By the end of this module, you will be able to:
Simple description:
Example:
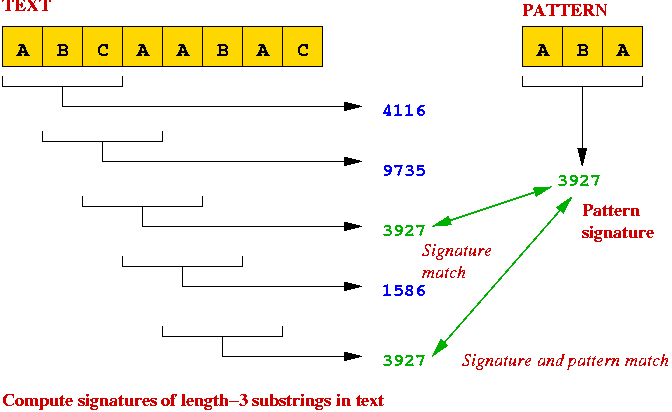
A B A B A C B A B A B A
B A C
Practical issues:
public interface PatternSearchAlgorithm {
public int findFirstOccurrence (char[] pattern, char[] text);
public int[] findAllOccurrences (char[] pattern, char[] text);
}
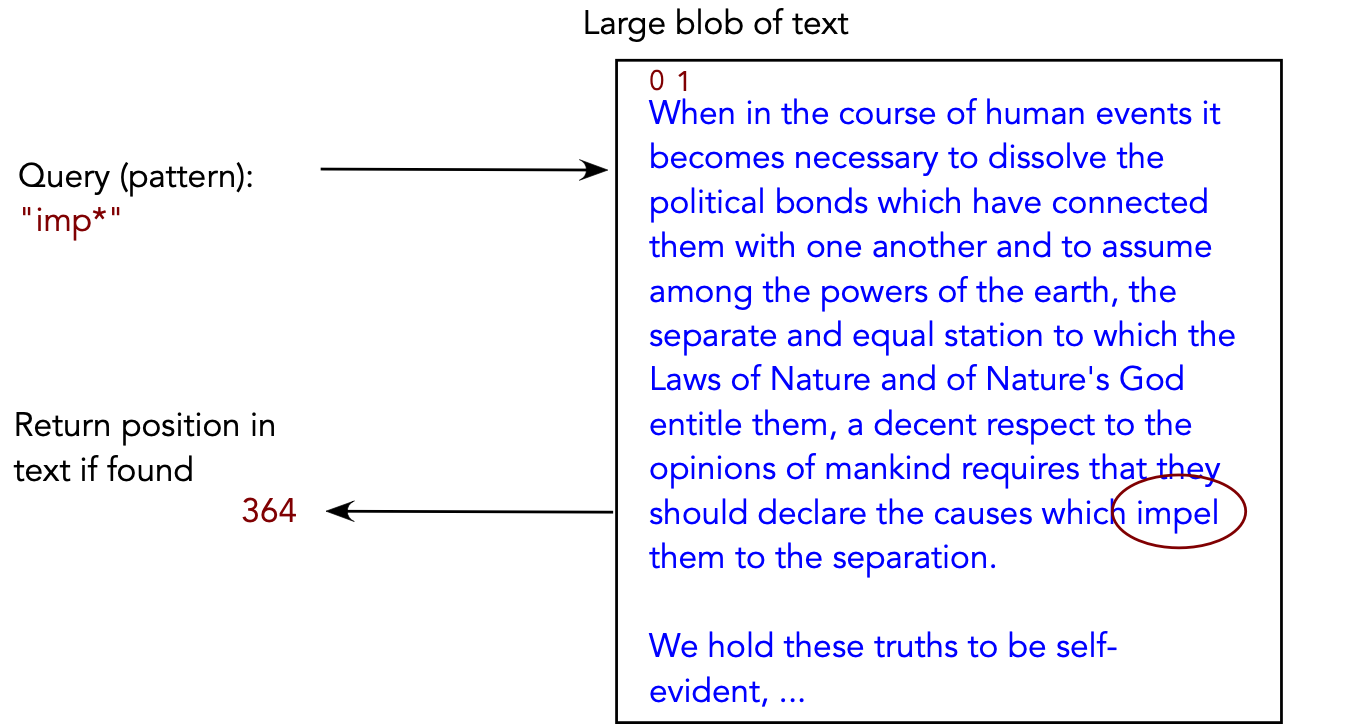
grep in*face *.java
(Find all lines containing words that match the pattern
"in*face" in all .java files).
