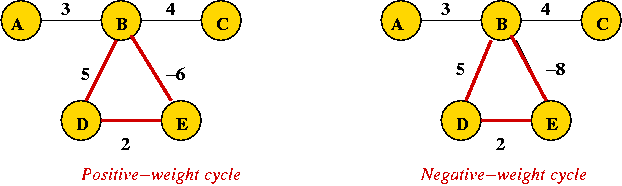
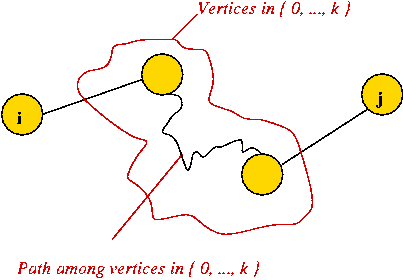
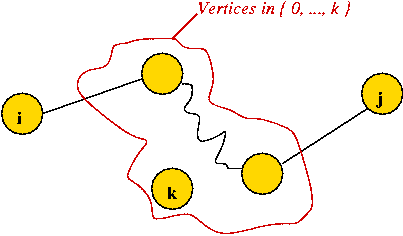
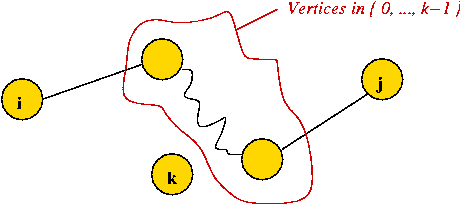
