L10: Design Patterns, Management, and Programming Languages
When designing software for a new system, developers should make an effort to reuse as much existing code as possible. For example, rather than writing your own linked list from scratch, check to see if there is an existing library (especially one supported by Oracle/Java) for this functionality, and use it instead, if possible. Existing libraries typically have a lot of implicit testing and debugging already done simply because so many people are already making use of that code.
Often, such as with these libraries, the precise functionality you need is readily available. Now that you know many of the OOP properties of inheritance, it’s also often possible to extend classes in these libraries to suit your own needs, for example, by overriding methods or using generics to specify the type stored in a container class. However, sometimes the module on concept that you want to implement is not a specific library class or method, but more of a concept.
For example, imagine that you have multiple threads trying to access a single object, such as a log list that collects all the logging information from this pool of threads. We want to ensure that there is only one log object in existance at any point in time, rather than these threads (or whoever spanned them) accidentally creating multiple logging objects. Remember, our goal is to maintain a single logging object to collect all logs from all threads. One way we could do this is to ensure that the constructor for the log object is only called once. While, in theory, this is something simple to do, it is much harder to enforce.
It turns out there is a desing pattern, called a singleton, which can solve our issue above. We’ll cover it below. The idea is there is a template and/or blueprint (as opposed to a specific class or library we would download) that developers can use as a guideline how to implement this desired functionality. The design pattern is a concept that provides a conceptual solution to a commonly-occuring software engineering problem, although templates/blueprints are available for these common design patterns.
Importance of Design Patterns
Design patterns are a useful way to incorporate best pratices and lessons learned for common object-oriented challenges. Design patterns have been around since the 1990s; the same time when Java and OOP became quite popular in common software development. Now, these are dozens of design pattersn that have been identified and made available, as templates. Design patterns, like Java libraries, are tools that have been used, debugging, and improved upon over decades and millions of use cases. Therefore, they’re excellent resources for writing better and more maintainable code.
Examples of Design Patterns
The initial set of design patterns was made avaiable in a book written by the “Gang of Four”. There are various patterns listed and explained there; more design patterns and resources can be found online.
Design patterns generally fall across three main categories:
- Structural: defines ways to combine classes and/or objects
- Behavioral: defines ways objects can communicate between one and another
- Creational: defines ways for objects to be created, that is, how and what types of objects needs to be created in what cases
Below are some examples from the categories above that we’ll cover in this class.
Singleton (creational design pattern)
Above, we illustrated a situation where it would make sense to ensure that an object only gets created once. In some sense, this is like creating a global, single resource for this item. We saw how that would make sense if conceptually it is important to have only one instace of something like a logger. It might also make sense (especially from a multithreading perspective) to have only a single object to access a database instance or a file system, as this may allow for better service and synchronization. There may also be other reasons to have a single object, for example, if it takes up a lot of memory, or a long time to create.
A singleton object gives you “global” access to that single object, rather than making multiple instances of that object. That is, rather than allowing developers to call the constructor to this object type multiple times (which would defeat the purpose because it would), the pattern enforces that a constructor for this “global” object is only actually called once, by essentially overriding the functionality of the constructor itself:
public class Singleton {
// This is a private member variable so that the singletonInstance
// can only be accessed through the getInstance() method.
private static Singleton singletonInstance;
// Private constructor forces the class to be instantiated
// via the getInstance method.
private Singleton() {
// private constructor
// set up the object here
}
// Method to get an instance of this class.
public static Singleton getInstance() {
// If this singleton instance is null,
// then construct a new instance.
// Otherwise return the existing instance.
if (singletonInstance == null) {
singletonInstance = new Singleton();
}
return singletonInstance;
}
}First, even though we’re looking at Java code, this class is not something developers would use or extend directly with extends; instead, they would define their own class (for example LoggerSingleton) and adapt it to that use case.
Note that the constructor is private; this restricts access such that no one else can call the constructor directly. The private constructor would be where you would set up the logger, connect to a database, or otherwise instantiate the actual object that you only want a single copy of.
Instead, people who want to get access to this singleton object must do so by calling the getInstance() method; this would conceptually replace the constructor call they would normally want to include in their code (recall, the constructor is private). The getInstance() method is public and static, so it can be called on the class itself, rather than any object of the class. You can see that it will check, if the private constructor has never been called (therefore the singletonInstance is null), it calls the constructor once and only once to instantiate the object. If the object already exists, the constructor is not called. In both cases, the reference to the object is then returned.
Note that we saw this example earlier in a worksheet, and, as written, it is not thread-safe because of this line: singletonInstance = new Singleton();. To make it thread-safe, you’d want to synchronize the method.