In-Class Exercise 5.1:
Download this template
and implement the straightforward iterative algorithm for
finding a pattern within a text.
Both the pattern and text are of type char[] (arrays of characters).
You will also need UniformRandom.java.
Key ideas:
Details:
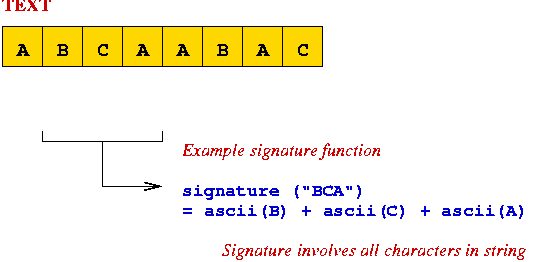
⇒ signature involves all characters
⇒ computing signature for each substring takes O(m) time.
⇒ no faster than naive search.
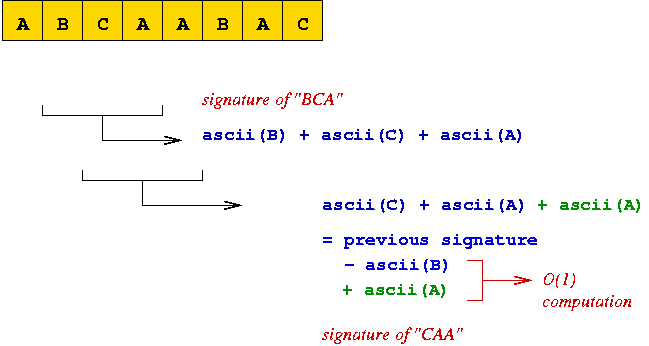
⇒ next signature can be computed quickly (O(1)).
Algorithm: SignaturePatternSearch (pattern, text) Input: pattern array of length m, text array of length n 1. patternHash = computePatternSignature (pattern); 2. texthash = compute signature of text[0]...text[m-1] 3. lastPossiblePosition = n - m // No match possible after this position: 4. textCursor = 0 5. while textCursor <= lastPossiblePosition 6. if textHash = patternHash // Potential match. 7. if match (pattern, text, textCursor) 8. return textCursor // Match found 9. endif 10. endif 11. textCursor = textCursor + 1 12. textHash = compute signature of text[textCursor],...,text[textCursor+m-1] 13. endwhile 14. return -1 Output: position in text if pattern is found, -1 if not found.
fi+1 = d * (fi -
text[i]*dm-1) + text[i+m]
we can instead compute
Pseudocode:
Algorithm: RabinKarpPatternSearch (pattern, text)
Input: pattern array of length m, text array of length n
// Compute the signature of the pattern using modulo-arithmetic.
1. patternHash = computePatternSignature (pattern);
// A small optimization: compute dm-1 mod q just once.
2. multiplier = dm-1 mod q;
// Initialize the current text signature to first substring of length m.
3. texthash = compute signature of text[0]...text[m-1]
// No match possible after this position:
4. lastPossiblePosition = n - m
// Start scan.
5. textCursor = 0
6. while textCursor <= lastPossiblePosition
7. if textHash = patternHash
// Potential match.
8. if match (pattern, text, textCursor)
// Match found
9. return textCursor
10. endif
// Different strings with same signature, so continue search.
11. endif
12. textCursor = textCursor + 1
// Use O(1) computation to compute next signature: this uses
// the multiplier as well as d and q.
13. textHash = compute signature of text[textCursor],...,text[textCursor+m-1]
14. endwhile
15. return -1
Output: position in text if pattern is found, -1 if not found.