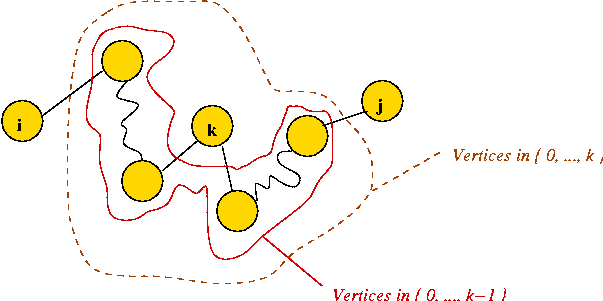
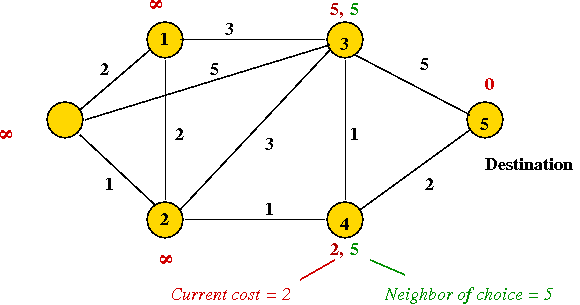
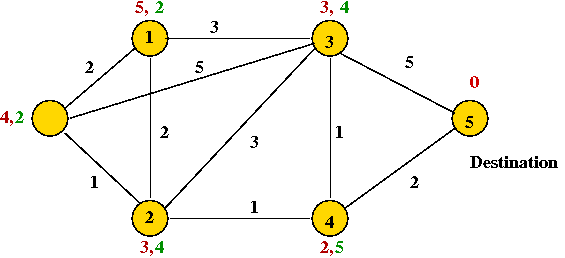
