The goal of this module is to touch upon a few
advanced topics that will be directly useful in the next module.
Note:
The topics are introduced with a "not on the final exam" intent,
for your understanding and use in the next module's exercises,
but not tested on the final exam.
1.0 Audio:
1.0 Advanced topic: tuples
In this section and the ones that follow, we'll touch lightly upon a
few topics that are "not on the final exam" but will be useful
in general.
Some of these concepts will be directly used in the next module.
Suppose we want to write a function that computes both the
square and cube of a number:
Another way in which a tuple is like a list is in
using square-brackets and position indices to access individual
elements, as in:
# List version:
L = do_both_list(x)
print(L[0], L[1]) # L[0] has the square, L[1] has the cube
# Tuple version:
t = do_both(x)
print(t[0], t[1]) # t[0] has the square, t[1] has the cube
However, here's the difference:
# List version:
L = do_both_list(x)
L[0] = 0 # This is allowed
# Tuple version:
t = do_both(x)
t[0] = 0 # This is NOT allowed
Thus, you can replace a list element but you cannot replace a tuple element.
This is in fact a bit subtle, as this example shows:
x = 3
y = 4
t = (x, y) # The tuple's value is now fixed.
print(t) # (3, 4)
x = 2
print(t) # (3, 4)
Once the tuple is instantiated (that's the technical term
for "made") then the tuple's value cannot be changed.
You can of course assign a different tuple value to a tuple
variable as in:
t = (1, 2)
print(t)
t = (3, 4)
print(t)
Here, we're simply replacing one fixed-value tuple with another.
Tuples are therefore said to be an immutable type
(along with strings).
Why use tuples at all? It's to allow programmers to signal
clearly that their tuples shouldn't be changed.
This turns out to be convenient for mathematical
tuples (like points on a graph), which are similar.
Groups of tuples can be combined into lists and other data structures.
It's very useful in working with points (the mathematical point
you draw with coordinates) and other mathematical
structures that need more than one number to describe.
For example, here's a program that, given a list of points,
finds the leftmost point (the one with the least x value).
1.1 Exercise:
Type up the above in
my_tuple_example.py.
Then trace through the iteration in your module pdf.
1.2 Exercise:
Consider the following:
import math
def distance(p, q):
return math.sqrt( (p[0]-q[0])**2 + (p[1]-q[1])**2 )
def find_closest_point(p, L):
# Write your code here to find the closest point in L to p
# and to return both the point and the distance to it from p.
list_of_points = [(3,4), (1,2), (3,2), (4,3), (5,6)]
query_point = (5,4)
(c, d) = find_closest_point(query_point, list_of_points)
print('closest:',c,' at distance', d)
# Should print:
# closest: (4, 3) at distance 1.4142135623730951
In
my_tuple_example2.py,
fill in the missing code to find the closest point in a list of
points to a given query point. Return both the closest point
and the distance to the query point as a tuple.
1.3 Audio:
1.1 Advanced topic: sets
The general mathematical term set means a "collection of like
things but without duplicates".
Python has special syntax and operations to support this
mathematical notion:
Here are two sets being defined:
A = {2, 4, 5, 6, 8} # Curly brackets
B = {'hello', 'hi', 'hey', 'howdy'}
The first set contains five numbers, whereas the second contains
four strings.
Consider this variation
A = {2, 4, 5, 6, 8}
B = {'hello', 'hi', 'hey', 'howdy'}
C = {8, 5, 4, 6, 2, 4, 5, 5}
print(C)
if A == C:
print('they are equal')
else:
print('they are not equal')
Given what we've said about sets, what will be printed?
1.4 Exercise:
Type up the above in
my_set_example.py
to find out.
Note:
Even though a set may not have duplicates, we are actually
allowed to try to create duplicates:
C = {8, 5, 4, 6, 2, 4, 5, 5}
Python simply removes the duplicates.
Python also organizes sets so that sets can be compared for equality:
Thus, printing the set
C = {8, 5, 4, 6, 2, 4, 5, 5}
actually results in
{2, 4, 5, 6, 8}
What can we do with sets?