Example:
A B A B A C B A C A C A B A TextHash=2199650 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2231425 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2199651 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2231458 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2200705 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2265187 patternHash=2231457
B A C A
A B A B A C B A C A C A B A TextHash=2231457 patternHash=2231457
B A C A
A B A B A C B A C A C A B A Pattern found
B A C A
Analysis:
In practice:
In-Class Exercise 5.2: Download this template and implement the Rabin-Karp algorithm but with a different signature function. Use the simple signature of adding up the ascii codes in the string (shown in the second figure in this section).
Key ideas:
B A B C A B A B A B A B B A C A A B
B A B A B B
B A B C A B A B A B A B B A C A A B
B A B A B B
Example:
| Mismatch Position | nextIndex | ||
| 0 | 0 | ||
| 1 | 0 | ||
| 2 | 0 | ||
| 3 | 1 | (Infer: match up to 0) | |
| 4 | 2 | (Infer: match up to 1) | |
| 5 | 3 | (Infer: match up to 2) |
B A B C A B A B A B A B B A C A A B Matched up to pattern position 0
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 1
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 2
B A B A B B
B A B C A B A B A B A B B A C A A B Mismatch at pattern position 3 nextIndex=1
B A B A B B
B A B C A B A B A B A B B A C A A B Mismatch at pattern position 1 nextIndex=0
B A B A B B
B A B C A B A B A B A B B A C A A B Mismatch at start of pattern: shifting right
B A B A B B
B A B C A B A B A B A B B A C A A B Mismatch at start of pattern: shifting right
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 0
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 1
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 2
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 3
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 4
B A B A B B
B A B C A B A B A B A B B A C A A B Mismatch at pattern position 5 nextIndex=3
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 3
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 4
B A B A B B
B A B C A B A B A B A B B A C A A B Matched up to pattern position 5
B A B A B B
B A B C A B A B A B A B B A C A A B Pattern found
B A B A B B
Computing the nextIndex function:
E A A A A E A A A A C A A A A
A A A A F
E A A A A E A A A A C A A A A
A A A A F
Here, the overall "shift" was only one space.
E A B C D E A A A A C A A A A
A B C D F
E A B C D E A A A A C A A A A
A B C D F
In this case: the overall shift was "four spaces" (much better).
In-Class Exercise 5.3:
Consider this partial match:
E A B C A B C A B A B C E A A A A C A A A A
A B C A B C A F
How many letters can we skip? What about this case (below)?
E A B C B B C A C A B C E A A A A C A A A A
A B C B B C A F
E A B A B E A A A A C A A A A
A B A B F
E A B A B E A A A A C A A A A
A B A B F
The amount shifted depends on how large a "prefix of the
pattern" is a "suffix of the matched-text".
E A A A A E A A A A C A A A A A A A A F
E A A A A E A A A A C A A A A
A A A A F
E A B A B E A A A A C A A A A A B A B F
The relation with nextIndex:
E A A A A E A A A A C A A A A Mismatch at pattern position 4 nextIndex=3
A A A A F
E A A A A E A A A A C A A A A
A A A A F
E A B A B E A A A A C A A A A Mismatch at pattern position 4 nextIndex=2
A B A B F
E A B A B E A A A A C A A A A
A B A B F
Pseudocode:
Algorithm: KnuthMorrisPrattPatternSearch (pattern, text)
Input: pattern array of length m, text array of length n
// Compute the nextIndex function, stored in an array:
1. nextIndex = computeNextIndex (pattern)
// Start the pattern search.
2. textCursor = 0
3. patternCursor = 0
4. while textCursor < n and patternCursor < m
5. if text[textCursor] = pattern[patternCursor]
// Advance cursors as long as characters match.
6. textCursor = textCursor + 1
7. patternCursor = patternCursor + 1
8. else
// Mismatch.
9. if patternCursor = 0
// If the mismatch occurred at first position, simply
// advance the pattern one space.
10. textCursor = textCursor + 1
11. else
// Otherwise, use the nextIndex function. The textCursor
// already points to the next place to compare in the text.