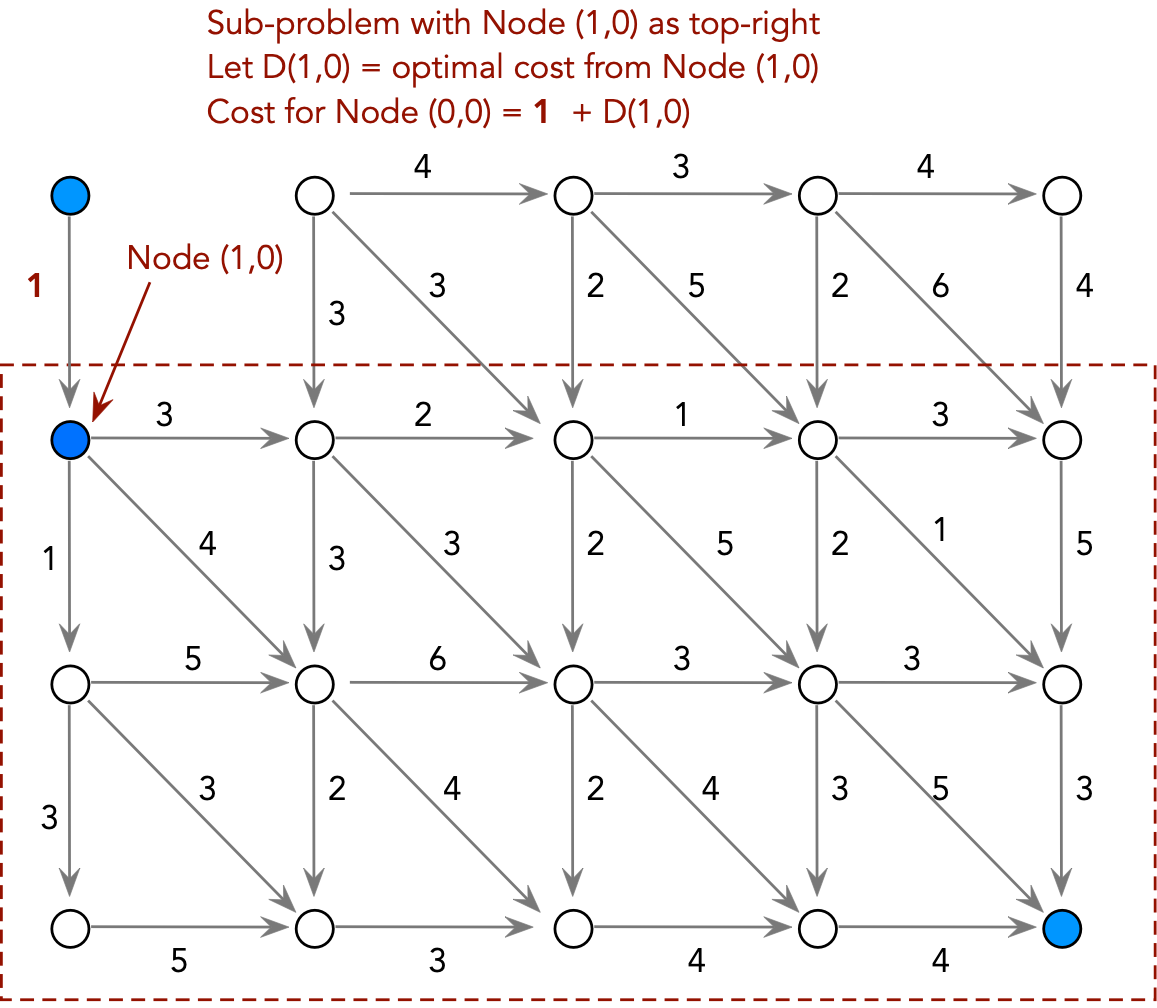
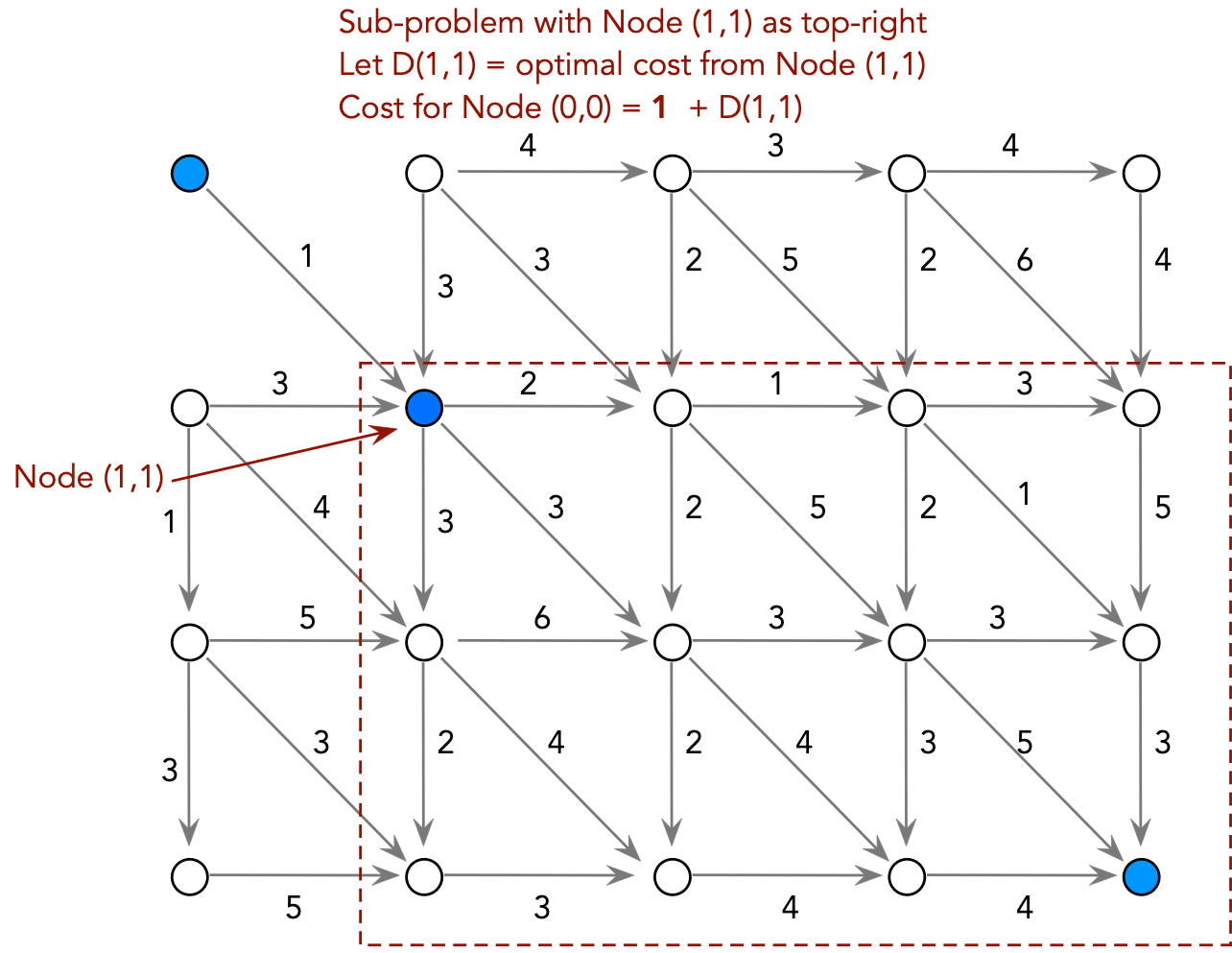
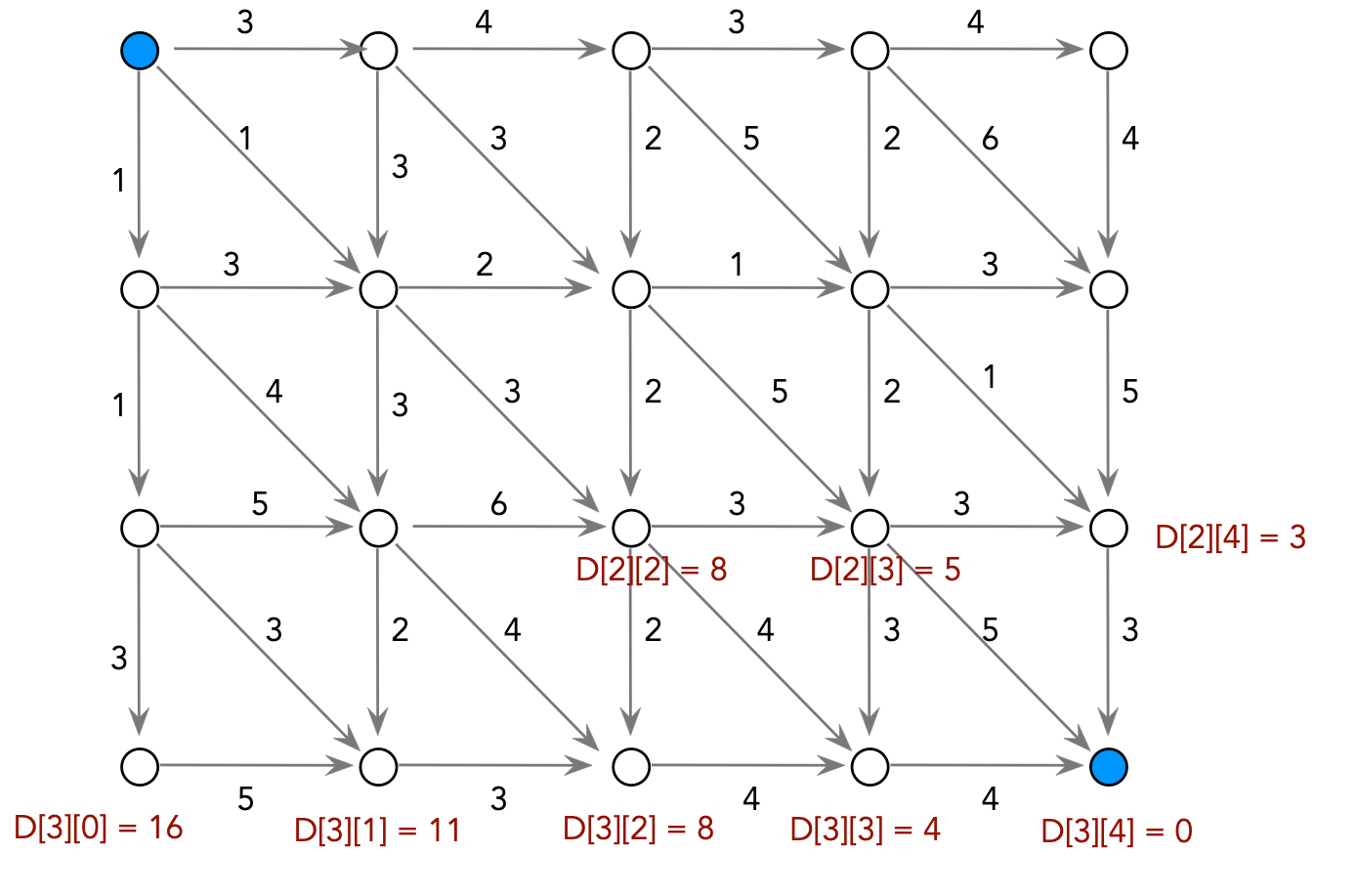
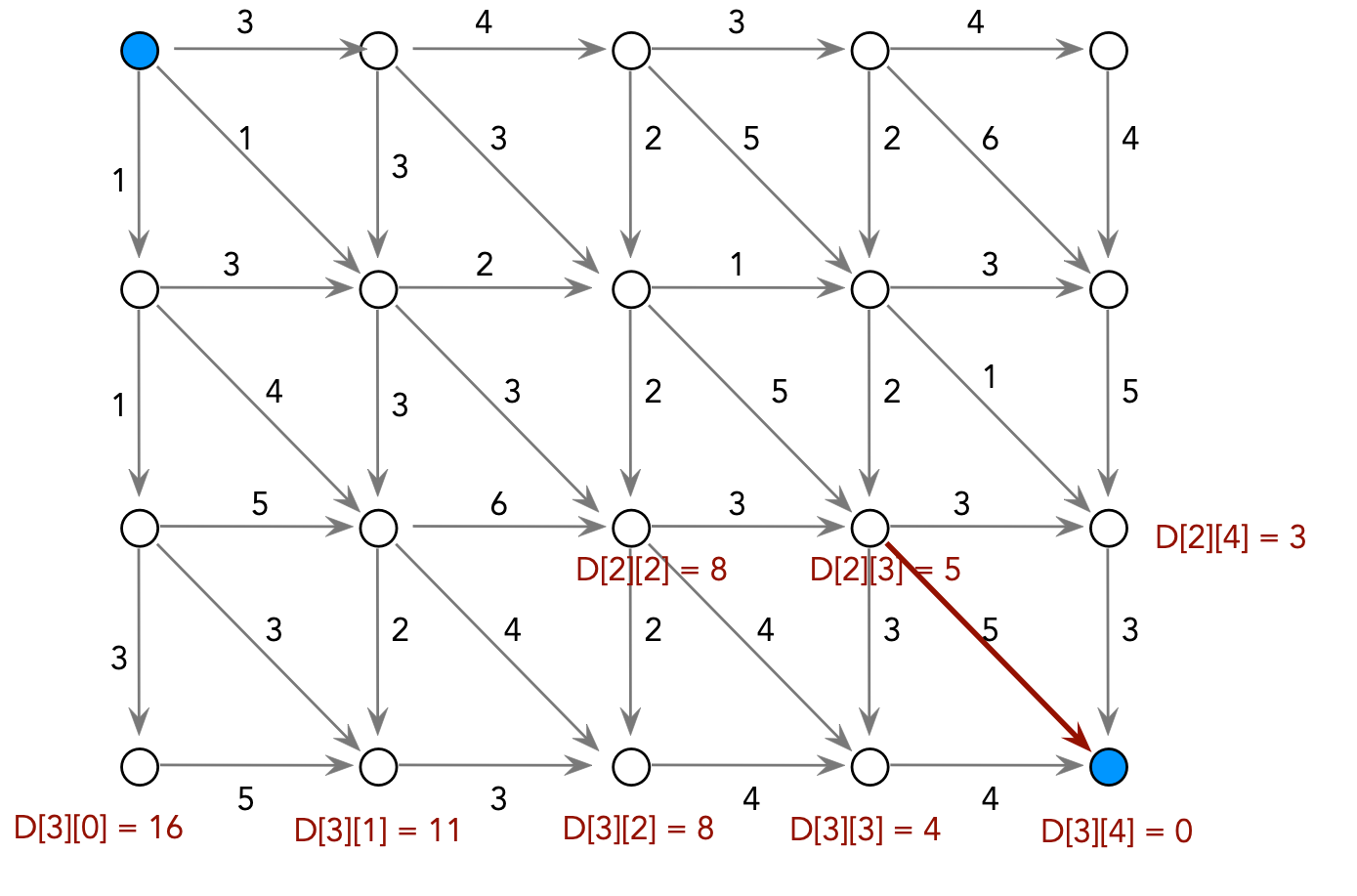
