![]()
Whenever an interpreter interprets a given piece of input, two things need to happen. First, the input needs to be parsed, or separated out, into its component parts in such a way that the parts can be easily worked with. Then the interpreter can go about its job of interpreting. The parsing deals with the syntactic considerations, and the interpreting deals with the semantic considerations.
![]()
![]()
The actual syntax that a programmer writes when working in a programming language like Scheme or Java is known as a concrete syntax. The syntax generated by a parser and used by an interpreter is known as an abstract syntax. Before we generate a parser, then, we need to decide on an abstract syntax, and how it will be represented. We will work with a small subset of Scheme defined by the grammar below.
<exp> ::= <number>
| <varref>
| (lambda (<var>) <exp>)
| (<exp> <exp>)
This grammar can work with numbers, variable references, lambda expressions of one variable, and applications of one expression to another.
In order to make an abstract syntax for this grammar, we need to decide on a name for each production in the grammar, and names for each nonterminal in the production. One possible choice is
<exp> ::= <number> lit (datum)
| <varref> varref (var)
| (lambda (<var>) <exp>) lambda (formal body)
| (<exp> <exp>) app (rator rand)
(In this example, rator stands for operator and rand stands for operand.)
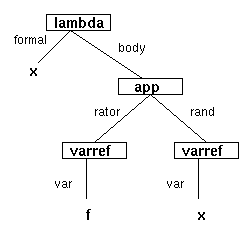
It is easiest to reason about an abstract syntax representation as an abstract syntax tree. As an example, the abstract syntax tree for the expression (lambda (x) (f x)), following the specification above, looks like this.
Chez Scheme provides a define-record mechanism. We will use a slightly different version of define-record developed by Erik Hilsdale. You can find the code in record.ss but please understand that I do not expect you to study the intricacies of that code. I merely want you to use it. Our version largely conforms to the Chez Scheme documentation, but provides a variant-case mechanism that will soon be used to "unparse" expressions.
We will use define-record to represent each of the four productions of our grammar above. We will associate with each production name a record type, and the fields in the record type will correspond to the names of the nonterminals. Here are the record definitions we will use:
(load "record.ss") (define-record lit (datum)) (define-record varref (var)) (define-record closure (formal body)) (define-record app (rator rand))
As you can tell if you read the section above from the Chez Scheme User's Guide, the first of these results in the definition of:
Look at this transcript to see what the last of the define-records above achieves:
> (define-record app (rator rand)) > make-app #> (define foo (make-app 'plus '8)) > (app? foo) #t > (app? +) #f > (app-rator foo) plus > (set-app-rand! foo 42) > (app-rand foo) 42 >
Incidentally, you would obtain an identical transcript if you omitted the (load "record.ss"). The version of define-record given therein conforms to the version of define-record provided by Chez Scheme. Although it's not standard Scheme, define-record is immensely useful in helping us create the structures needed for an abstract syntax. In particular, a parser can be defined very easily. The code can be found in parse.ss.
Notice that parse.ss begins by loading error.ss and record.ss. You need to download and save both these files to your working directory. error.ss redefines Scheme's error function, for reasons that will become apparent as you work through this lab. record.ss defines two new forms that extend Scheme by allowing for define-record and variant-case that work nicely together for parsing and interpreting.
If you know the concrete syntax of the language, the parser almost writes itself!
![]()
![]()
It is sometimes useful to be able to unparse something represented in abstract syntax. It is equally easy to write unparse in Scheme. The code can be found in unparse.ss.
![]()
![]()
> (parse 44) #(lit 44) > (parse 'x) #(varref x) > (parse '(lambda (x) x)) #(lambda x #(varref x)) > (unparse (parse '((lambda (x) x) 42))) ((lambda (x) x) 42)Play around with parse and unparse. Try to parse various expressions until you figure out just what is legal syntax in this mini-language. You need not hand in anything for this exercise. However, you should play enough with parse and unparse that you understand them well. You should be able to make sense of that strange #3(... notation. Can you predict what will happen if you try to parse the application of a function of 2? Try to make up other predict/test examples of your own. The idea here is for you to take the time and really understand this parsing process. Ask your friendly lab instructor if you're unsure about any details here.
> (define g (parse '(lambda (x) (f x)))) > g #3(lambda x #3(app #2(varref f) #2(varref x))) > (unparse g) (lambda (x) (f x)) > (unparse (vector-ref g 2)) (f x) > (unparse (parse '(lambda (x) (lambda (t) (t ((lambda (x) p) z)))))) (lambda (x) (lambda (t) (t ((lambda (x) p) z))))
Here is an extension of the grammar used in this section:
<exp> ::= <number> lit (datum)
| <varref> varref (var)
| (if <exp> <exp> <exp>) if (test-exp then-exp else-exp)
| (lambda ({<var>}*) <exp>) lambda (formals body)
| (<exp> {<exp>}*) app (rator rands)
1. Write parse-2, a parser for this grammar.
> (parse-2 '(lambda (x) (+ x 2)))
#3(lambda (x) #3(app #2(varref +) (#2(varref x) #2(lit 2))))
> (parse-2 '(if (happy? me) (smile me) (frown me)))
#4(if
#3(app #2(varref happy?) (#2(varref me)))
#3(app #2(varref smile) (#2(varref me)))
#3(app #2(varref frown) (#2(varref me))))
> (parse-2 '( (lambda (x y z) (* x y (+ z 1))) 2 4 (expt 4 5)))
#3(app
#3(lambda
(x y z)
#3(app
#2(varref *)
(#2(varref x)
#2(varref y)
#3(app #2(varref +) (#2(varref z) #2(lit 1))))))
(#2(lit 2)
#2(lit 4)
#3(app #2(varref expt) (#2(lit 4) #2(lit 5)))))
2. Write unparse-2.
> (unparse-2 #3(lambda (x) #3(app #2(varref +) (#2(varref x) #2(lit 2)))))) (lambda (x) (+ x 2)) > (define g '( (lambda (x y z) (* x y (+ z 1))) 2 4 (expt 4 5)))) > g ((lambda (x y z) (* x y (+ z 1))) 2 4 (expt 4 5)) > (unparse-2 (parse-2 g)) ((lambda (x y z) (* x y (+ z 1))) 2 4 (expt 4 5))
It should be clear now that abstract syntax is not meant for human consumption. However, when writing a program that deals with syntax such as an interpreter, it is much easier to use a well thought out abstract syntax than to work directly with the concrete syntax.