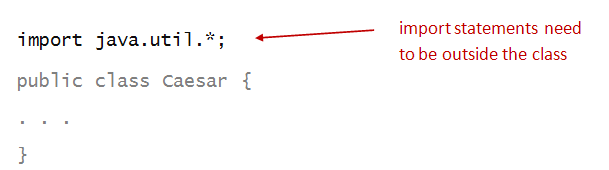
To be able to use some library methods, we need to
import the library:
import statements need to appear at the top,
outside the class:
An import statement uses the importreserved word:
And names the library, in this case java.util:
The asterisk simply asks to import everything in the
java.util library.
Alternatively, we could have imported just the class
we need:
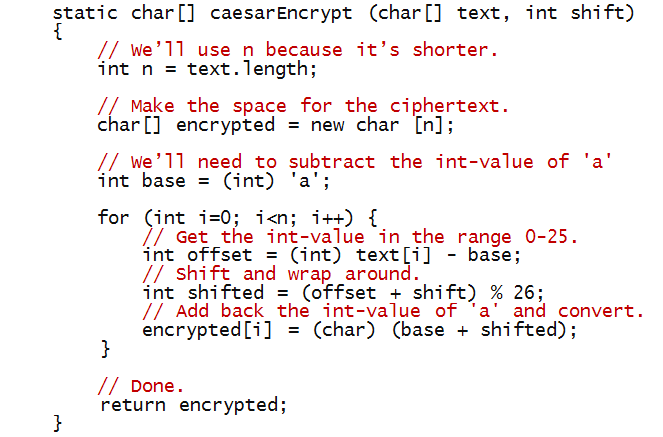
Now, let's write the code inside the method caesarEncrypt:
5.15 Exercise:
In
module5.pdf
trace through the above method if it's called with with
the letters "abc" and a shift of 2.
5.16 Exercise:
In
MyCaesar.java
write the method caesarDecrypt so that
the whole program works correctly.
5.17 Exercise:
Now suppose k is an integer. What is the relationship
between k % 26 and (k+26) % 26?
Try out a few examples and see if you can infer a rule.
Write it out in
module5.pdf.
Now, let's look at an alternative way of writing the
same program:
It seems that we should be able to use the almost-symmetry between
encryption in the following way:
Thus, decryption is merely a negative shift (shift in the reverse direction):
To do this, we'll use the property of the mod operator
that we explored earlier:
We've added 26 so that the number being mod'ed
is positive.
5.18 Exercise:
In
MyCaesar2.java
fill in the remaining code (in method caesarShift)
to make the program work.
5.19 Audio:
5.5 Cryptography Part II: The Vigenere cipher
Improving on the Caeser cipher:
As we've seen, the Caesar cipher is rather easy to break.
The problem is: there are only 26 possible shifts
⇒ the same shift is used for each plaintext letter.
It's convenient of course: the receiver only needs
to know the shift once
⇒ It can be used for many messages.
An idea for strengthening the encryption: use a different shift
for each char in the text
Unfortunately, there are several downsides:
Both sender and receiver have to have
communicated the sequence of "shifts" earlier.
In this case, for example, both would have to "know"
2 - 1 - 0 - 3 - 10 - 8 - 3 - 1 - 4 - 7 - 7 - 9
Because it's hard to remember, it would have to
be stored somewhere, risking discovery.
Messages can't be longer than the shift-pattern.
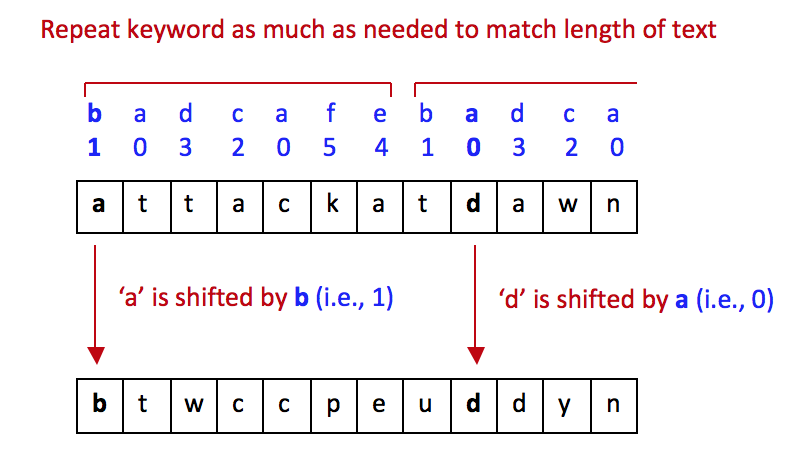
The Vigenere cipher addresses this problem:
First, note that shifts are numbers between 0 and 25.