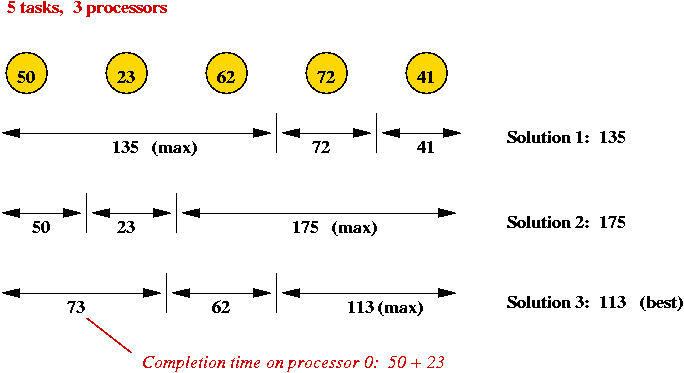
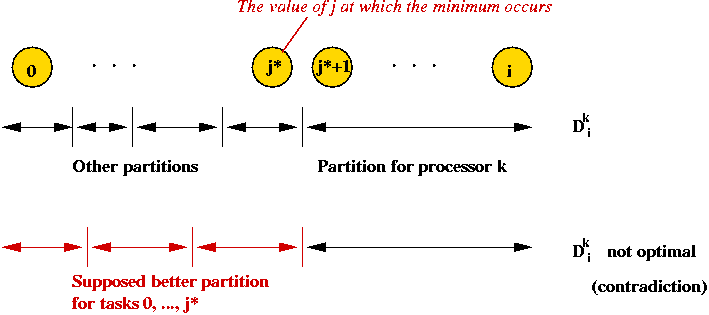
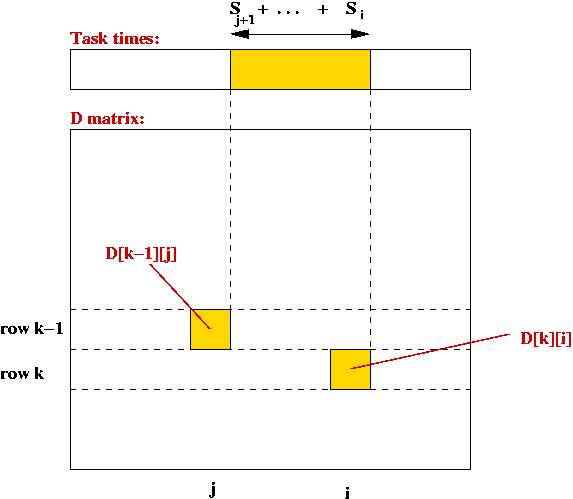
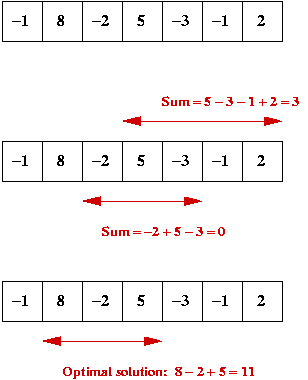
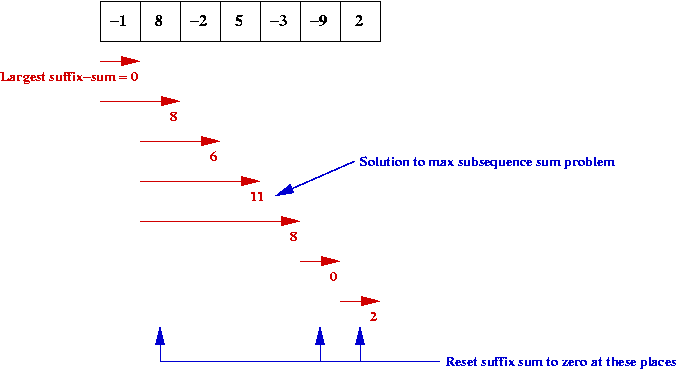
Consider the following problem:
- We are given a list of keys that will be repeatedly accessed.