12. patternCursor = nextIndex[patternCursor]
13. endif
14. endif
15. endwhile
16. if patternCursor = m
// If there was a match, return the first position in the match.
17. return (textCursor - patternCursor)
18. else
19. return -1
Output: position in text if pattern is found, -1 if not found.
Algorithm: computeNextIndex (pattern)
Input: a pattern array of length m
1. nextIndex[0] = 0
2. for i=1 to m-1
3. nextIndex[i] = largest suffix of pattern[0]...pattern[i-1] that
is a prefix of pattern.
4. endfor
5. return nextIndex
Output: the nextIndex array (representing the nextIndex function)
Analysis:
The problems with previous algorithms:
The Boyer-Moore-Horspool algorithm:
Key ideas:
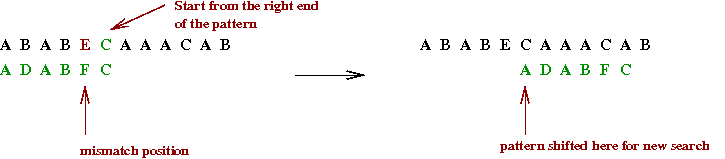
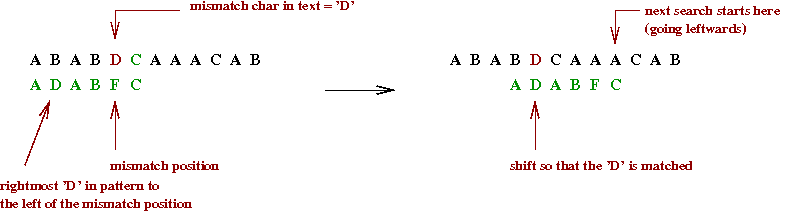
The worst-case running time is still O(mn), but it is easy to implement and practically fast.
The "Evil Bureaucracy" metaphor:
| OFFICIAL | ABBREVIATION | ||
| Assistant Director | A | ||
| Director | D | ||
| Managing Director | M | ||
| Chief Managing Director | C |
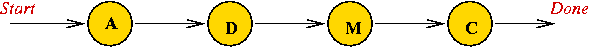

⇒
Here, "A" represents the state of "approval by A".
What is a DFA?
Example: consider a DFA to recognize the string "A B C D".
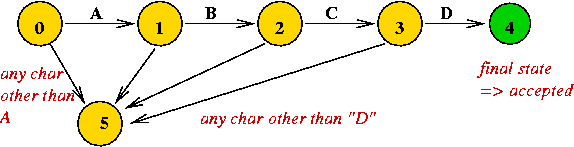
Two key questions about DFAs:
Example: consider this DFA
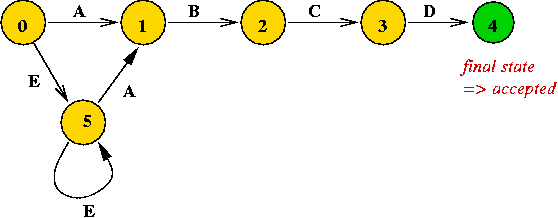
In-Class Exercise 5.4: Draw a DFA to find the first occurence of "A B C D" in a text consisting of the following structure: "... (zero or more E's) ... A ... (zero or more E's) ... B C D ... (anything)". Write the pseudocode equivalent of the DFA. That is, what does a DFA implementation in code (pseudocode) look like?