⇒ A shift can be encoded as a letter!
Thus, a "shift of 3" can be expressed as
a "shift by 'd'".
But is a pattern like
c b a d k i d b e h h j
any easier to remember than
2 - 1 - 0 - 3 - 10 - 8 - 3 - 1 - 4 - 7 - 7 - 9?
Also, it is just as susceptible to discovery if
written somewhere.
The "key" insight of Monsieur Vigenere:
Both sender and receiver agree on a reasonable-size,
easy-to-memorize key
⇒ A string of letters.
Example: "bad cafe".
Then, the key is repeated (concatenated with itself) as much
as needed to match the length of the text.
Then, above each text letter is a key letter.
⇒ The key letter specifies the shift.
5.20 Exercise:
What is the 3-letter Vigenere key such that encryption
with this key will result in the equivalent ciphertext
that you get with a Caesar shift by 2?
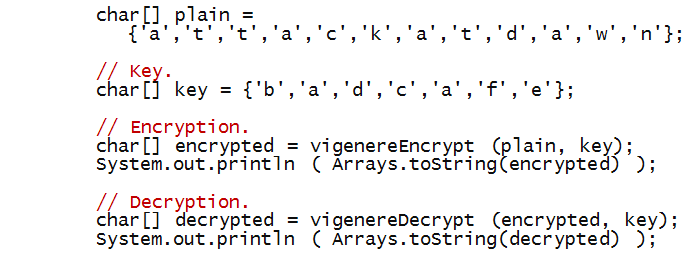
Next, we'll work towards an implementation:
Let's start with the "test" code in main
Next, consider vigenereEncrypt:
static char[] vigenereEncrypt (char[] text, char[] key)
{
int n = text.length;
// Make the space for the encrypted text.
char[] encrypted = new char [n];
// Repeat the key up to n chars and get the shifts
int[] shift = computeShifts (key, n);
// Apply the shift for each text letter
for (int i=0; i<n; i++) {
encrypted[i] = shiftChar (text[i], shift[i]);
}
return encrypted;
}
Notice we have used the same shiftChar method
used with the Caesar cipher.
Decryption is symmetric, with the same key:
static char[] vigenereDecrypt (char[] text, char[] key)
{
int n = text.length;
char[] encrypted = new char [n];
int[] shift = computeShifts (key, n);
for (int i=0; i<n; i++) {
encrypted[i] = shiftChar (text[i], -shift[i]);
}
return encrypted;
}
What's left: extending the key by repetition and returning
the corresponding array of shifts.
5.21 Exercise:
In
MyVigenere.java
write the code for computeShifts and
complete the whole program so that both encryption
and decryption work.
5.6 Cryptography Part III: Transposition ciphers
The ciphers we've seen so far use letter substitutions:
they are called substitution ciphers.
In a transposition cipher, all the original plaintext
letters are used, but they are shuffled.
For example, one could reverse the characters:
nwadtakcatta
Clearly, this is not as effective as other possible shuffles.
Let's consider a two-interleaving:
Here all the letters are array indices 0, 2, 4, ...
are clustered together on the left in the order in
which they occur, while the odd ones are to the right.
Now let's write encryption:
static char[] transposeEncrypt (char[] text)
{
int n = text.length;
char[] encrypted = new char [n];
// First copy over the chars located at even positions.
int k = 0;
for (int i=0; i<n; i+=2) {
encrypted[k++] = text[i];
}
// Now copy over the chars at odd positions.
// FILL IN THIS PART
return encrypted;
}
Notice how the letters in the even-numbered positions get copied
into the first half of the encrypted text:
int k = 0;
for (int i=0; i<n; i+=2) {
encrypted[k++] = text[i];
}
Here, we use two array index variables:
The variable
i
traverses the text array.
And
k
traverses the encrypted array.
Because both traverse differently, we increment them
differently.
Next, observe how we incremented
k:
encrypted[k++] = text[i];
Here
k
is used as the array index and THEN incremented.
It has exactly the same effect as:
encrypted[k] = text[i];
k++;
It's used as a "short cut" because it's more compact.
5.22 Exercise:
In
MyTranspose.java
complete the rest of the encrypted (copying over from the
odd-numbered position in the text).
5.23 Exercise:
Write the code for decryption and complete the program
(in
MyTranspose.java).