- Example: The keys "A", "B", "C", "D" and "E".
- An example access pattern: "A A C E D B C E A A A A E D D D" (etc).
- We are also given access frequencies (probabilities) , e.g.
| Key | Access probability |
| A | 0.4 |
| B | 0.1 |
| C | 0.2 |
| D | 0.1 |
| E | 0.2 |
(Thus, "A" is most frequently accessed).
- Objective: design a data structure to enable accesses as
rapidly as possible.
Past solutions we have seen:
- Place keys in a balanced binary tree.
⇒ a frequently-accessed item could end up at a leaf.
- Place keys in a linked list (in decreasing order of probability).
⇒ lists can be long, might required O(n) access time
(even on average).
- Use a self-adjusting data structure (list or self-adjusting tree).
In-Class Exercise 9.8:
Consider the following two optimal-list algorithms:
- Algorithm 1
Algorithm: optimalList (E, p)
Input: set of elements E, with probabilities p
// Base case: single element list
1. if |E| = 1
2. return list containing E
3. endif
4. m = argmaxi p(i) // Which i gives the max
5. front = new node with m
6. list = optimalList (E - {m}, p - pm)
7. return list.addToFront (front)
- Algorithm 2:
Algorithm: optimalList2 (E, p)
Input: set of elements E, with probabilities p
// Base case: single element list
1. if |E| = 1
2. return list containing E
3. endif
4. for i=0 to E.length
5. front = new node with i
6. list = optimalList2 (E - {i}, p)
7. tempList = list.addToFront (front)
8. cost = evaluate (tempList)
9. if cost < bestCost
10. best = i
11. bestList = tempList
12. endif
13. endfor
14. return bestList
Analyze the running time of each algorithm in terms of the
number of list elements n.
Optimal binary search tree:
- Analogue of the optimally-arranged list.
- Idea: build a binary search tree (not necessarily balanced)
given the access probabilities.
- Example:
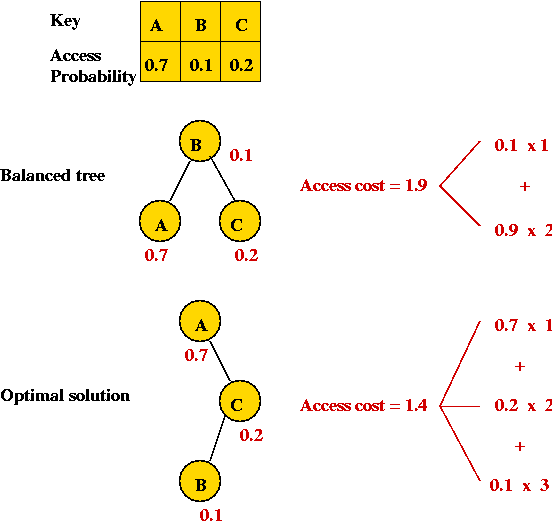
- Overall objective: minimize average access cost:
- For each key i, let d(i) be its depth in the
tree
(Root has depth 1).
- Let pi be the probability of access.
- Assume n keys.
- Then, average access cost = d(0)*p0 + ... + d(n-1)*pn-1.
In-Class Exercise 9.9:
Which of the two list algorithms could work for
the optimal binary tree problem? Write down pseudocode.
Dynamic programming solution:
- First, sort the keys.
(This is easy and so, for the remainder, we'll assume keys
are in sorted order).
- Suppose keys are in sorted order:
- If we pick the k-th key to be the root.
⇒ keys to the left will lie in the left sub-tree and keys
to the right will lie in the right sub-tree.