Here is what the Singleton design pattern could look like for reading in a very large file from a database one time:
public class LargeFile {
// This is a private member variable so that the file
// can only be accessed through the getInstance() method.
private static LargeFile singleton;
private static StringBuffer fileContents;
// Private constructor forces the class to be instantiated
// via the getInstance method.
private LargeFile() {
// private constructor
// set up the object here
fileContents = new StringBuffer();
try{
FileInputStream fstream = new FileInputStream("my_large_file.txt");
BufferedReader br = new BufferedReader(new InputStreamReader(fstream));
String strLine;
while ((strLine = br.readLine()) != null) {
fileContents.append(strLine);
}
fstream.close();
} catch (IOException e){
System.out.println("Sorry could not open your file.");
}
}
// Method to get an instance of this class.
public static LargeFile getInstance() {
// If this singleton instance is null,
// then construct a new instance.
// Otherwise return the existing instance.
if (singleton == null) {
singleton = new LargeFile();
}
return singleton;
}
}Factory (creational design pattern)
Another type of situation where we might want to control the creation of objects (like we did above) is when you have a conceptual hierarchy of objects that all have the same parent class, who’s creation needs to be managed. For exmaple, imagine that we have software that is responsible for generating accounts for new users of GWeb. These accounts are used by students, faculty, and staff at the school, but they each store different fields and have different functionality. Perhaps there is a GUI that an administrator uses to select which type of account needs to created.
In this case, if we set up an OOP hierarchy with GWebAccount as the abstract parent class, and children as StudentAccount, FacultyAccount, and StaffAccount, we can use these accounts interchangeably for any method expecting to deal with a GWebAccount. However, we would need to call each child class’ constructor specifically, depending on what type of account is being created. One could imagine the following type of code:
// note : this is NOT the Factory pattern below
String accountType = getAccountTypeFromGUI();
GWebAccount account = null;
switch(accountType){
case "student":
account = new StudentAccount(getFirstNameFromGUI(), getLastNameFromGUI(), ...);
break;
case "faculty":
account = new FacultyAccount(getFirstNameFromGUI(), getLastNameFromGUI(), ...);
break;
case "staff":
account = new StaffAccount(getFirstNameFromGUI(), getLastNameFromGUI(), ...);
break;
}This code is fine, but not really maintainable, because each time a new type of account is created, the switch statement needs to be updated. This is unfortunate, because the rest of this file (and code) shouldn’t care about what type of account was actually created, since the account variable is of the parent class’ type.
Instead, it would be nice if we could move this conditional logic into another location, where we can separate concerns and just rely on an object of the right type being delivered (again, where that type is specified). It turns out the Factory design pattern allows us to create objects of different types, based on input as long as those objects all maintain a specific class hierarchy. Here is the general template for a Factory:
public class ItemFactory {
public static Item getItem(String itemType, ...list of inputs that could be sent to parent class constuctor...){
switch(itemType){
case "student":
return new StudentAccount(...);
case "faculty":
return new FacultyAccount(...);
case "staff":
return new StaffAccount();
}
return null;
}
}And then we could call this static getItem() method on the ItemFactory class. Here is what this example would look like for the GWeb accounts:
public class AccountFactory {
public static GWebAccount getAccount(String type, String firstName, String lastName, ...){
switch(type){
case "student":
return new StudentAccount(firstName, lastName, ...);
case "faculty":
return new FacultyAccount(firstName, lastName, ...);
case "staff":
return new StaffAccount(firstName, lastName, ...);
}
return null;
}
}which would then be called in the original code as:
GWebAccount account = AccountFactory.getAccount(getAccountTypeFromGUI(), getFirstNameFromGUI(), getLastNameFromGUI(), ...);That’s much cleaner! While yes, we did basically just move the switch statement into our Factory pattern, this allows us to separate concerns because this GUI processing code (now one line) doesn’t actually care what kind of account is being created later on in the same method.
Adapter (structural design pattern)
The previous two design patterns allow developers to design elegant and robust solutions for situations that involve rules and requirements around creating objects. In other instances, we want to define how we can combine objects elegantly. Of course, Java already allows this, as a class will typically have its own fields.
One example of a desirable structure would be to have a classes that have separately implemented unrelated interfaces that can use this design pattern so they can work together successfully. The Adapter design pattern can be used as an object that joins these unrelated interfaces across two classes.
For example, imagine that we have a very nice implementation for mining data from scientific articles for information about penicillin. These articles were once converted into HTML (so they can be easily viewed on a webpage), and your code currently expects the articles to come in, in that format. The software will check to see if the word penicillin appears in the HTML title of the article and mines any experimental results from tabular data in the HTML file. So far, it works very nicely, as long as the articles being processed are in HTML format. The data might look like this:
<HTML>
<HEAD>
<TITLE>Penicillin saves millions of lives</TITLE>
</HEAD>
<BODY>
...
<TABLE>
<TR><TD>Penicillin experimental results</TD></TR>
...
