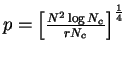VECTOR QUANTIZATION
Abdou Youssef
-
Background and Motivation
-
The Main Technique of VQ
-
VQ Issues
-
Sizes of Codebooks and Codevectors
-
Codevector Size Optimization
-
Construction of Codebooks
(The Linde-Buzo-Gray Algorithm)
-
Initial Codebook
-
Codebook Structure (m-ary Trees)
-
Advanced VQ
Back to Top
1. Background and Motivation
- Scalar quantization is insensitive to inter-pixel correlations
- Scalar quantization not only fails to exploit correlations, it also
destroys them, thus hurting the image quality
- Therefore, quantizing correlated data requires alternative
quantization techniques that exploit and largely preserve correlations
- Vector quantization (VQ) is such a technique
- VQ is a generalization of scalar quantization: It quantizes vectors
(contiguous blocks) of pixels rather than individual pixels
- VQ can be used as a standalone compression technique operating directly on
the original data (images or sounds)
- VQ can also be used as the quantization stage of a general lossy compression
scheme, especially where the transform stage does not decorrelate
completely, such as in certain applications of wavelet transforms
Back to Top
2. The Main Technique of VQ
- Build a dictionary or ``visual alphabet'', called codebook,
of codevectors. Each codevector is a
(1D or 2D) block of n pixels
- Coding
- Partition the input into blocks (vectors) of n pixels
- For each vector u, search the codebook for the best matching
codevector û, and code u by the index of
û in the codebook
- Losslessly compress the indices
- Decoding (A simple table lookup)
- Losslessly decompress the indices
- Replace each index i by codevector i of the codebook
- The codebook has to be stored/transmitted
- The codebook can be generated on an image-per-image basis or a
class-per-class basis
Back to Top
3. VQ Issues
- Codebook size (# of codevectors) Nc
- Codevector size n
- Codebook construction: what codevectors to include?
- Codebook structure: for faster best-match searches
- Global or local codebooks: class- or image-oriented VQ?
Back to Top
4. Sizes of Codebooks and Codevectors
(Tradeoffs)
- A large codebook size Nc allows for representing more features,
leading to better reconstruction quality
- But a large Nc causes more storage and/or transmission
- A small Nc has the opposite effects
- Typical values for Nc: 27, 28, 29, 210, 211
- A larger codevector size n exploits inter-pixel correlations better
- But n should not be larger than the extent of spatial correlations
Back to Top
5. Codevector Size Optimization
Back to Top
6. Construction of Codebooks
(The Linde-Buzo-Gray Algorithm)
- Main idea
- Start with an initial codebook of Nc vectors;
- Form Nc classes from a set of training vectors:
put each training vector v in Class i if the
i-th initial codeword is the closest match to v;
Note: The training set is the set of all the blocks
of the image being compressed. For global codebooks,
the training set is the set of all the blocks of
a representative subset of images selected from
the class of images of the application.
- Repeatedly restructure the classes by computing the new
centroids of the recent classes, and then putting
each training v vector in the class of v's closest
new centroid;
- Stop when the total distortions (differences
between the training vectors and their centroids) ceases to
change much;
- Take the most recent centroids as the codebook.
- The algorithm in detail
- Start with a set of training vectors
and an initial code book Û1(1), Û2(1),
..., ÛNc(1). Initialize the iteration index k
to 1 and the initial distortion D(0) to infinity.
- For each training vector v, find the closest Ûi(l):
d(v,Ûi(k))=min{d(v,Ûk(k)) | k=1,2,...,Nc}
where d(v,w) is the (Eucledian or MSE) distance between
the vectors v and w.
- Compute the new total distortion D(k):
D(k) =
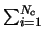 d(v,Ûi(k))
for all i=1,2,...,Nc and for all v in class i.
d(v,Ûi(k))
for all i=1,2,...,Nc and for all v in class i.
- If |(D(k-1)-D(k))/D(k-1)| < TOLERANCE,
the convergence is reached; stop and take
the most recent Û1(k), Û2(k),...,
ÛNc(k) to be the codebook.
Otherwise, go to step 5.
- Compute the new class centroids (vector means):
$Ûi(k) :=
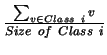
Back to Top
7. Initial Codebook
- Three methods for constructing an initial codebook
- The random method
- Pairwise Nearest Neighbor Clustering
- Splitting
- The random method:
- Choose randomly Nc vectors from the training set
- Pairwise Nearest Neighbor Clustering:
- Form each training vector into a cluster
- Repeat the following until the number of clusters becomes Nc:
merge the 2
clusters whose centroids are the closest to one another,
and recompute their new centroid
- Take the centroids of the Nc clusters as the initial codebook
- Splitting
- Compute the centroid X1 of the training set
- Perturb X1 to get X2, (e.g., X2=.99*X1)
- Apply LBG on the current initial codebook to get
an optimum codebook
- Perturb each codevector to double the size of the codebook
- Repeat step 3 and 4 until the number of codevectors reaches Nc
- In the end, the Nc codevectors are the whole desired codebook
Back to Top
8. Codebook Structure (m-ary Trees)
- Tree design and construction
- Start with codebook as the leaves
- Repeat until you construct the root
- cluster all the nodes of the current level into m-node
clusters
- create a parent node for each cluster of m nodes
- Searching for a best match of a vector v in the tree
- Search down the tree, always following the branch that
incurs the least MSE
- The search time is logarithmic (rather than linear) in the
codebook size
- Refined Trees
- Tapered trees: The number of children per node increases
as one moves down the tree
- Pruned Tress: Eliminate the codevectors that contribute little to
distortion reduction
Back to Top
9. Advanced VQ
- Prediction/Residual VQ
- Predict vectors
- compute the residual vectors,
- VQ-Code the residual vectors
- Mean/Residual VQ (M/R VQ)
- Compute the mean of each vector and subtract it from the vector
- VQ-code the residual vectors
- Code the means using DPCM and scalar quantization
- Remark: Once the means are subtracted from the vectors,
many vectors become very similar, thus requiring fewer
codevectors to represent them
- Interpolation/residual VQ (I/R VQ)
- subsample the image by choosing every l-th pixel
- code the subsampled image using scalar quantization
- Upsample the image using bilinear interpolation
- VQ-code the residual (original-upsampled) image
- remark: residuals have fewer variations, leading to smaller
codebooks
- Gain/Shape VQ (G/S VQ)
- Normalize all vectors to have unit gain (unit variance)
- Code the gains using scalar quantization
- VQ-code the normalized vectors
Back to Top
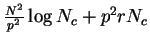
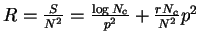
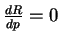
 , we have
, we have