5.7 Cryptography Part IV: Combining ciphers
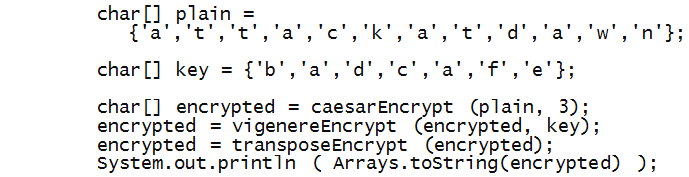
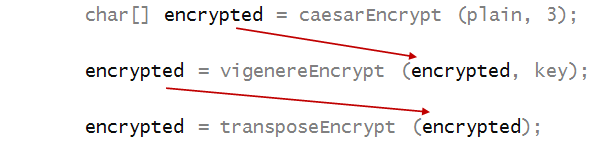
One can easily encrypt already-encrypted text, e.g.
Notice how each successive encryption is fed as
the plaintext to the next encryption:
5.24 Exercise:
Pool together your code from the three ciphers
and apply the above encryption
in
MyCombinedCipher.java
What is the resulting ciphertext?
Then, show that the ciphertext decrypts when
the decryption is applied in reverse order.
5.25 Exercise:
With the same ciphers in the same order but using
"java" as the Vigenere key, the following
is the result of encryption:
"mgfcmymfmiqqddufmyowomyhfgbhssrvpdzb"
Decrypt to find the original plaintext.
About cryptography:
Modern ciphers operate at the bit-level, not on characters,
but the same principles apply.
Modern ciphers apply several types of encryption in sequence.
We have barely scratched the surface of cryptography.
"Crypto", as it's informally called by its practitioners,
is vast subject with many deep and fascinating results.
Many key people involved in cryptography were or are computer
scientists - such as Alan Turing.
Crypto is a part of a larger field called computer security,
which also involves secure computing systems and networks.
Let's step back for a moment:
With the cryptography examples, we've gone beyond
problem-solving to actually developing an application.
It would be challenging to implement all the ideas
in one go.
Instead, by breaking it down into manageable (yet still
challenging) pieces, we've developed a fairly sophisticated
program.
5.26 Audio:
5.8 Computational Biology: Protein "strings"
Having scratched the surface of crypto, we'll now
scratch another: computational biology.
What we'll do:
Understand that proteins (an important type of bio molecule)
can be represented using strings.
⇒ the strings are called protein sequences.
Perform some types of operations on these protein sequences
that are useful in biology.
Let's start by understanding what a protein is.
5.27 Exercise:
Look up proteins - what is a protein and what does it do?
Look up insulin. What is its purpose?
What diseases are associated with insulin?
What Nobel prizes were associated with insulin?
What we need to know about proteins:
Although a protein has a 3D shape, it can be considered
a long chain of "units".
⇒ The 3D shape results from this chain folding on itself.
Each unit in the chain is determined by a particular
kind of small (or sub-) molecule called an amino-acid.
There are 20 types of amino acids.
These are the 20:
#
Amino Acid
Symbol
1
Alanine
A
2
Arginine
R
3
Asparagine
N
4
Aspartic acid
D
5
Cysteine
C
6
Glutamic acid
E
7
Glutamine
Q
8
Glycine
G
9
Histidine
H
10
Isoleucine
I
11
Leucine
L
12
Lysine
K
13
Methionine
M
14
Phenylalanine
F
15
Proline
P
16
Serine
S
17
Threonine
T
18
Tryptophan
W
19
Tyrosine
Y
20
Valine
V
Think of the 20 amino acids as represented by
their (20) letters:
A R N D C E Q G H I L K M F P S T W Y V
Then, a protein is a "word" made from letters in this
20-letter alphabet.
For example: here is part of the insulin protein:
F V N Q H L C G S H L V E A L Y L V C G E R G F F Y T P K T
It's length is 30.
It happens to be called the B-chain in human insulin.
To start with, let's understand a couple of things about insulin:
Insulin is made from a precursor molecule call preproinsulin.
Preproinsulin is made directly from the gene for insulin.
For example, here is the 110-letter sequence for preproinsulin:
The real insulin molecule is actually a
protein complex that is formed from
the A and B chains.
Let's now work on some string problems related
to insulin.
Before doing so, it'll help to review some methods available
for strings in Java.
5.28 Exercise:
Go back to
Module 4
and review these methods in
String: charAt, indexOf, length, substring, equals.