A DFA to find the first occurrence of "A B C D" in any text:
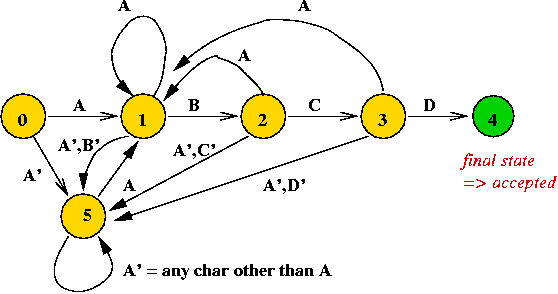
Another example: a DFA for the pattern "A B C A B D"
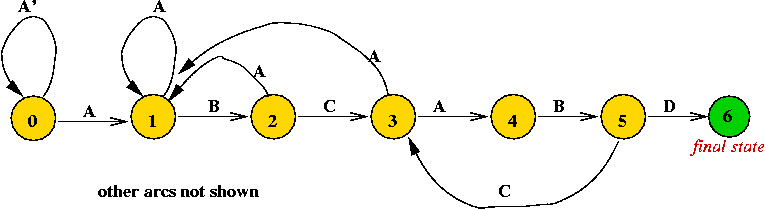
The nextState function:
Example:
| Input char | ||||
| Current state | A | B | C | D |
| 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 2 | 0 | 0 |
| 2 | 1 | 0 | 3 | 0 |
| 3 | 4 | 0 | 0 | 0 |
| 4 | 1 | 5 | 0 | 0 |
| 5 | 1 | 0 | 3 | 6 |
A A A B C A B C A B D Processing 'A': next-state = 1
A A A B C A B C A B D Processing 'A': next-state = 1
A A B B C A B C A B D Processing 'B': next-state = 2
A A B C C A B C A B D Processing 'C': next-state = 3
A A B C A A B C A B D Processing 'A': next-state = 4
A A B C A B B C A B D Processing 'B': next-state = 5
A A B C A B C C A B D Processing 'C': next-state = 3
A A B C A B C A A B D Processing 'A': next-state = 4
A A B C A B C A B B D Processing 'B': next-state = 5
A A B C A B C A B D D Processing 'D': next-state = 6
A A B C A B C A B D D Pattern found
A B C A B D
Building the nextState function:
Pseudocode:
Algorithm: DFAPatternSearch (pattern, text)
Input: pattern array of length m, text array of length n
// First, build the nextState function.
1. nextState = computeNextStateFunction (pattern)
// Now scan input character by character.
2. currentState = 0
3. for textCursor=0 to n-1
4. character = text[textCursor]
// Go to next state.
5. currentState = nextState[currentState][character]
// If it's the final state, we're done.
6. if currentState = m
7. return (textCursor - m + 1)
8. endif
9. endfor
10. return -1
Output: position in text if pattern is found, -1 if not found.
Algorithm: computeNextStateFunction (pattern) Input: pattern array of length m 1. for state=0 to m-1 2. for character=smallestChar to largestChar 3. patternPlusChar = concatenate (pattern, character) 4. k = length of longest suffix of patternPlusChar that is a prefix of pattern 5. nextState[state][character] = k 6. endfor 7. endfor
Analysis:
In practice:
What does "wildcard" mean?
ls *.java
Regular expressions:
In-Class Exercise 5.5: Construct the regular expression for the set {"D A B", "D A C", "D A B E", "D A C E", "D A B E E", "D A C E E",... }
The pattern-search problem we want to solve:
What is an NDFA?
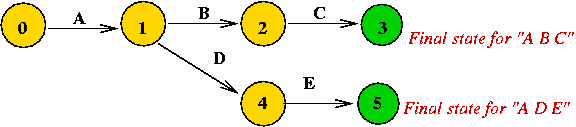
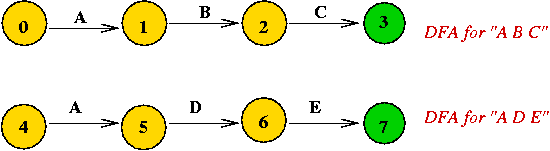
(States are numbered differently, to avoid confusion).