</TABLE>
...
</BODY>
</HTML>However, imagine we obtained a bunch of different articles from a different server/journal that stored data in JSON format. Unfortunately for us, our current code won’t work because of the type mismatch. Take a look at how the same data might look in a JSON file:
{
"title":"Penicillin saves millions of lives",
... ,
"experimental_results": {...},
...
}What is there was a way to provide a wrapper around these JSON files that would allow them to be treated as HTML files, assuming we specify how to make that conversion? It turns out, this is what the Adapter design pattern is for. Specifically, we can conceptualize a way a JSON file could be converted to an HTML file, at least as far as the relevant pieces are concerned.
We can imagine what the Java code looks like to open and process each of these files is below. These methods allow the user to pull out the important pieces of these files, and later, check if what they returned contains the relevant keyword or not (not show below).
public class HTMLParser {
public static String getTitle() { ... }
public static String[] getTableCells() { ... }
}import JSON; // this is a lie
public class JSONParser {
public static String getTitle() { ... }
public static ArrayList<String> getExperiments() { ... }
}we can then define an Adapter class for the JSON processor to make it compatible with the HTML processor:
public class JSONParserAdapter extends HTMLParser {
private JSONParser json;
public JSONParserAdapter(JSONParser jsonIn){
json = jsonIn;
}
public static String getTitle() {
return json.getTitle();
}
public static String[] getTableCells() {
return json.getExperiments().toArray();
}
}Now, any code that was expecting to use an HTMLParser can also use the JSONParserAdapter in the same place, since the latter extends the former. Note that in the JSONParserAdapter we pass in the JSONParser object to the constructor; it is this object and its functionality that we’re essentially providing a wrapper around with the Adapter.
More on Design Patterns
The four examples above gave you a sense of when, how, and why Design Patterns can be useful in your own code. You’ll be using them in your subsequent courses here at GW, so make sure you understand what they are; not a library or code you would copy, but a template for good software engineering in your own projects.
Software Engineering Management
While our curriculum so far has focused a lot on learning how to code (in Java), it turns out that there is a lot more to writing software than just coding. In fact, developers often only spend ten percent of the time budgeted for a project on coding itself! Close to half the time might be spent on testing and debugging, while the remaining time is typically devoted to gathering requirements and designing the system. We’re going to focus on these two activities in this lecture. In general, the following activities typically happen, in this order, when developing software:
- Requirements gathering
- Requirements analysis and specification
- System design and planning
- Implementation (coding and unit testing)
- Integration and system testing
- Deployment and maintenance
While it is difficult to skip any of these steps for any large-scale system, we’ll see examples where the overall process is more iterative in nature, rather than the sequential set of steps implied above.
Gathering and specifying requirements
In your classes so far, it was probably rare for you to have to design your programs. In most cases, your professors detailed the requirements, either in English, or through unit tests (or some combination of both). In this course, each time you had to draw a UML diagram before writing your code, you were designing your solution. However, you likely haven’t had a chance to gather requirements and figure out what needs to be built, as opposed to how you’re going to build it (design).
Requirements gathering is arguably the most important and most difficult part of software engineering. Any requirement that is incorrectly captured – or isn’t captured at all – can cause signficiant headaches, rework, and financial loss later in the development lifecycle. Perhaps the worst outcome is that a piece of software is delivered that isn’t what the customer or the user even wanted! Fortunately, we have several decades worth of collective software engineering experience to help guide us on how to gather requirements more effectively.
What are software requirements?
First, let’s define what a requirement is: any functionality your system needs to implement. We can have both functional requirements such as the system must add two numbers together and show the result as well as non-functional requirements such as the system must query the database and return a result in less than 500ms. Let’s take a look at some example requirements from a very simple calculator:
- The user should be able to enter integers between -1,000,000,000 and 1,000,000,000
- The system should allow the user to add, subtract, multiply, or divide two numbers
- The system should allow the user to clear the previous results
- The system should have a display for the two numbers entered, the operation, and the result
Very quickly, we start to run into issues for even this simple calculator; * What should happen when the system divides by zero? * What should happen for overflow or underflow errors (such as multiplying together the two largest permissible inputs)?
We could convert some of those concerns above into additional requirements: * The system should print an error message and clear the inputs when it is unable to perform the specified operation
One important feature of all requirements is that they should be written so that the system either meets the requirement, or it doesn’t. For example, the four operations our calculator performs could be broken up into four separate requirements. Writing requirements this way makes it very easy to verify they’ve been completed during testing phases of our development lifecycle.
So far, these were all examples of functional requirements.
Non-functional requirements
In addition to functional requirements, it is often desirable (or legally required) to specify some constraints about how the system should operate. We often call these non-functional requirements, because they tend to capture more broad themes than a specific piece of functionality such as should allow the user to add two numbers together. These types of requirements address security, speed, operability, availability, safety, integrity, usability, and other -ity concerns not listed here.
