Module 5: Pattern Search
Problem Definition
Simple description:
- Given two strings of characters, the "text" and the "pattern",
find the first occurence of the "pattern" (as a substring) in the "text".
- Terminology:
- Pattern: string or string-specification you are
looking for.
- Text: sequence of characters in which you are searching.
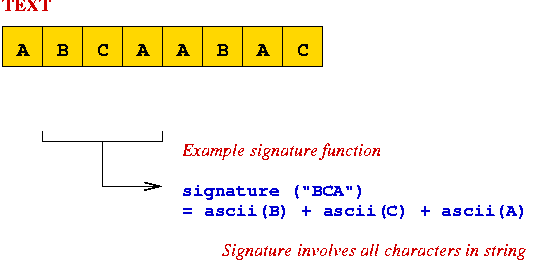
Example:
Practical issues:
In-Class Exercise 5.1:
Download this template
and implement a simple algorithm for finding a pattern within a text.
Both the pattern and text are of type char[] (arrays of characters).
Analyse the complexity of your algorithm for a pattern of size
m and a text of length n.
Using Signatures: The Rabin-Karp Algorithm
Key ideas:
- Compute the "signature" of the pattern.
- Compute the "signature" of each substring of the text.
- Scan text until signature matches
=> potential match, so perform string comparison.
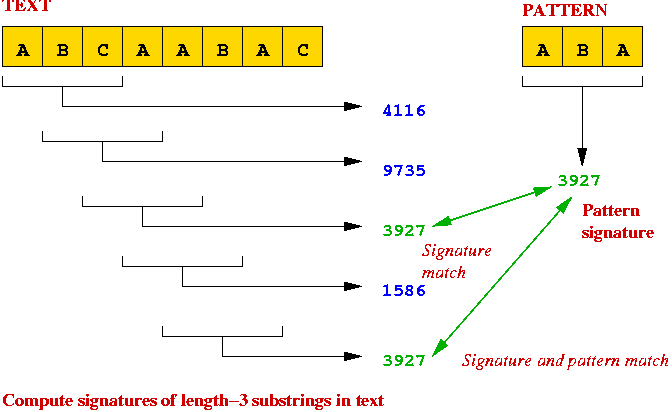
Details:
Pseudocode:
Algorithm: RabinKarpPatternSearch (pattern, text)
Input: pattern array of length m, text array of length n
// Compute the signature of the pattern using modulo-arithmetic.
1. patternHash = computePatternSignature (pattern);
// A small optimization: compute dm-1 mod q just once.
2. multiplier = dm-1 mod q;
// Initialize the current text signature to first substring of length m.
3. texthash = compute signature of text[0]...text[m-1]
// No match possible after this position:
4. lastPossiblePosition = n - m
// Start scan.
5. textCursor = 0
6. while textCursor <= lastPossiblePosition
7. if textHash = patternHash
// Potential match.
8. if match (pattern, text, textCursor)
// Match found
9. return textCursor
10. endif
// Different strings with same signature, so continue search.
11. endif
12. textCursor = textCursor + 1
// Use O(1) computation to compute next signature: this uses
// the multiplier as well as d and q.
13. textHash = compute signature of text[textCursor],...,text[textCursor+m-1]
14. endwhile
15. return -1
Output: position in text if pattern is found, -1 if not found.
Example:
A B A B A C B A C A C A B A TextHash=2199650 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2231425 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2199651 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2231458 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2200705 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2265187 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2231457 patternHash=2231457
B A C A
A B A B A C B A C A C A B A Pattern found
B A C A
Analysis:
- The pattern signature is computed once: O(m).
- The first text signature takes O(m) time.
- Each subsequent signature takes O(1) time
=> O(m+n) time overall.
- However, in theory a "false" match could occur every time.
=> comparison required at every text position.
=> O(mn) time overall.
- In practice, this is unlikely: O(m+n) time on the average.
- Recall: the naive algorithm takes O(mn) time.
- How different is O(mn) from O(m+n)?
if m = n/2 then mn = O(n2) but m+n = O(n).
In practice:
- Signatures take time to compute
=> naive search often performs better.