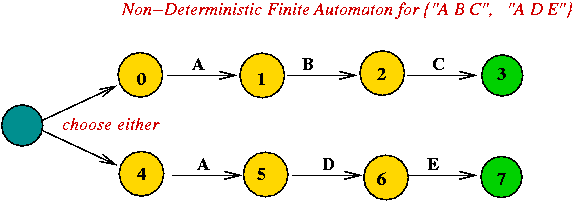
Constructing an NDFA from a regular expression:

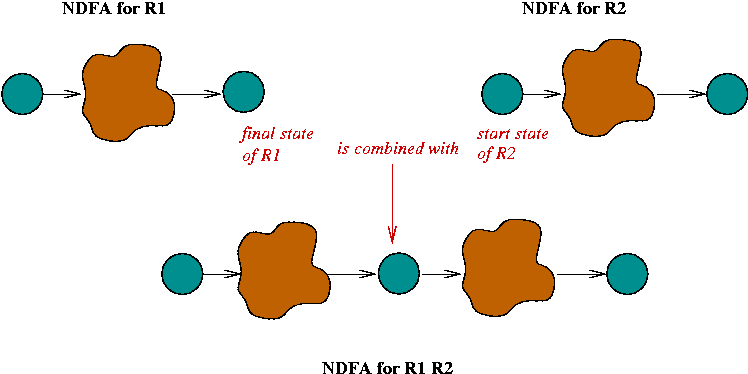
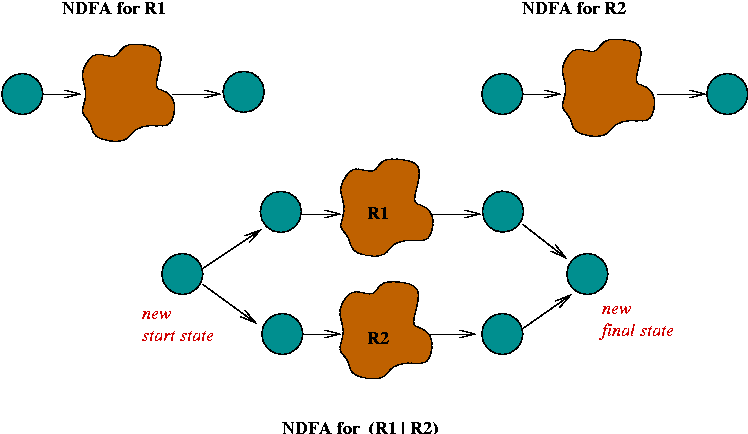
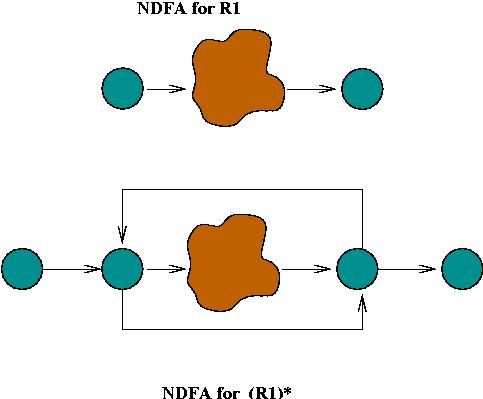
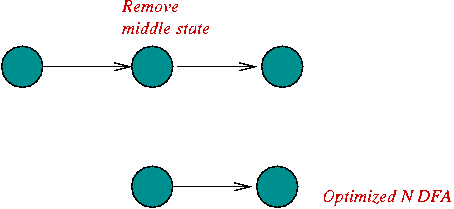
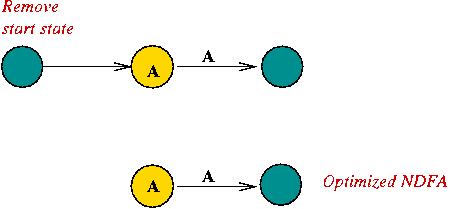
In-Class Exercise 5.6: Construct an NDFA for the regular expression "C (A | B) (A B)*". First, use the rules to construct an unoptimized version, then try to optimize it (reduce the number of states).