An example of a non-functional requirement for our calculator above might be: Buttons to enter digits should have at least 16 point font as an example of a usability requirement (that is, making sure the font is large enough for individuals who may need larger lettering). Another important set of non-functional requirements often relate to the usability of the system. For example, will the font be large enough for everyone to read? Does the website layout and widgets match common conventions, so it is easy to use? There may even be legal requirements for usability, such as 508 compliance, that developers will have to manage.
The line between functional and non-functional requirements can be blurry – this is okay. Just remember that all requirements need to be testable.
Use Cases for requirements gathering
While it is relatively easy to understand what a requirement is, it is much more difficult to generate them. Requirements must be clear, complete, and consistent. They also need to be verifiable, that is, they should be able to be used as test cases: you either met the requirement, or you didn’t. But knowing what exactly needs to be designed and delivered to customers or users (and these are often not the same people, compounding the challenges of effective requirements specification) is extremely difficult. And, when things go wrong with missing, incomplete, or incorrect requirements, these errors are very expensive to fix during the coding testing part of the software design lifecycle (or worse, after deployment).
Therefore, we’d like a user-friendly way to capture and perhaps flesh out requirements that make this process of getting everything right more feasible and tractable. One way to do this is to use use cases, which capture user-visible functionality for the system to be designed. Focusing on these user-visible components is a good place to start generating requirements for a new system. Each use case is meant to capture a discrete goal for the user.
Generating a use case diagram
You can view a very simple example of a use case diagram below:
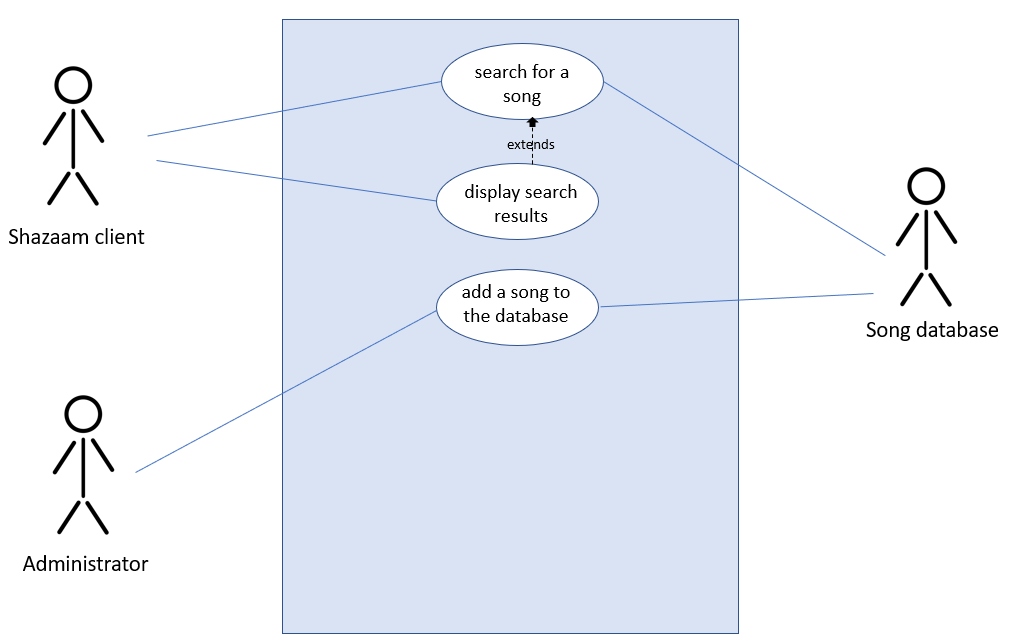
In this example, three actors (stick figured) are interacting with the Shazaam software we’re writing (blue box). There are three use cases shown, indicating one feature of the system we will need to design. Note that an actor does not always have to be a human or a single entity; the song database is an actor in our example.
Each use case is a bubble in such a diagram, and would also contain notes about the following (in a table):
- Overview: describes what the scenario is
- Notes: any relevant details for the scenario (optional for simple use cases)
- Actors: an explanation of each of the actors
- Preconditons: anything that has to be true before the use case starts
- Scenario: a table that contains a series of steps to complete the use case. Each step has an action (or stimulus) and a software reaction
Software Development Lifecycle models
Recall the steps of the software development lifecycle from earlier:
- Requirements gathering
- Requirements analysis and specification
- System design and planning
- Implementation (coding and unit testing)
- Integration and system testing
- Deployment and maintenance
We’ve now seen some ways to gather and specify requirements; the next step would then be to design and plan out the system using UML diagrams (for example) and various managerial planning tools (for example, to know what milestones need to be it every week/month).