- Signature approach not worth it for small m (pattern length).
- The signature technique is very general
=> can apply to 2D patterns, other kinds of data.
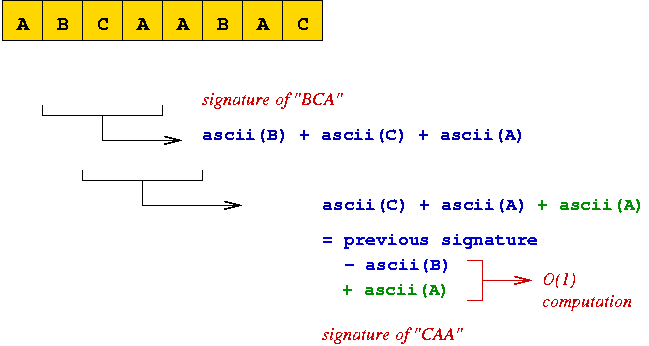
In-Class Exercise 5.2:
Download this template
and implement the Rabin-Karp algorithm but with a different signature function.
Use the simple signature of adding up the ascii codes in the string
(shown in the second figure in this section).
The Knuth-Morris-Pratt Algorithm
Key ideas:
Example:
Computing the nextIndex function:
In-Class Exercise 5.3:
Consider this partial match:
E A B C A B C A B A B C E A A A A C A A A A
A B C A B C A F
How many letters can we skip? What about this case (below)?
E A B C B B C A C A B C E A A A A C A A A A
A B C B B C A F
- What is the intuition? Consider this example:
E A B A B E A A A A C A A A A
A B A B F
E A B A B E A A A A C A A A A
A B A B F
The amount shifted depends on how large a "prefix of the
pattern" is a "suffix of the matched-text".
- Consider the first example again:
E A A A A E A A A A C A A A A
A A A A F
- Second example:
E A B A B E A A A A C A A A A
A B A B F
- The A B prefix of the pattern
is a suffix of the matched text A B A B.
- Thus, intuitively, the amout to slide forward depends on the
prefix-suffix match:
- The more the match, the less we can slide forward.
The relation with nextIndex:
Pseudocode:
Algorithm: KnuthMorrisPrattPatternSearch (pattern, text)
Input: pattern array of length m, text array of length n
// Compute the nextIndex function, stored in an array:
1. nextIndex = computeNextIndex (pattern)
// Start the pattern search.
2. textCursor = 0
3. patternCursor = 0
4. while textCursor < n and patternCursor < m
5. if text[textCursor] = pattern[patternCursor]
// Advance cursors as long as characters match.
6. textCursor = textCursor + 1
7. patternCursor = patternCursor + 1
8. else
// Mismatch.
9. if patternCursor = 0
// If the mismatch occurred at first position, simply
// advance the pattern one space.
10. textCursor = textCursor + 1
11. else
// Otherwise, use the nextIndex function. The textCursor
// already points to the next place to compare in the text.
12. patternCursor = nextIndex[patternCursor]
13. endif
14. endif
15. endwhile
16. if patternCursor = m
// If there was a match, return the first position in the match.
17. return (textCursor - patternCursor)
18. else
19. return -1
Output: position in text if pattern is found, -1 if not found.
Algorithm: computeNextIndex (pattern)
Input: a pattern array of length m
1. nextIndex[0] = 0
2. for i=1 to m-1
3. nextIndex[i] = largest suffix of pattern[0]...pattern[i-1] that
is a prefix of pattern.
4. endfor
5. return nextIndex
Output: the nextIndex array (representing the nextIndex function)
Analysis:
- Since we never backtrack in scanning the text: O(n) for
the scan.
- Our implementation of computeNextIndex took:
O(m2) time.
=> Overall time: O(m2 + n)
- It is possible to optimize computeNextIndex to take
O(m) time.
=> Overall time: O(m + n)
Pattern Search with Deterministic Finite Automata
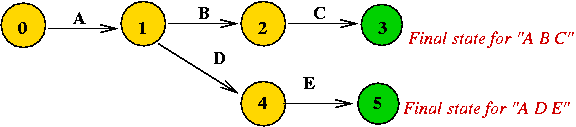
The "Evil Bureaucracy" metaphor:
- Suppose you need to get a document (e.g., passport application)
signed by various officials in sequence.