The most common operation is to see whether some value is in
some set we've defined using the keyword in:
def check_vowel(x):
vowels = {'a','e','i','o','u'}
if x in vowels:
print(x, 'is a vowel')
else:
print(x, 'is not a vowel')
check_vowel('a')
check_vowel('b')
Other, more mathematical operations, feature
different ways of combining sets. For example:
A = {2, 4, 5, 6, 8}
B = {1, 3, 5, 6}
D = A | B # union
print(D)
Here, D contains every element across both sets.
Other such operators include:
intersection (elements that are in both sets)
difference (elements in one set that are not in the other)
Since our goal is merely to give you a taste of these
advanced topics, we won't say much more about these operations.
Instead, let's look at an application:
In text processing, the term stopword is
often used to describe commonly used words that serve little
or no purpose in text analysis:
When you analyze digitized texts for meaning, topic and
dialogue (for example), words like "the", "of", "and"
get in the way of analysis.
They are often discarded from text analysis that seeks
to analyze more significant words.
We'll ask the question: what proportion of text typically
consists of stopwords?
(The answer is surprising, as we'll see).
To answer the question, we'll scan text word-by-word and
see if each word is in the set of stopwords.
Although there are hundreds of stopwords, we'll keep things
simple by targeting a few.
Let's write this up:
import wordtool as wt
# The 25 most common stopwords
stopwords = {'the','be','to','of','and','a','in','that','have','I',
'it','for','not','on','with','he','she','you','do','as',
'at','his','her','they','by'}
wt.open_file_byword('alice.txt')
s = wt.next_word()
num_stopwords = 0
total_words = 0
while s != None:
if s in stopwords:
num_stopwords += 1 # Count stopwords
total_words += 1 # And all words
s = wt.next_word()
percent_stopwords = 100 * (num_stopwords/total_words)
# Compare this:
string_to_print = '% of stopwords:{0:.2f}'.format(percent_stopwords)
print(string_to_print)
# to this:
# print(percent_stopwords)
1.5 Exercise:
Type up the above in
my_stopwords.py.
Then, compare the percentage of stopwords in these
two famous texts:
Alice in Wonderland
and Darwin's
The Origin of the Species.
Try two other texts from Project Gutenberg, and report the
results in your module pdf.
As an aside, we'll point out something about string
formatting, which is also an advanced topic:
It's plain ugly (and often useless) to print out all the
digits in a floating number like:
% of stopwords: 31.969357958208498
Instead, we'd like
% of stopwords: 31.97
Specifying to Python how you'd like a
number formatted, unfortunately, is a bit of a chore using
somewhat cryptic commands embedded within strings:
string_to_print = '% of stopwords:{0:.2f}'.format(percent_stopwords)
print(string_to_print)
We'll explain this one with the understanding that a proper look
into this topic is beyond the scope of this course:
First, one builds the target strings using typical quotes,
as in:
string_to_print = '% of stopwords: '
Then, attach the format function with the desired variable
whose value we wish to print nicely:
string_to_print = '% of stopwords: '.format(percent_stopwords)
Then, figure out where in the string you want the resulting
number and use curly brackets:
string_to_print = '% of stopwords: {0}'.format(percent_stopwords)
Here, 0 means the first such number. If had a second number, we'd
use 1, and so on.
Finally, specify both how many digits after the decimal
point, and that this number is a float:
string_to_print = '% of stopwords: {0:.2f}'.format(percent_stopwords)
Yes, a bit cryptic and difficult to understand. But
eventually, when you get used to it, it's powerful when you are
doing a lot of text output.
1.2 Advanced topic: dictionaries
Consider this problem:
We have a data file that looks like this:
apple
banana
apple
pear
banana
banana
apple
kiwi
orange
orange
orange
kiwi
orange
This might represent, for example, a record of sales at a fruit stand.
We'd like to count how many of each fruit.