Waterfall versus agile models for developing software
However, it turns out that such a sequential set of steps, that is requirements->design->coding->testing->deployment isn’t always the most efficient way to write code. Such an approach, called the waterfall model works best when it is possible to gather good and stable requirements upfront. In such cases, one could plan out the next several months of work, assuming each of the phases above can be completed without needing to change.
Unfortunately, it is often the case that we can’t gather good requirements up front. Our clients and customers may not know exactly what they want; it is hard to envision a system that doesn’t exist. The ecosystem of the software being developed may be rapidly changing, such as a mobile app meant to compete with other apps. Or, the system is so large that it might not be feasible to be able to effectively plan out all the details of every module and requirement up front.
In such cases, agile methods are more useful, compared to the waterfall approach. In an agile development process, only small pieces of the system are fully fleshed out at a time, and these often involve prototypes to gain client feedback on exactly what needs to be built. In other words, you could imagine a single use case being fleshed out over the course of a week, from requirements through testing. The following week, perhaps a different use case is completed.
Such an approach has the benefit of reducing the number of changes that need to be incorporated later in the development lifecycle due to missing or incorrect initial requirements. The downside with agile approaches is that because they are incremental in terms of what is being completed, the overall system that gets delivered may be less efficient than had it been holistically planned out in the first place.
Project planning
Whether you’re using a waterfall or agile approach for developing your software, you’ll need need to do some kind of planning in terms of:
- in what order components should be developed
- who is going to be responsible for building which components
- who developers and team members should turn to for leadership on the project
The critical path of a project defines an ordered set of components/requirements that, if any item on this path is delayed, will delay the entire project. Items on the critical path cannot be serialized, and there is therefore no slack in terms of their deliverable dates in order for a project to stay on time. Other items that could be developed in parallel (assuming you have enough resources) would likely have some slack with respect to the critical path; delay in their delivery might not cause the entire project to end up late.
A project manager is often used to plan out the timeline, milestones, and deliverables for a software project. This is a different role than the project lead who is responsible for motivating the team, creating a vision, and other emotional support and soft skills. For smaller projects they may be the same person.
Programming in Other Languages
One aspect of planning a project is to decide on what programming language to use.
Although this course has focused on the Java programming language to illustrate object oriented and software engineering concepts this semester, recently it has not been the most popular programming language people use (or that employers are looking for). Python is currently dominating.
Now that you know a decent amount of Java (and some C/C++ from your systems programming course), we are going to take a moment to wrap up the semester by discussing 1) when and why you would choose one programming language over another and 2) take a deep dive into OOP in python.
A little bit about python
Python is originally a scripting language, which means that it’s very easy and quick to write code in it. Compare the Hello World idiom in Java:
public class MyHWExample {
public static void main(String[] args){
System.out.println("Hello World!");
}
}to the same code in python:
print("Hello World!")Which do you want to code in?
So why are we “bothering” with Java? The answer is that Java has a lot more robust OOP features than python (which we’ll cover below), among other benefits. Sometimes, depending on what you want to program, using Java will result in fewer errors, easier to maintain code, etc.
What programming language should I use?
There is no “best” programming language; the best programming language for you to use depends on many things! Many of these are tradeoffs. We’ll review some of those considerations below.
Ease of use
We just saw how much quicker it is to write Hello World in python, versus Java. If you don’t need any of the benefits of a heavy-duty OOP language, like Java, in the programming project you’re working on, you can consider using python. Often, it’s quicker to write code in the latter: the designers of python included lots of syntactic sugar (i.e. shortcuts) to be able to write complex functionality in a single line of code:
print('#'.join(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])))The code above uses a single line to add a # between every integer in that list and turn the result into a string. In Java, it might look like this:
int[] array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
String arrayString = "";
for(int i = 0; i < array.length; i++)
arrayString += array[i] + "#";
System.out.println(arrayString);There’s a shorter way to do this in Java too, such as
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7);
String joinedList = list.stream().map(String::valueOf).collect(Collectors.joining("#"));But not only is that two lines of code – it is arguably a lot more confusing than the python version (for a novice), plus it requires knowing several libraries.
Even something as simple as adding an element to the end of an array is different between these two languages, in terms of syntax. For example, in python you might do:
intList = [1, 2, 3]
intList.append(4)Above, we can just call the append() method to add 4 to the intList in python. However, if we tried to mimic the code above in Java, it could look like:
int[] array = {1, 2, 3};
int[] newArray = new int [4];
for (int i = 0; i < array.length; i++)
newArray[i] = array[i];
newArray[array.length] = 4;This is because once you declare an array of a specific size, you can’t update that size. That’s probably one of the reasons we end up using ArrayList instead, but even that code isn’t so clean:
ArrayList<Integer> array = new ArrayList<Integer>();
array.add(1);
array.add(2);
array.add(3);
array.add(4);There is, once again, a shorter way to do this in Java, but one that is arguably still longer and less intelligible than in python:
int[] intArr = { 1, 2, 3};
List<Integer> list = Arrays.stream(intArr).boxed().collect(Collectors.toList());
list.add(4);Unlike Java, python also lets you return more than one item in a return statement. For example, you could write a method to return the min and max of a list, and call it as:
smallest, largest = getMinAndMax([3, 1, 4, 6, 33, 2, 76, 3, 8, 19])For more in-house details about the basics of python, you can check out CS 1012’s python tips.