- The officials:
| | OFFICIAL | | ABBREVIATION |
| | Assistant Director | | A |
| | Director | | D |
| | Managing Director | | M |
| | Chief Managing Director | | C |
- The paper trail:
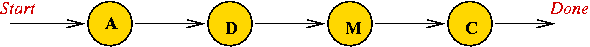
- Interpretation: going from "state" to "state"

- Here, "A" represents the state of "approval by A".
- Alternatively, suppose you have the signatures, then "A"
checks for the "A" signature.
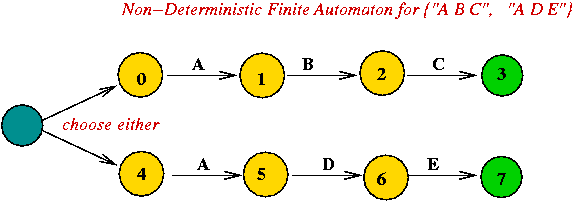
- The above "state machine" recognizes the pattern "A D M C".
What is a DFA?
- DFA = Deterministic Finite Automaton.
- A DFA is a collection of "states" and "arcs".
- The arcs sometimes have "labels" on them.
- A DFA scans an input string and follows labels accordingly.
- Some DFA "states" are marked as "final states".
- If the input causes the DFA to go into a final state, the input
is "accepted".
Example: consider a DFA to recognize the string "A B C D".
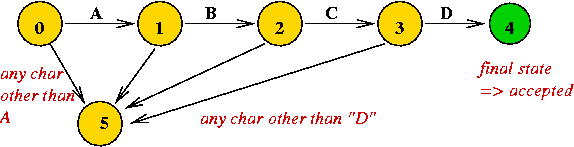
- If the input string is "A B C D", the DFA goes into the final
state.
- Any other input string causes the DFA to end in a "non-final" state.
Example: consider this DFA
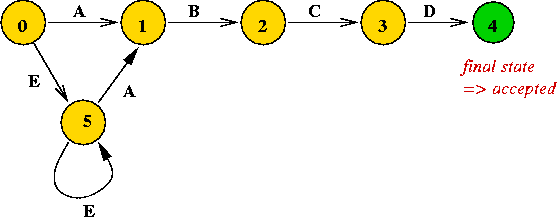
- The DFA finds the pattern "A B C D"
in the text "... (any number of E's) ... A B C D ... (anything else)".
- Example text: "E E A B C D A E D C"
- Here, we allow states to "get stuck" (not accept input).
- Note:
- States are (typically) numbered 0, 1, ... etc.
- Input characters are "swallowed" (removed) one-by-one for
each arc taken.
In-Class Exercise 5.4:
Draw a DFA to find the first occurence of "A B C D" in a
text consisting of the following structure:
"... (zero or more E's) ... A ... (zero or more E's) ... B C D ... (anything)"
A DFA to find the first occurrence of "A B C D" in any text:
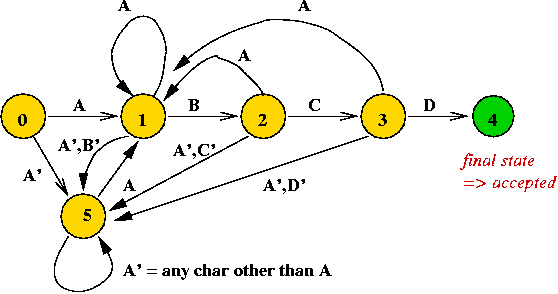
- Here, the idea is to let state 5 "eat" non-A characters until
the first "A" is found.
- When an "A" is detected in other states, move to state 1.
Thus, a DFA can be used for the pattern search problem.