One way would be to define a counter for each kind:
num_apples = 0
num_bananas = 0
num_pears = 0
num_kiwis = 0
num_oranges = 0
with open('fruits.txt','r') as data_file:
line = data_file.readline()
while line != '':
fruit = line.strip()
if fruit == 'apple':
num_apples += 1
elif fruit == 'banana':
num_bananas += 1
elif fruit == 'pear':
num_pears += 1
elif fruit == 'kiwi':
num_kiwis += 1
elif fruit == 'orange':
num_oranges += 1
else:
print('unknown fruit:', fruit)
line = data_file.readline()
print('# apples:', num_apples)
print('# bananas:', num_bananas)
print('# pears:', num_pears)
print('# kiwi:', num_kiwis)
print('# oranges:', num_oranges)
1.6 Exercise:
Type up the above in
my_fruits.py
and use the data file
fruits.txt
to confirm.
Next, in
my_fruits2.py,
change the program to accommodate the additional fruits in
fruits2.txt.
Aside from being tedious, this approach has other issues:
One would like to be able to write a general program that
does not need to know which fruits are in a file.
What if there were a thousand different kinds of items
(not fruits, say, but department-store items)?
A single mistake in a variable can cause the counts to be wrong.
Fortunately, the use of dictionaries will make it easy:
# Make an empty dictionary
counters = dict()
with open('fruits.txt','r') as data_file:
line = data_file.readline()
while line != '':
fruit = line.strip()
if fruit in counters.keys():
# If we've seen the fruit before, increment.
counters[fruit] += 1
else:
# If this is the first time, set the counter to 1
counters[fruit] = 1
line = data_file.readline()
print(counters)
1.7 Exercise:
Type up the above in
my_fruits3.py
and first apply it to
fruits.txt
and then to
fruits2.txt.
(Submit your program with the latter file as the input file.)
In your module pdf, describe what you had to change in the code
to make it work for the second file.
Now let's explain:
A dictionary is a technical term that is only
somewhat related to an actual English dictionary.
Think of an English dictionary as something
where you look up a word and receive
its meaning.
They operations here are look up and
receive an associated value (the word's
meaning, in this case).
In Python, a dictionary is a structure that lets you
associate one kind of data with another.
The technical equivalent of a word is called a key
and the equivalent of the meaning is called the value.
So, a dictionary is a collection of key-value pairs.
Conveniently, Python allows array indexing using the key:
d = {'apple': 3, 'banana': 3, 'pear': 1, 'kiwi': 2, 'orange': 4}
print(d['apple']) # Prints 3
d['banana'] = 0
# Which changes the value associated with 'banana' to 3
The above is an example of a dictionary that's already built
(after we've processed the data).
To process data on-the-fly, we need an additional operation that an English dictionary
does not really have: we need to be able to add something
that's not already there.
With this understanding we can now revisit the code in the
fruit example:
We've seen how to read a file line-by-line before
with open('fruits.txt','r') as data_file:
line = data_file.readline()
while line != '':
fruit = line.strip() # Remove whitespace on either side
# This is where we'd do something with the datda
line = data_file.readline() # Get the next line
The rest is merely the dictionary part:
with open('fruits.txt','r') as data_file:
line = data_file.readline()
while line != '':
fruit = line.strip() # Remove whitespace on either side
if fruit in counters.keys():
# If we've seen the fruit before, increment.
counters[fruit] += 1
else:
# If this is the first time, set the counter to 1
counters[fruit] = 1
line = data_file.readline() # Get the next line
1.8 Exercise:
In
my_stopwords2.py,
write code that uses a dictionary to compare the
relative occurrence of stopwords in
alice.txt
and
darwin.txt.
In particular, we'd like to know: what percentage of
the stopword occurence can be attributed to 'the', what
percentage to 'and', and so on.
For
alice.txt
the output should look
like this
(not necessarily in the same order) using the string formatting
from the previous section.
In your module pdf, compare the outputs for the two texts:
do the stopwords occur with similar relative frequencies across the two texts?