Efficieny and utility of code
So far, it might always seem preferable to use python rather than Java. In part, that’s because we haven’t talked about OOP yet between these two languages. But the previous example regarding adding an element to the end of a list of integers didn’t touch on another important topic in choosing a programming language: runtime efficiency.
Although adding to the end of an ArrayList in Java is just as simple as doing the same in python (.add() versus .append()), what’s really going on under the hood?
In the ArrayList example above, it turns out that an ArrayList actually uses a primitive array to store the elements: this is not obvious to the user, and with good reason. We shouldn’t need to worry about the implementation level details of these classes…except when runtime efficiency might be called into question. For example, the ArrayList constructor could always create a primitve Java array with a size of ten, and then add to that as many times as the user wants, until it is full. When that happens and the user wants to add a new element, it might double the current size of the array, copy over the elements, and then add in the new one. That step is majorly inefficient! And the alternative: assigning huge empty arrays of thousands of elements is also wasteful.
If one really cared, at least using a primitve array in Java (as opposed to an ArrayList) makes these costs explicit. However, Java, compared to a language like C/C++, is not known for its runtime efficiency.
Runtime efficiency and predictability
Java is a high level programming language not only because it tends to read like English, but also because it simply doesn’t allow the user to directly access memory. While you can call a constructor, you don’t get to decide when an object that is no longer in use (because no variable points to it anymore) is freed: the garbage collector does this for you. For those of you that have programmed in C/C++, you probably appreciate Java’s garbage collection to no end: it frees developers of having to manually manage their own memory, and therefore, also obviates an entire class of errors: memory leaks and dereferecing invalid pointers. What’s not to love?!
It turns out, sometimes one needs to have fine-grained manual control over memory allocation and deallocation: Java is not the language for this. For instance, if you were writing code for an ultradependable system (i.e. something that could go into the control system of a nuclear power reactor), you need to be able to predict when certain code will run; garabage collection doesn’t allow you to do this. In fact, it’s not uncommon (at least in the past) that Java’s garbage collection would run at the worst time: when free memory was scarce because a program was using a lot of it to do a lot of computations, this is the exact time Java might pause the busy program to free up space. If things didn’t work out, this might look like the program was “hanging” to the user.
We don’t want the code in a nuclear power plant to appear to hang…so we can use a language like C to allow us to allocate and deallocate memory in a fine-grained, predictable fashion…but we also now have to be careful about memory leaks and dangling pointers. Always a tradeoff :-)
By allowing us to more directly manipulate memory, a language like C/C++, unlike Java and python, is useful for coding up things like operating systems. Being lower level with respect to this control around memory manipulation, a language like C/C++ is also useful for things that need to run quickly, like machine learning libraries that train large models on a GPU.
Ease of understanding
Runtime efficieny is often not the most important concern in a lot of modern programming. Compared to the 1980s, you have a lot of memory on your computers. Consider that the custom of having file extensions being three or four characters long came from needing to save memory back in the day; this number is otherwise arbitrary! In fact, runtime efficiency (i.e. C) often comes at the cost of the ease of writing and debugging code.
If being extremely memory efficient is not one of your concerns, one can argue that it’s much more important to write understandable and maintainable code, versus code that runs very fast on the CPU. For example, it turns out that function/method calls are relatively expensive, given that you need to add a stack frame to memory for the function call, set up the arguments, delete the frame when done, and then return to the previous stack frame. There’s someting called inlining that allows you to perform the same functionality without the explicit method call. For a basic example,
public String sum(int x, String y){
return x + y;
}
int x = 3;
String z = sum(x, "5");is always going to be more inefficient (in terms of memory and CPU cycles) than rewriting it without a function call:
int x = 3;
String z = x + "5";Fortunately, in this case the simple addition is also easier for a human to understand. Ironically, it’s easier to write in Java than in python:
x = 3
z = str(x) + "5" because we don’t need to manually convert x to be a String; Java does this for us with more syntactic sugar.
While Java is notoriously verbose, in general, compared to python (remember the number of lines it takes to print out Hello World), sometimes we can have too much of a good thing. For example, what do the lines of code below do?