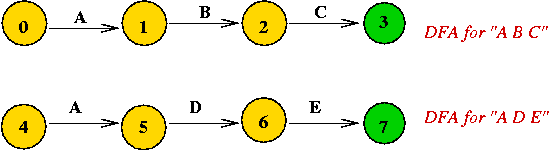
Another example: a DFA for the pattern "A B C A B D"
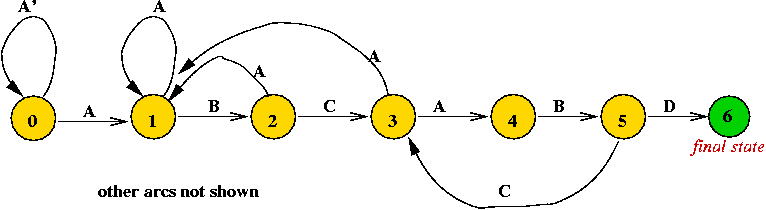
- Note: only some arcs are shown.
- Observe arc from state 5 to state 3
=> because the sub-pattern "A B" is already scanned.
The nextState function:
- A DFA is represented in a program using a "nextState" function
(a table).
- The table has one row for each state, one column for each
possible input character.
- The table entry for row i and column "C"
tells you the
next state going from state i upon input "C".
=> the arc leading out of i with character "C".
Example:
Building the nextState function:
- Some observations:
- The nextState function uses the current character in the input.
- States can be numbered according to the length of the prefix
detected so far.
- Forward arcs (low number to high-numbered state) go along the pattern itself.
- Reverse arc lengths depend on the length of the prefix
detected so far.
- Key observation: a reverse arc decreases by the
length of the largest suffix that is a prefix (of the pattern).
- The final state is numbered with the pattern length.
Pseudocode:
Algorithm: DFAPatternSearch (pattern, text)
Input: pattern array of length m, text array of length n
// First, build the nextState function.
1. nextState = computeNextStateFunction (pattern)
// Now scan input character by character.
2. currentState = 0
3. for textCursor=0 to n-1
4. character = text[textCursor]
// Go to next state.
5. currentState = nextState[currentState][character]
// If it's the final state, we're done.
6. if currentState = m
7. return (textCursor - m + 1)
8. endif
9. endfor
10. return -1
Output: position in text if pattern is found, -1 if not found.
Algorithm: computeNextStateFunction (pattern)
Input: pattern array of length m
1. for state=0 to m-1
2. for character=smallestChar to largestChar
3. patternPlusChar = concatenate (pattern, character)
4. k = length of longest suffix of patternPlusChar that is a prefix of pattern
5. nextState[state][character] = k
6. endfor
7. endfor
Analysis:
- The nextState function requires O(cm2) time
to compute where c = size of character set.
- Processing the text requires O(n) time.
=> total time is O(cm2 + n).
In practice:
- The DFA method is rarely used because character sets tend to be
large
=> nextState computation is significant.
- However, DFA's are easy to build and have many other
applications
=> useful as library code.
- DFA's can be automatically built using tools like Lex.
Wildcards, Regular Expressions and Non-Deterministic Finite Automata
What does "wildcard" mean?
- Consider the Unix command to list files, used in the following
way:
ls *.java
- Here, the "*" is equivalent to "any character string".
(Not containing special characters like "*").
- The pattern *.java is a wildcard expression.
- In simple text search, a pattern is one string.
- A wildcard expression can specify a set of strings:
*.java = {.java, a.java, aa.java, aaa.java, ... ,b.java, ... (infinite) set}
Regular expressions:
- Regular expressions are a generalization of wildcard expressions.
- Regular expressions are specified "bottom up" using
operators:
- Terminal: a character is a regular expression.
Example: "A" is a regular expression.
- Concatenation: if R1
and R2
are regular expressions, so is
R1R2.
Example: "A"
concatenated with "B" gives regular
expression "A B".
- Or: if R1
and R2 are regular expressions, so is
R1 | R2.
- A | B
is a regular expression specifying the set {"A", "B"}.
- Since C is a regular expression, using concatenation,
(A | B) C is a regular expression.
- (A | B) C
specifies the set {"A C", "B C"}.
- Closure (or Kleene-star):
if R1 is a regular expression,
R1*
specifies any number of repetitions of
R1:
- Note: the * is used as a superscript and (confusingly)
is NOT the same as the wildcard "*".