1.9 Audio:
1.3 Advanced topic: global variables
Suppose we have the following application:
We prompt the user to enter the parameters (the coordinates
of the center, and radius) of circle that needs to be drawn.
We do this repeatedly until the user is done (empty input)
and then draw all the circles.
This is the kind of code we'd like to write:
# ... For brevity, we're not showing the import, setting up drawtool etc ...
# Read circle data from the user:
line = input('Enter circle parameters: ')
while line != '':
process_line(line)
line = input('Enter circle parameters: ')
# A method that'll access the list of circles
draw_circles()
dt.display()
What we'll do is have a list of circles:
# The list of circles
circles = []
def process_line(line):
# Code for extracting the center coordinates and radius
# This will add to the list circles
def draw_circles():
# Code for drawing the circles: will access the list circles
line = input('Enter circle parameters: ')
while line != '':
process_line(line)
line = input('Enter circle parameters: ')
draw_circles()
dt.display()
Here, the variable
circles
is called a global variable because it can be
access inside other functions defined in the file.
So, what would be an example of a non-global variable?
Let's fill out the code and see:
circles = [] # The global variable
def process_line(line):
parts = line.split() # parts is a local variable
x = float(parts[0])
y = float(parts[1])
r = float(parts[2])
circle = (x,y,r) # We've used a tuple here!
circles.append (circle) # Accessing global circles
def draw_circles():
dt.set_color('b')
for c in circles: # Accessing global circles
dt.draw_circle(c[0], c[1], c[2])
line = input('Enter circle parameters: ')
while line != '':
process_line(line)
line = input('Enter circle parameters: ')
draw_circles()
dt.display()
Let's create a simpler example to illustrate:
Consider this:
x = 5
def some_func():
y = x + 1
print(y)
def some_other_func():
z = x + 2
print(z)
# print(y) # This would fail: we can't access y here
some_func() # Prints 6
some_other_func() # Prints 7
Let's point out:
Thus: to share variables across functions, define the
variables outside the functions.
In which case they become global variables.
That would be the end of it, but there's one more complication:
You cannot modify a global variable inside a function without
explicitly stating an intention to do so.
So, suppose we wanted to modify x in the example:
x = 5
def some_func():
global x # Explicit statement of intent to modify
x = x + 1
y = x + 1
print(y)
def some_other_func():
z = x + 2
print(z)
some_func() # Prints 7
some_other_func() # Prints 8
Now let's go back to the circle-drawing example to see an
instance where modifying a global is useful:
Suppose we want to track the smallest circle (smallest radius)
and draw that circle in red.
Thus, as we get user input line-by-line, we'll need to
update the smallest.
Here's part of the code:
# For brevity, we're not showing the import, setting up drawtool etc
# ... (stuff left out) ...
# Global variable circles (a list) available to all functions
circles = []
smallest_r = 10
smallest = None
def process_line(line):
global smallest_r, smallest # Identify globals being modified
parts = line.split()
x = float(parts[0])
y = float(parts[1])
r = float(parts[2])
circle = (x,y,r)
if r < smallest_r:
smallest_r = r # Modifying global smallest_r
smallest = circle # Modifying global smallest
circles.append (circle) # Accessing global circles
def draw_circles():