- This also works for any sub-range i, ..., j of the keys:
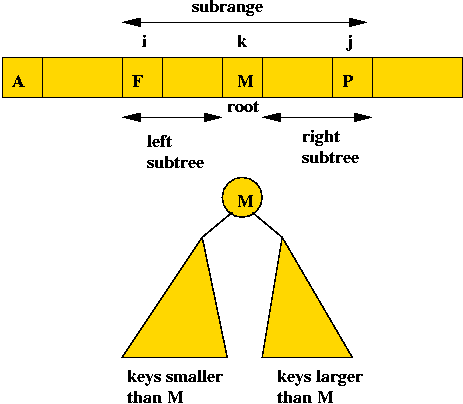
- Define \(C(i,j)\) = cost of an optimal tree formed using
keys i, ..., j (both inclusive).
- Now suppose, in the optimal tree, the root is "the key at
position k".
- The left subtree has keys in the range i, ..., k-1.
⇒ optimal cost of left subtree is \(C(i, k-1)\).
- The right subtree has keys k+1, ..., j.
⇒ optimal cost of right subtree is \(C(k+1, j)\)
- It is tempting to assume that \(C(i, j) = C(i, k-1) +
C(k+1, j)\)
⇒ this doesn't account for the additional depth of the left
and right subtrees.
- The correct relation is:
$$
C(i,j) \eql p_k + C(i,k-1) + (p_i + \ldots + k_{k-1})
+ C(k+1,j) + (p_{k+1} + \ldots + p_j)
$$
- To understand why this must be true, let's re-write \(C(i, k-1)\)
as
$$
C(i,k-1) \eql (p_i d_i + \ldots + p_{k-1} d_{k-1})
$$
where the \(d_i\)'s are the depths of the items
in \(C(i, k-1)\).
- Because \(C(i, k-1)\)'s depth increases by 1, in the
larger tree, these items will have depth
\(d_i + 1\). Thus, the new depth is
$$\eqb{
p_i (d_i + 1) + \ldots + p_{k-1} (d_{k-1} + 1)
& = &
(p_i + \ldots + p_{k-1}) + (p d_i + \ldots + p_{k-1} d_{k-1})\\
& = &
(p_i + \ldots + p_{k-1}) + C(i,k-1)\\
}$$
- The same argument applies to the right sub-tree
and \(C(k+1,j)\).
- Therefore, \(C(i, j)\) can be written more compactly as:
$$
C(i,j) \eql C(i,k-1) + C(k+1,j) + (p_i + \ldots + p_j)
$$
- Now, we assumed the optimal root for \(C(i, j)\) was the \(k\)-th key.
⇒ in practice, we must search for it.
⇒ consider all possible keys in the range i, ..., j
as root.
- Hence the dynamic programming recurrence is:
$$
C(i,j) \eql \min_k \;\;\;\; C(i,k-1) + C(k+1,j) + (p_i + \ldots + p_j)
$$
where \(k\) ranges over \(i, \ldots, j\).
- The solution to the overall problem is: \(C(0, n-1)\).
- Observe:
- Once again, we have expressed the cost of the
optimal solution in terms of the optimal cost of sub-problems.
- Base case: \(C(i, i) = p_i\).
Implementation:
- Writing code for this case is not as straightforward as in
other examples:
- In other examples (e.g., load balancing), there was a natural
sequence in which to "lay out the sub-problems".
- Consider the following pseudocode:
// Initialize C and apply base cases.
for i=0 to numKeys-2
for j=i+1 to numKeys-1
min = infinity
sum = pi + ... + pj;
for k=i to j
if C(i, k-1) + C(k+1, j) + sum < min
min = C(i, k-1) + C(k+1, j) + sum
...
Suppose, above, i=0, j=10 and k=1 in the innermost loop
- The case C(i, k-1) = C(0,0) is a base case.
- But the case C(k+1, j) = C(2, 10) has NOT been
computed yet.
- We need a way to organize the computation so that:
- Sub-problems are computed when needed.
- Sub-problems are not re-computed unnecessarily.
- Solution using recursion:
- Key idea: use recursion, but check whether computation has
occurred before.
- Pseudocode:
Algorithm: optimalBinarySearchTree (keys, probs)
Input: keys[i] = i-th key, probs[i] = access probability for i=th key.
// Initialize array C, assuming real costs are positive (or zero).
// We will exploit this entry to check whether a cost has been computed.