- The expression A*
specifies the set {"A", "A A", "A A A",
... (infinite set)} and the empty string.
- Similarly, (AB)*C =
{"C", "A B C", "A B A B", ... }.
- The alphabet and expression operators.
- Underlying both wildcard expressions and regular expression
is an alphabet
=> the characters used as terminals.
- Operators used for expressions, such as | and
* are NOT permitted to be in the alphabet.
- Expressing wildcards with regular expressions:
- Suppose our alphabet consists of {A, B, C}
- Consider the wildcard expression "* A B *".
- The corresponding regular expression is:
(A | B | C)* (A B) (A | B | C)*
- Intuition: any combination of letters, followed by A B,
followed by any combination of letters.
- Terminology: the following are equivalent
- A C satisfies expression
(A | B) C
- A C matches expression
(A | B) C
- A C is in the set specified by
expression (A | B) C
In-Class Exercise 5.5:
Construct the regular expression for the set
{"D A B", "D A C", "D A B E", "D A C E", "D A B E E", "D A C E E",... }
The pattern-search problem we want to solve:
- Given a regular expression, e.g., (A | B) (A B)* C,
and a text, find the first occurrence of a substring in the
text that satisfies the regular expression.
(i.e., is in the set specified by the expression).
- Example: regular expression (A | B) (A B)* C,
and text "D B B A A B C D A".
- The substring "A A B C"
in "D B B A A B C D A"
satisfies in the expression.
- First, we'll solve a simpler problem:
Given a regular expression and a string (pattern), does the string
satisfy the expression?
- We'll use a Non-Deterministic Finite Automaton (NDFA) to
recognize strings that match a regular expression.
What is an NDFA?
Constructing an NDFA from a regular expression:
- Recall original goal: a recognizer for regular expressions.
- The NDFA will be constructed recursively using combining
rules.
- Rules:
- Terminal: An NDFA for a single character, e.g., for "A"

- Special states are used as start and end states.
- A regular state is used to recognize the character.
- Concatenation:
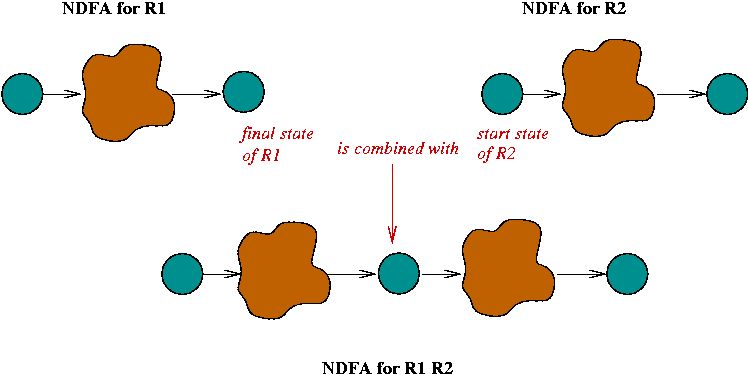
- Suppose we have NDFA's for regular
expressions R1
and R2
- We want the NDFA for R1 R2
- The NDFA's are combined in sequence by merging the final
state of R1
and the start state of R2.
- Or:
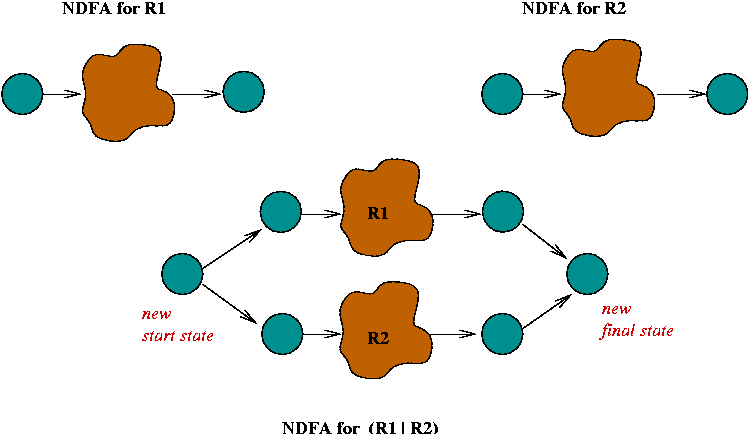
- Suppose we have NDFA's for regular
expressions R1
and R2
- We want the NDFA for R1 | R2
- The NDFA's are combined in "parallel" by introducing new
special states.