[print(i+j,end=" ") for i,j in enumerate([x+int(x*1.5) for x in range(2,19)])]
print(":)")First, you get a different result if you run this in the python interpreter, versus running it as a file (because a print statement in python actually returns None). If you run each line above, individually, you get a different answer than running them together. Gross! For the latter, the output is: 4 9 14 19 24 30 36 43 49 56 63 70 78 86 94 102 110 :)
Best of luck to you understanding how that happened if you’re a python novice. Here’s a more digestible way to write the same code:
result = ""
i = 0
for x in range(2, 19):
j = x + int(x**1.5)
result += str(i + j) + ' '
i += 1
print(result + ":-)")Which one is better depends on what you and your team finds more easy to understand; if you’re working with a lot of folks new to python, they’ll likely understand the latter much more easily. If it’s hard to read, it might be hard for you to read a year later if you look at your code, and it might be hard for a more novice programmer to understand who you have to work with in the future. If it’s short and dense, it might be easier to miss simple mistakes – did you catch the bug in the first version? (Hint: it was doing multiplication, not raising to a power).
Sometimes, well-meaning students try to write the most “efficient” code possible, at the expense of readability or comprehensibility. This kind of micro-efficiency, where these folks saving a few milliseconds of time when you run this code, but at what cost? It’s often better to write code that might take a tiny bit amount of more time to run (especially when no one will notice this…) than to write the most “efficient” code. The more legible and maintainable code is easier to debug.
For example, take a look at this entire Wikipedia article discussing the fast inverse square root, which was a good approximation for a necessary calculation used in rendering a video game from the late 1990s. Knowing how to take the inverse square root is useful for rendering graphics to compute angles of incidence, and simlute lighting (for example). We’re dealing with vectors here (because of 3D modeling), so the inverse square root formula is:
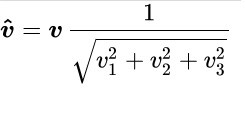
The three V-s represent vector coordinates. Here is what this code might look like in Java as a method for the inverse square root of a number:
public float Slow_rsqrt(float number){
return 1 / Math.sqrt(x); // expensive division operation!
}Usually, the inverse square root calculation, defined mathematically as 1 / sqrt(x) , was done using division operations of floating point numbers, but floating point division was very computatoinally expensive on the hardware (CPUs) back then. The fast inverse square root was a good approximation of this needed calculation and bypassed the expensive division step. Here is the code for the fast inverse square root algorithm (directly from the wiki above):
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;
}Wiki explains the code above as: “The algorithm accepts a 32-bit floating-point number as the input and stores a halved value for later use. Then, treating the bits representing the floating-point number as a 32-bit integer, a logical shift right by one bit is performed and the result subtracted from the number 0x5F3759DF, which is a floating-point representation of an approximation of sqrt(2^127).[3] This results in the first approximation of the inverse square root of the input. Treating the bits again as a floating-point number, it runs one iteration of Newton’s method, yielding a more precise approximation.”
Friends, we are doing all kinds of nastiness with, I kid you not, an actual magic number. Fortunately, the code above was eventually made obsolete when hardware manufacturers added new functionality to their CPUs. But before that, sometimes you had no choice but to sacrifice comprehensibility for efficiency. Even in modern times, there are certainly instances where runtime efficiency and memory efficiency are important, and you need to worry about them. One example are embedded systems, such as the code running on very limited battery power and memory space in something like a remote sensor. Training a memory- and power-hungry LLM on such a tiny remote sensor is all but hopeless. In these cases, it’s wise to potentially sacrifice some comprehensibility to meet the efficiency requirements.
Compiled versus interpreted code.
Speaking of runtime efficiency, the compiler is often your friend. Compiled code generally executes faster than interpreted code, but why? In both scenarios, we are translating the high-level language (Java, python, etc) into, ultimately, machine-level instructions (i.e. 64-bit sequences of zeroes and ones that are fed directly into the CPU via registers). In interpreted code, the python program, for example, will read python instructions line-by-line (on the fly) and translate these “individually” into machine instructions.
This works, but it’s not as efficient as if the computer was allowed to see the entire program as a whole, analyze it, and optimize the machine-level instructions it wants to run on the CPU (or, in the case of Java, the low-level bytecode that is later translated into machine code). In a compiled language like Java, looking at all the code together, rather than just translating it line-by-line, can result in faster running code. For example, a compiler can do things like branch prediction and loop unrolling that we won’t get into here, but make the code that actually runs on the hardware need fewer instructions. We can’t really do certain kinds of speed optimizations without a compiler.
But, again, why do we care about speed in the modern computing era? Well, there are instances, similar to the horror of the fast inverse square root algorithm above, where even a small mathematical operation, when done billions of times, can become expensive overall. There’s a reason we don’t write machine learning libraries that train deep learning models in Java :-)
Ease of debugging
Compiled languages, in addition to often being more efficient on the CPU than interpreted languages, are also often easier to debug.