1. for each i,j set C[i][j] = -1;
// Base cases:
2. for each i, C[i][i] = probs[i];
// Search across various i, j ranges.
3. for i=0 to numKeys-2
4. for j=i+1 to numKeys-1
// Recursive method computeC actually implements the recurrence.
5. C[i][j] = computeC (i, j, probs)
6. endfor
7. endfor
// At this point, the optimal solution is C(0, numKeys-1)
8. Build tree;
9. return tree
Output: optimal binary search tree
Algorithm: computeC (i, j, probs)
Input: range limits i and j, access probabilities
// Check whether sub-problem has been solved before.
// If so, return the optimal cost. This is an O(1) computation.
1. if (C[i][j] >= 0)
2. return C[i][j]
3. endif
// The sum of access probabilities used in the recurrence relation.
4. sum = probs[i] + ... + probs[j];
// Now search possible roots of the tree.
5. min = infinity
6. for k=i to j
// Optimal cost of the left subtree (for this value of k).
7. Cleft = computeC (i, k-1)
// Optimal cost of the right subtree.
8. Cright = computeC (k+1, j)
// Record optimal solution.
9. if Cleft + Cright < min
10. min = Cleft + Cright
11. endif
12. endfor
13. return min
Output: the optimal cost of a binary tree for the sub-range keys[i], ..., keys[j].
Note: In the above pseudocode, we have left out a small detail:
we need to handle the case when a subrange is invalid (e.g., when k-1 < i).
Can you see how this case can be handled?
Analysis:
- The bulk of the computation is a triple for-loop, each ranging
over n items (worst-case)
⇒ O(n3) overall.
- Note: we still have account for the recursive calls:
- Each recursive call that did not enter the innermost loop,
takes time O(1).
- But, this occurs only O(n2) times.
⇒ Overall time is still O(n3).
Dynamic Programming: Summary
So, what to make of dynamic programming and its "strangeness"?
Key points to remember:
- The method sets up a recurrence between sub-problems
⇒ solutions to sub-problems can be assembled into a solution
to the actual problem of interest.
- Sometimes, recursion is useful as the way to implement
the recurrence. Sometimes not.
- Example: optimal binary tree (recursion works).
- Example: Floyd-Warshall (recursion does not work).
- The recurrence is set up in terms of the optimal
"cost" or "value" of a sub-problem solution.
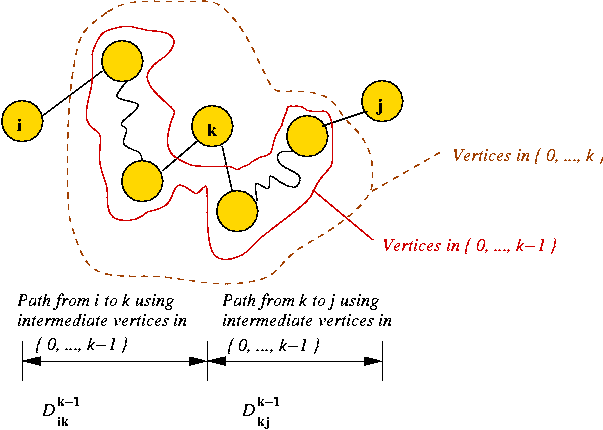
- Example: In Floyd-Warshall, the cost Dkij
is the cost of a shortest-path.
- Example: In optimal trees, C(i,j) is the optimal access
time.
- If the recurrence can be set up, a problem is a potential
candidate for dynamic programming.
- Just because dynamic programming can be set up doesn't mean
it will be the most efficient solution.
In-Class Exercise 9.10:
For the moment, let's set aside efficiency and merely get some
practice with seeing if dynamic programming can be set up properly.
Consider an array A with n elements and the following
three problems:
- Let \(D_{ij} = \max_{i\leq m\leq j} A[m]\), the largest
value in the range \(i\) to \(j\).
- Let \(D_{ij} = \max_{i\leq m,n\leq j} A[m]+A[n]\), the largest
sum of two elements in the range \(i\) to \(j\).
- Let \(D_{ij} = \max_{i\leq m < j} A[m]+A[m+1]\), the largest
sum of two consecutive
elements in the range \(i\) to \(j\).
For each of the above problems, can
\(D_{ij}\) be written
in terms of \(D_{ik}\) and \(D_{kj}\) where \(i\leq k\leq j\),
with possibly a few additional terms like \(A[k]\)?