- Closure:
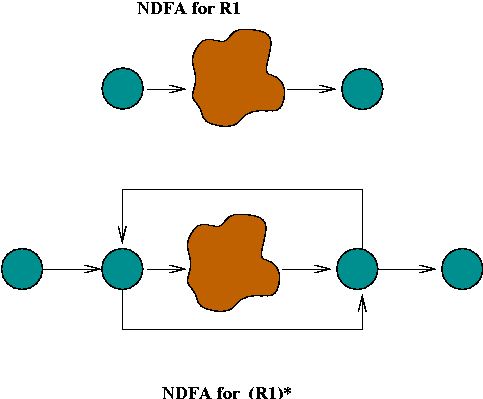
- Suppose we have an NDFA for regular expression R1.
- We want the NDFA for R1*.
- Add new start and final states, and new arcs.n
- Optimizations:
- The above combination rules will result in "bloated" NDFA's.
- Several optimizations can be applied, for example:
- Special states in sequence:
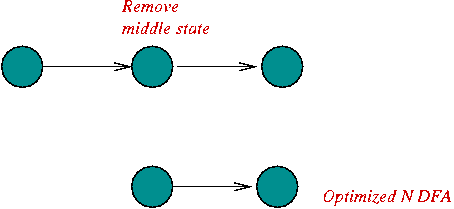
- Removing the special start state for a single-character.
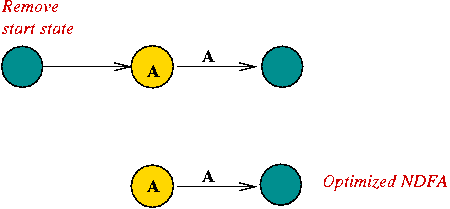
In-Class Exercise 5.6:
Construct an NDFA for the regular expression "C (A | B) (A B)*".
First, use the rules to construct an unoptimized version, then
try to optimize it (reduce the number of states).
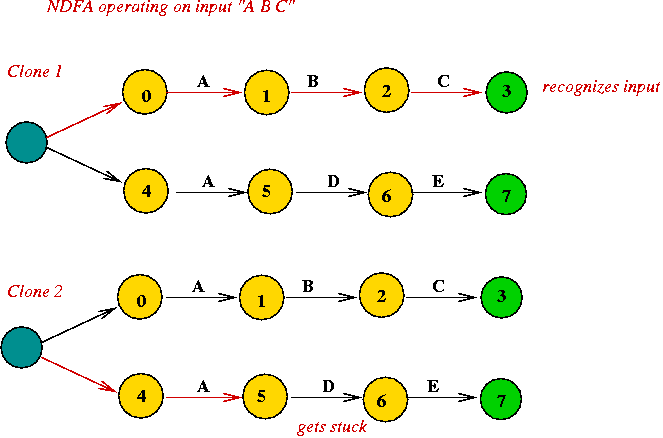
How to "run" an NDFA on input:
- Track all possible states in clones simultaneously.
- Use a deque
=> a double-ended queue.
- When processing a "special state", place all possible next
states in the front of the deque.
- When processing a regular state, consume the input character,
and place next state at the end of the queue.
- Keep processing until either:
- A final state is reached
=> accept input string.
- All input is consumed
string does not satisfy regular expression.
In-Class Exercise 5.7:
Write pseudocode describing a recursive algorithm to see if
a given string
(such as PatternSearch.java)
matches a given wildcard pattern
(such as Patt*nSearch.*).
Web Search Engines
In this section, we'll give an overview of how search engines
work.
Three parts to search engines:
- Crawling:
- The process of scouring the web looking for new documents.
- Usually, by retrieving a page and then following links in it.
- Typically non-recursive, with priorities.
=> keep separate list of "well-known" sites.
- Crawling is independent of other processes.