# Fill in the code here to draw the smallest in red
# and the other circles in blue.
# The rest of the code is the same as before ... (read line by line etc)
1.10 Exercise:
In
my_circles.py,
copy over the above and from the earlier example, and then
fill in code in the
draw_circles()
function to complete the program. When the user types, for example,
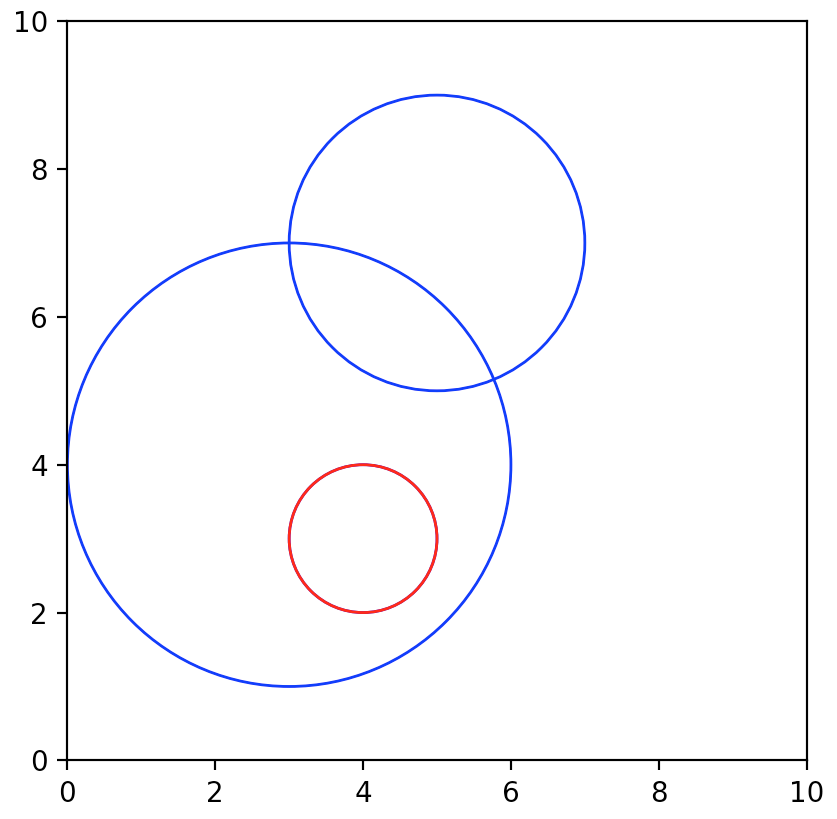
Enter circle parameters: 3 4 3
Enter circle parameters: 4 3 1
Enter circle parameters: 5 7 2
Enter circle parameters:
the output should be:
1.4 Advanced topic: multiple files
Large Python applications consists of tens of thousands of lines of
code.
Most such applications actually consist of hundreds of Python
programs bundled together and where one program can call functions in another.
We've already seen examples with the use of drawtool and wordtool.
Why are applications broken into multiple files?
One large file is unwieldy to understand and work with in an
editor (imagine the scrolling difficult with a thousand lines).
It's much easier to separate out functionality and test each
piece. Robustly tested programs can be left alone while refining
those that need work.
Separated functionality is useful in other projects.
If one piece needs upgrading, you can upgrade just that part
if it's in a separate file.
Let's build a simple example:
Suppose we put together a file called
my_math_functions.py
which has
import math
pi = 3.141
def square(x):
return x*x
def cube(x):
return x*x*x
def distance(x1, y1, x2, y2):
# Write your code here
Then in an another file called
my_math_application.py
you could write:
import my_math_functions as m
x = 2
y = m.square(5)
print(y)
x2 = 3
y2 = m.cube(x2)
print(y2)
d = m.distance(x,y, x2, y2)
print(d)
Notice the
import statement at the top
of the file:
import my_math_functions as m
This has the
import
keyword, the name of the other file, and a shortcut.
If we did not have the shortcut, we'd have to write code
like:
import my_math_functions
x = 2
y = my_math_functions.square(5)
print(y)
Which is perfectly legit but a bit tedious.
To access something from another file, we use the dot
(period):
y = m.square(5)
One can access a variable in the other file as well.
print(m.pi)
1.11 Exercise:
Complete the code for the
distance()
function and write the above two programs (using the
file names as above) so that the output is:
25
27
2.23606797749979
1.5 Advanced topic: string formatting and numbers
Consider this program:
x = 0
for i in range(5):
print('i=', i, 'x=', x)
x += 0.1
There are really three questions here, the second of which is a
bit subtle.
The first one is: why doesn't Python see that most of the
other values are bring printed nice, so why not print
0.3
instead of
0.30000000000000004?