Static typing vs dynamic typing
Putting execution speed aside for a moment, there are other advantages related to compilation that come into play when choosing a programming language: whether your language is statically or dynamically typed. Statically types languages, like Java, force you to declare your types at compile time. While this is more verbose, it does allow the compiler to catch type mismatches before you are ever allowed to run your code.
By contrast, in a dynamically typed language like python, the type of an assignment is determined at runtime. If I do x = 5 then at that time x is an integer, while later if I do x = "yellow" then x becomes a string. Less typing for the developer and more flexibility – what’s not to love? It turns out that it is very easy to make mistakes in a language with dynamic typing. There is no compiler to keep you safe. For instance, if I’m working with fMRI data, which measures bloodflow in the brain and stores these values in a 3-dimensional array of voxels, it is very easy to forget if some method in a library I wrote months ago returns a 1D slice of this data, or a 2D slice of this data (or both!). Normally, in Java, the compiler would catch if you are assigning mis-matched types like this unintentionally, but python does not. An entire day wasted tracing down such a bug; ask me how I know.
However, writing code is python is still faster than Java, in part, because you don’t have to declare your types up front.
Popularity and support
In addition to all these tradeoff we just discussed, sometimes we end up using a language for a task simply because it’s popular. For instance, you will often see python used for deep learning (i.e. PyTorch, Tensorflow), at least at the everyday practictioner level. Recall the machine learning libraries actually doing the math to learn the weights in these large models are probably running C++/CUDA (Nvidia’s language for programming GPUs), which is much faster than python. But, python became popular for machine learning coding, probably, in part, because it’s very easy for people, especially non-CS majors, to learn how to code in it.
Java, another popular language, became a household name in the 1990s, in part, because it can be used to make GUIs with its object-oriented support. C/C++, on the other hand, has been around for a longer time and is often used where performance and the ability to interface with memory at a lower level is important, like operating systems.
What other common languages are there that you might see in your career?
- Javascript: a language used for client-side web programming, and the source of endless nightmares and internet memes
- SQL: a programming language for querying relational database tables, and a potentially humbling experience for those of used to procedural languages
- C#: a language used to program for the .NET framework (runs on Microsoft Windows)
Python!
As you can see, python is currently perhaps the most popular programming language out there. We’ve already discussed some of its tradeoffs against a language like Java, but we haven’t talked about OOP in python. We’ll do that here as a great illustration of why to potentially use Java if OOP is important to you.
Object Oriented Programming in python
Python, like Java, does support the definition of classes and subsequent creation of objects. For example, here is what a person class might look like in Java:
public class Person {
private String name;
private int age;
public Person(String name, int age){
this.name = name;
this.age = age;
}
public String toString(){
return name + " " + age;
}
public void sayHi(String other){
System.out.println("Hello " + other + ", my name is " + name);
}
}In python, this would get translated to:
class Person:
def __init__(self, name, age):
self.__name = name
self.__age = age
def __str__(self):
return self.__name + " " + self.__age
def sayHi(self, other):
print("Hello " + other + ", my name is " + self.__name)So far, so good; despite some minor differences in syntax, both classes have private visibility (indicated by __ in python fields) and give us a constructor and toString(). But all is not as it seems! It turns out that the __ is just a convention in python, and there is nothing preventing someone from accessing this “private” field anyway:
vinesh = Person("Vinesh", 33)
vinesh.__age = -2 # doom!It gets worse. Python doesn’t have proper support for static fields; if we wanted to have a static planet field in Person, we might do:
class Person:
planet = "Earth"
def __init__(self, name, age):
self.__name = name
self.__age = age
def __str__(self):
return self.__name + " " + self.__age
def sayHi(self, other):
print("Hello " + other + ", my name is " + self.__name)but then you’ll find this kind of behavior:
vinesh = Person("Vinesh", 33)
lisa = Person("Lisa", 26)
print(vinesh.planet) # prints "Earth"
print(lisa.planet) # prints "Earth"
Person.planet = "Venus"
print(vinesh.planet) # prints "Venus"
print(lisa.planet) # prints "Venus"
vinesh.planet = "Mars"
print(vinesh.planet) # prints "Mars"
print(lisa.planet) # prints "Venus" # why?!?!?!??!We could continue on with even more OOP shortcomings in python compared to Java, but that’s left as an exercise to the reader. TLDR: if you would benefit from a solid OOP foundation where the compiler can perform all kinds of desirable checks for you, python is probably not the language for you.
But…DataFrames
Although we just said not to rely on OOP featurs if you’re using python, many people are using python to injest data for machine learning. For instance, a library called pandas has a class called a DataFrame which is the workhorse of many a machine learning application. A DataFrame acts like a really cool spreadsheet (think MSExcel) where you can do all kinds of things with it, including loading a csv into it and then passing its columns along to a machine learning model.