- Easy to parallelize.
- Indexing
- Key idea: build an inverted list over document base.
- Also collect/compute information used in relevance-ranking.
- Query handling:
- Present a web-page for users with query fields, e.g., Google's simple homepage.
- Extract query and parse it.
- Compute/extract results (links to documents).
- Sort results by relevance or other factors.
- Display (send back to browser).
In-Class Exercise 5.8:
Look up the "page rank" algorithm and describe how it works.
What are the disadvantages of using that algorithm?
Indexing via an example:
- Consider these two documents:
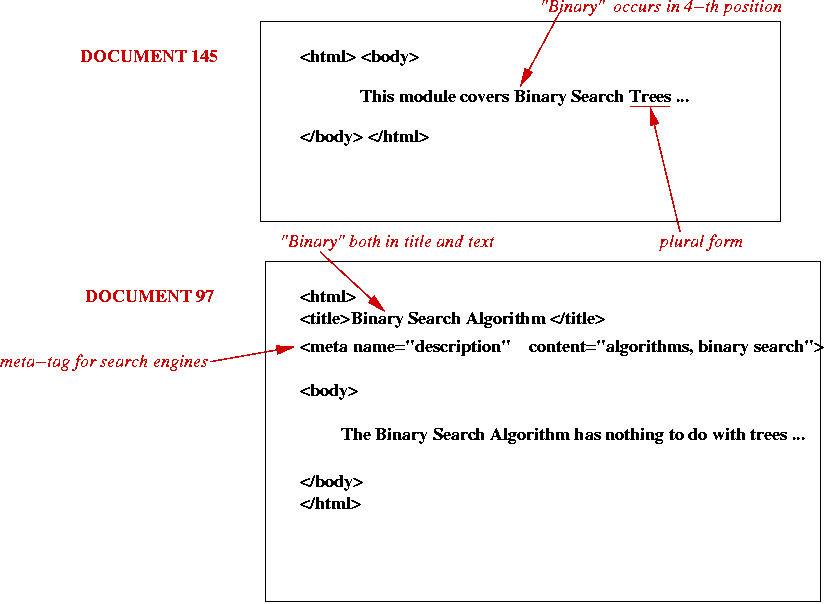
- An inverted list:
- Simply a collection of all "words" with pointers to
documents that contain them:
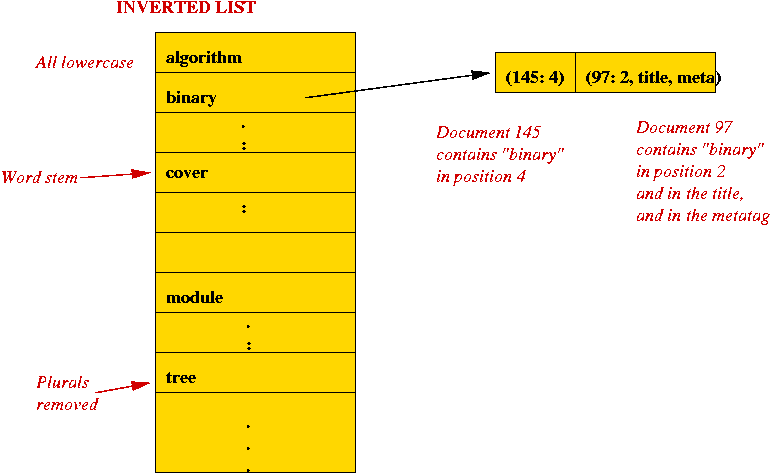
- Key ideas in processing a document:
- Skip "stop words" such as "the, an, a,...".
- Maintain positions of important words.
- Add data to inverted list.
- Other info: statistical data
(e.g., number of
occurrences in document).
Query-handling:
- Example: "Algorithm"
- Find all documents containing word.
- Rank according to relevance.
=> rank Document 97 higher than Document 145 (because
"Algorithm" is in the title).
- Example: "Binary Search Tree".
- Find all documents containing the words.
- Identify those containing all three words.
- Rank according to relevance.
=> rank Document 145 higher than Document 97
(because the words occur in sequence).