To start with, let's look for the three chains in preproinsulin:
Suppose we are given:
The sequence for preproinsulin.
The A-chain and B-chain.
The goal: find where in the preproinsulin they occur, and extract
the C-chain.
Here is the program:
String preproSeq = "MALWMRLLPLLALLALWGPDPAAAFVNQHLCGSHLVEALYLVCGERGFFYTPKTRREAEDLQVGQVELGGGPGAGSLQPLALEGSLQKRGIVEQCCTSICSLYQLENYCN";
String aChain = "GIVEQCCTSICSLYQLENYCN";
String bChain = "FVNQHLCGSHLVEALYLVCGERGFFYTPKT";
// Find where the A and B chains occur in preproinsulin.
int aIndex = preproSeq.indexOf (aChain);
int bIndex = preproSeq.indexOf (bChain);
System.out.println ("A chain starts at position " + aIndex);
System.out.println ("B chain starts at position " + bIndex);
// Extract the C-chain.
int cIndex = bIndex + bChain.length();
String cChain = preproSeq.substring (cIndex, aIndex);
System.out.println ("C-chain: " + cChain);
Note: we've used a version of the method
indexOf()
that takes a
String
as parameter and returns the start index where it occurs.
5.29 Exercise:
The following are the preproinsulin sequences for gorilla
and owl monkey. Use the equals method to see
whether they are the same as human preproinsulin.
That is, write a short program
in MyInsulin.java
to do this testing in main.
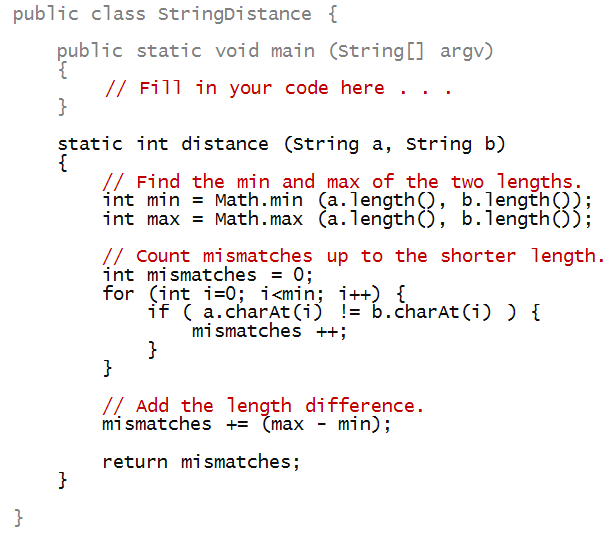
To use the distance method we wrote earlier, we'd have
to extract the sub-string from the preproinsulin sequence.
Here's a program that makes the comparison at the 5-th position.
String owlMonkeyPrepro = "MALWMHLLPLLALLALWGPEPAPAFVNQHLCGPHLVEALYLVCGERGFFYAPKTRREAEDLQVGQVELGGGSITGSLPPLEGPMQKRGVVDQCCTSICSLYQLQNYCN";
String humanB = "FVNQHLCGSHLVEALYLVCGERGFFYTPKT";
int i = 5;
String sub = owlMonkeyPrepro.substring (i, i + humanB.length());
int d = distance (sub, humanB);
System.out.println ("Distance=" + d + " at position=" + i);
System.out.println ("Human B : " + humanB);
System.out.println ("Owl match: " + sub);
5.31 Exercise:
In
StringDistance2.java,
expand on the above code to search all possible positions
in the owl-monkey preproinsulin and find the best possible
match (with the least distance). Print the position where
this occurs, and the distance.
5.32 Exercise:
Now try the same thing with a few non-primates. Before
running your code, which of the three do you expect
to produce a result closest to human? Farthest?
Even when a mismatch looks very difficult, it is
possible to identify reasonable matches.
⇒ This is the subject of advanced techniques in computational biology.
5.33 Video:
5.9 Meta
This module stretched us a bit. Let's ask ourselves: why was it challenging?
The issue is: when applying programming to a domain, we need
to spend effort in understanding the domain. Doing both, programming
and wading into the details of a domain, can be challenging.
Over time, as you get better at programming, you will worry
less about the programming and concentrate on the domain of interest.
Another challenge is that our programs have gotten longer
because they are "doing more".
Again, we will get better at reading and writing. After a
few more units, this module will seem much simpler.
Pushing yourself through challenging material like this
will build confidence for later.
After all, if you can handle cryptography and computational
biology, can anything else be difficult?