The second, more sutble one, is: our for-loop clearly wants
to increment by 0.1, which means x should be 0.3 and not
0.30000000000000004.
The third implied question is: how do we actually limit
the number of digits printed after the decimal?
Let's answer these questions:
Why doesn't Python recognize unnecessary digits?
This is because Python does not want to second guess the
programmer's intent.
Maybe you do want the digits.
How did 0.3 become 0.30000000000000004?
A computer's memory has two kinds of limitations,
and one "feature".
One: it cannot store beyond a certain accuracy (and
computers differ based on their hardware).
Two: when calculations are performed, this storage
limitation forces some arithmetic to be slightly wrong
(many digits after the decimal point).
The "feature" is that computers store binary numbers,
not our kind of decimal numbers. This means a decimal
version of a binary number might have to be an approximation.
OK, how do we actually print nicely?
This is a bit of an advanced topic, so we'll only
provide a simple example.
The solution is to use a special set of formatting
commands, like the ones you saw a long time ago (remember \n?)
Here's how it works for the above program:
x = 0
for i in range(5):
format_string = 'i = {0:2d} x = {1:.2f}'
string_to_print = format_string.format(i, x)
print(string_to_print)
x += 0.1
Let's explain:
A format string is the eventual desired string that needs
to be printed but with some placeholders:
format_string = 'i = {0:2d} x = {1:.2f}'
In this case, there are two placeholders:
format_string = 'i = {0:2d} x = {1:.2f}'
Placeholders are enclosed in curly brackets.
Each placeholder begins with a number that will eventually
determine which variable gets its value into the placeholder.
This is what lets
format()
put the value of i in place of the "0" and the value of x
in place of the "1".
All that's left to explain are the cryptic commands
that follow the "0" and "1" respectively:
format_string = 'i = {0:2d} x = {1:.2f}'
The first one says, in effect, "use a minimum of 2 spaces and expect
an integer". The second says "expect a float and restrict the
number of post-decimal digits to 2".
String formatting has more to it, but that's all we'll say about it here.
1.6 Randomness
As we've seen throughout the course, it is useful to be able
to have Python generate random numbers:
We use random numbers to answer statistical questions.
Random numbers were also useful in creating patterns, as in art.
However, there's an important thing to know about random generation.
Consider this program:
import random
#random.seed(123)
for i in range(5):
x = random.uniform(1.0, 10.0)
print(x)
1.13 Exercise:
Type up the above
my_random_example.py.
Run it multiple times and observe the output. Next, un-comment
the line
#random.seed(123)
and run it again multiple times.
Then, change the number 123 in the seed to any number between 1 and
1000, and once more run the program many times.
How random generation works:
Python uses a mathematical function with a so-called "seed"
to produce random numbers.
The numbers aren't really random, because a particular
seed will produce the same numbers, which is why they're called
pseudorandom numbers.
However, if we're doing things like computing averages,
a pseudorandom sequence, provided it's long enough, is a reasonably
good approximation.
Is there ever a reason to fix a seed?
Turns out, yes. It's very useful for debugging.
Using a seed causes your program to be repeatable
(with the same pseudorandom sequence).
So, typically, one uses a seed when getting your program
to work.
After it's working, you can comment out the seed.
If a seed is not provided, Python uses the local time
or something like that as the seed, so that repeated runs
produce different results.
1.7 What else is there in Python?
Our goal in this almost-final module was to:
Introduce the all-important topic of arrays.
Lightly sketch a few advanced topics to introduce ideas and
show some examples, without expecting mastery of all the details.
In the next module, we will dive into examples from across the
disciplines. Some of these advanced topics will be useful
So, one might ask: what's left in Python to learn?
Quite a bit it turns out:
Like many modern programming languages, Python is large enough
that one needs a few courses to experience all of it.
Some concepts are advanced enough to need weeks to cover
(example: objects).
Others need a background in data structures to
understand how they work (example: dictionaries).
Yet others involve library functions and external packages.
Do you need to learn more? Is what we've learned enough to achieve a
good deal?
We'll have more to say about this in a later module.