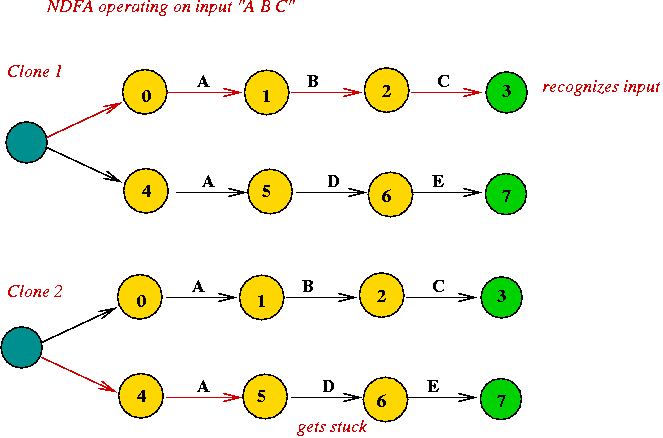
Two ways to "run" an NDFA on input:
Using a deque:
In-Class Exercise 5.7: This is a recursion-writing exercise. Write pseudocode describing a recursive algorithm to see if a given string (such as PatternSearch.java) matches a given wildcard pattern (such as Patt*nSearch.*). Your algorithm should solve the problem directly, without using DFAs or NDFAs.
In this section, we'll give an overview of how search engines work.
Three parts to search engines:
In-Class Exercise 5.8: Look up the "page rank" algorithm and describe how it works. What are the disadvantages of using that algorithm?
Indexing via an example:
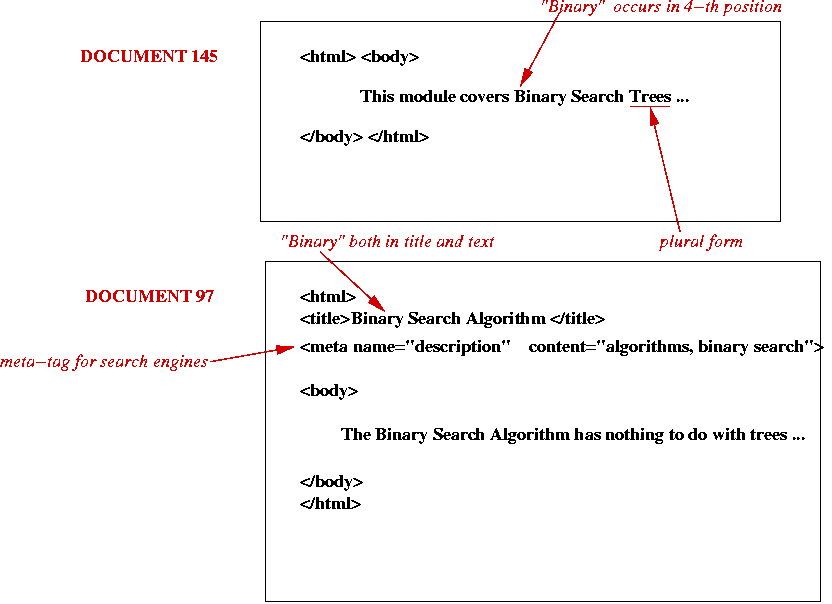
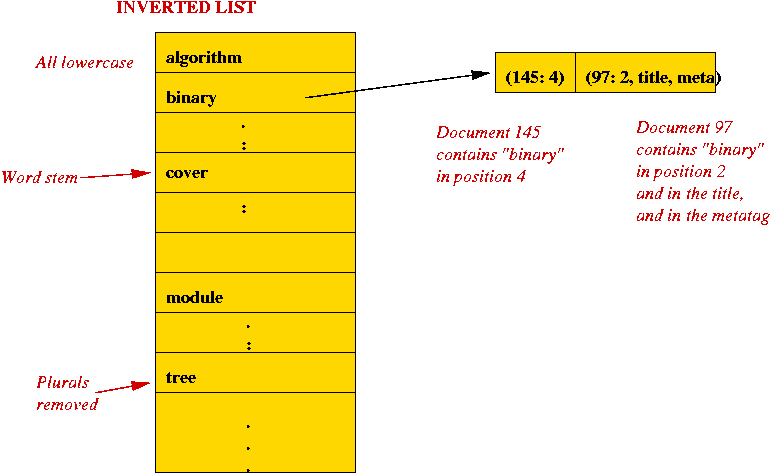
Query-handling: